前言
1.之所以坚持记录,是因为看到其他人写的优秀博客,内容准确详实,思路清晰流畅,这也说明了作者对知识的深入思考。我也希望能尽量将笔记写的准确、简洁,方便自己回忆也方便别人参考;
2.昨天看到两篇关于计算机视觉的发展介绍的文章:[观点|朱松纯:初探计算机视觉三个源头兼谈人工智能]、如何做好计算机视觉的研究[转]。
花了将近一个小时认真阅读,让我对自身思考问题的方式重新产生了思考:我在解决一个问题的时候,有没有想过它为什么发生?解决它有什么意义?有前人解决过这个问题吗?这个问题的解决思路有哪些?现在的研究趋势是什么?这种种的最基本、最重要的问题我却从来都没有思考过,也就是我对问题的思考深度和广度还远远不够,而只是想着如何快速借鉴别人的模型来完成训练并得到结果,而这种方式对于我的思考习惯却毫无用处,甚至十分危险!
学习内容
经典网络
上一篇文章中记录了卷积神经网络中的基础结构,如卷积层、池化层、全连接层和分类器softmax,这篇文章先讲讲卷积神经网络的第一个用途——分类。
LeNet-5
最经典、最远古的分类器(上古神器),也是其基础结构。该网络结构为:
卷积层——池化层——卷积层——池化层——全连接层——全连接层——分类器——概率输出
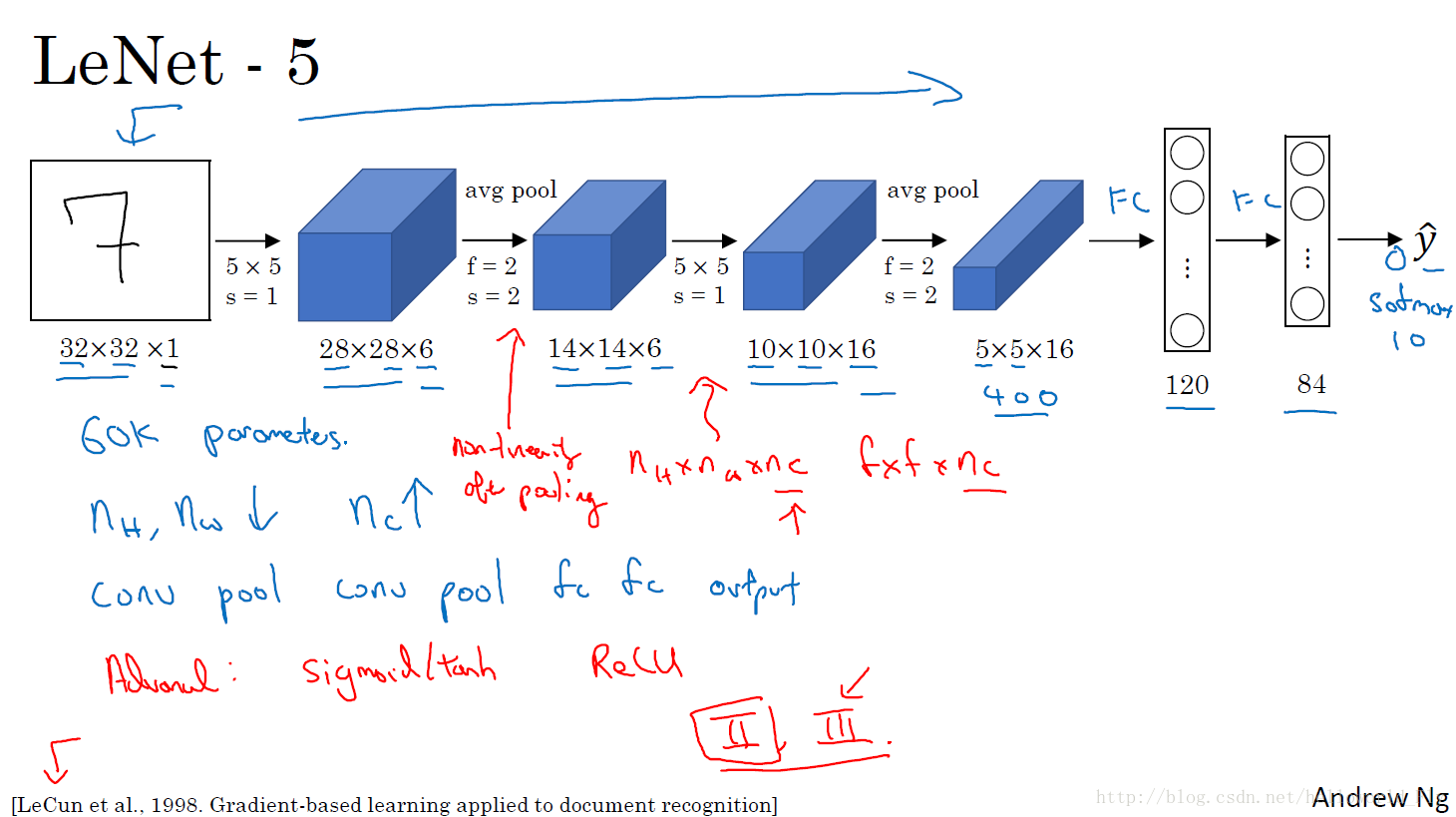
LeNet-5架构十分简单清晰,作为传统的经典网络,其思路是通过卷积操作和池化操作将原始输入特征用滤波器抓取并储存在通道之中。输出的宽度和高度都在减小,通道数在不断加深,作为识别黑白手写十种字体的目地,其效果不错。
不同之处:激活函数为sigmoid和tanh;过滤器使用的是5*5,过滤器个数由6个增加到16个; 使用的池化层为平均池化;参数60K。
AlexNet
AlexNet是进阶版,因为输入更加复杂,需要加入的卷积操作更多,需要记住的图像特征信息也更多。
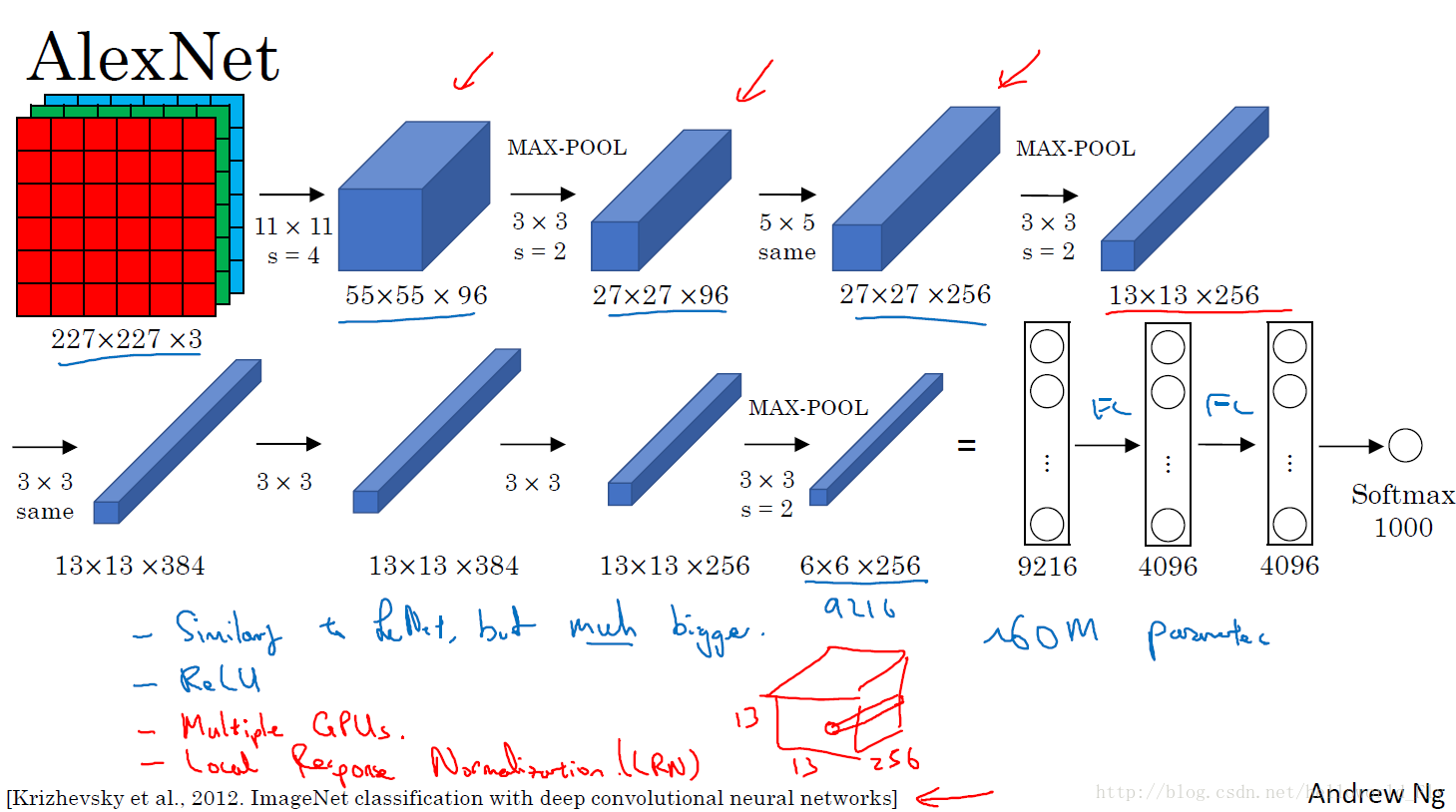
图中可以看到组成:卷积1—最大池化1—卷积same2—最大池化2—卷积same3—池化3—卷积same4—最大池化4—全分类1—全分类2—全分类3—分类器softmax
这张图中很详细的标明了其操作变化过程,相比Lenet-5的不同之处:
- 第一个过滤器尺寸较大:11 * 11,其后均为3 * 3或者5 * 5,网络更深
- 池化层加入了填充,padding=same,即池化后尺寸高度和宽度不变,仅调整通道数
- 使用激活函数Relu
- 参数个数增加至60million
- 使用了LRN,但是效果不太明显
VGG16
此网络还是比较适合个人实现和使用的,可以用tensorflow一步步实现,增加直观理解和提高编程能力,也能用于实际生活中的分类问题。
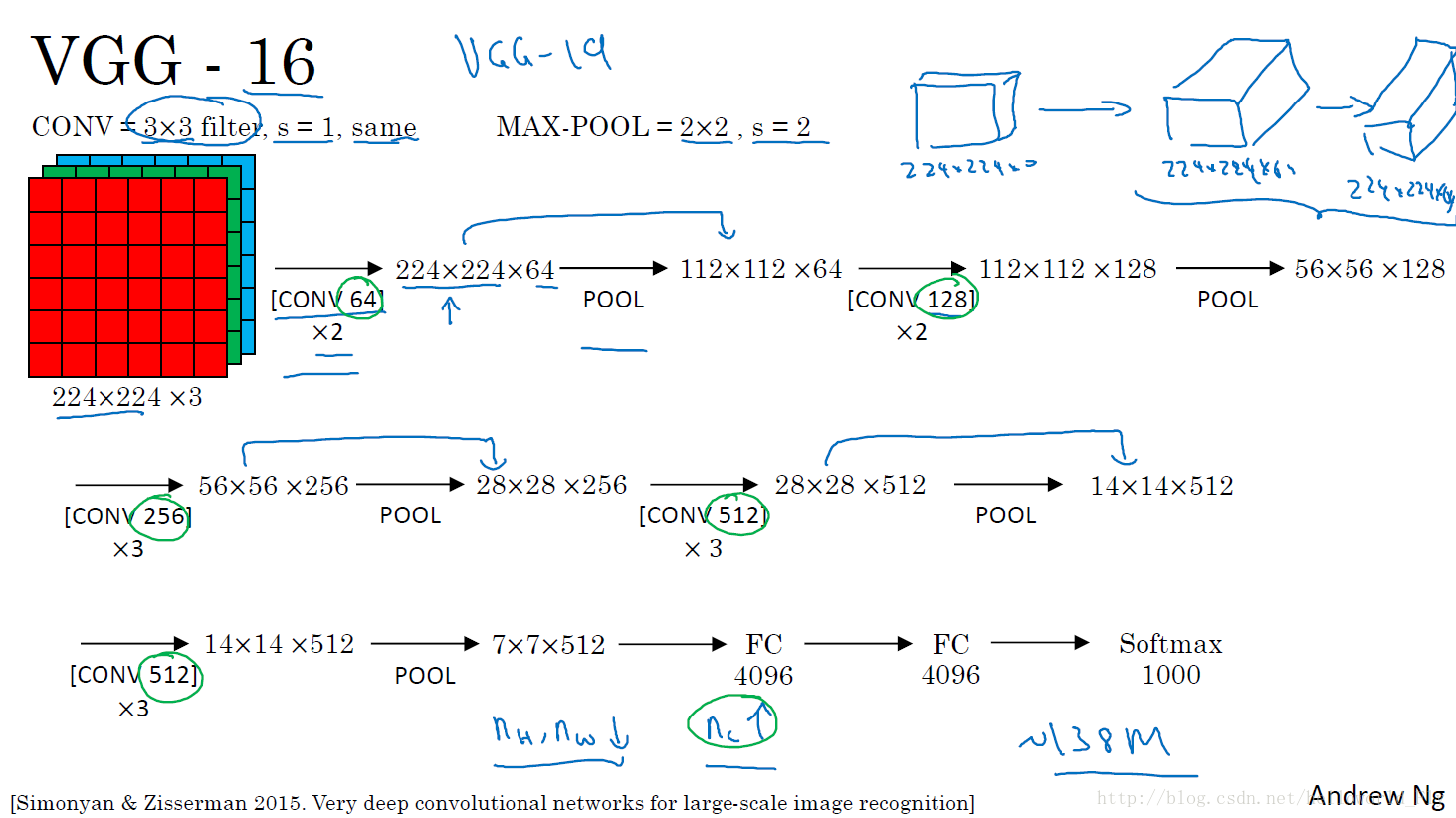
相比于AlexNet,VGG-16变得更加深入,在尝试了许多不同的模型之后,他们选择了16层的模型提供最好的效果,上图也很清楚的展现了卷积和池化过程,简而言之,让原始输入的高度和宽度变得越来越小,让其通道变得越来越深,最后全连接分类。
特点:
- 深度增加到16层,参数大量增加:138million
- 卷积层均使用的3*3,s=1和same,简便明了
Residual CNN
啰嗦半天,重点在接下来两个,ResCNN是2015年何恺明和孙健等提出模型,针对深度神经网络在网络结构变深之后梯度消失的问题提出了非常棒的解决方法。
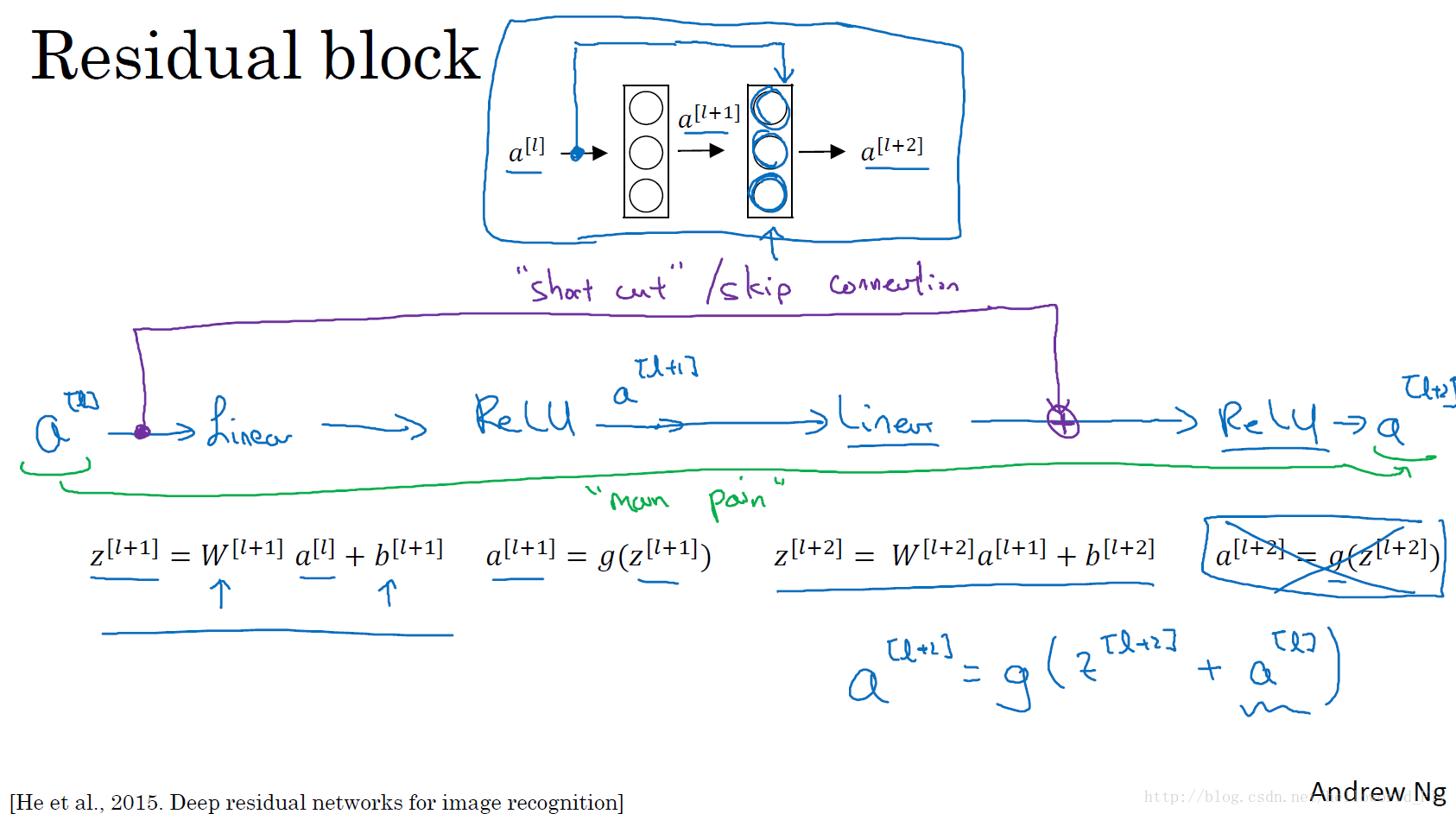
简而言之,大神的思路是将上一层输入结果通过额外增加一条shot cut“小路”直接传递给下一层的激活函数,也就意味着在下一层的激活函数不是g(z[l+2])而是g(z[l+2]+a[l]),这样一来,在回传过程中即使在常规路线上梯度消失,但还有shot cut存在,可以有效的提高训练速度和效率。
Inception
在介绍Inception之前还需要介绍下1*1卷积操作,示意图如下:

1*1卷积操作特点是保证输入的宽度和高度不变而调整其通道大小,可以有效减少计算参数
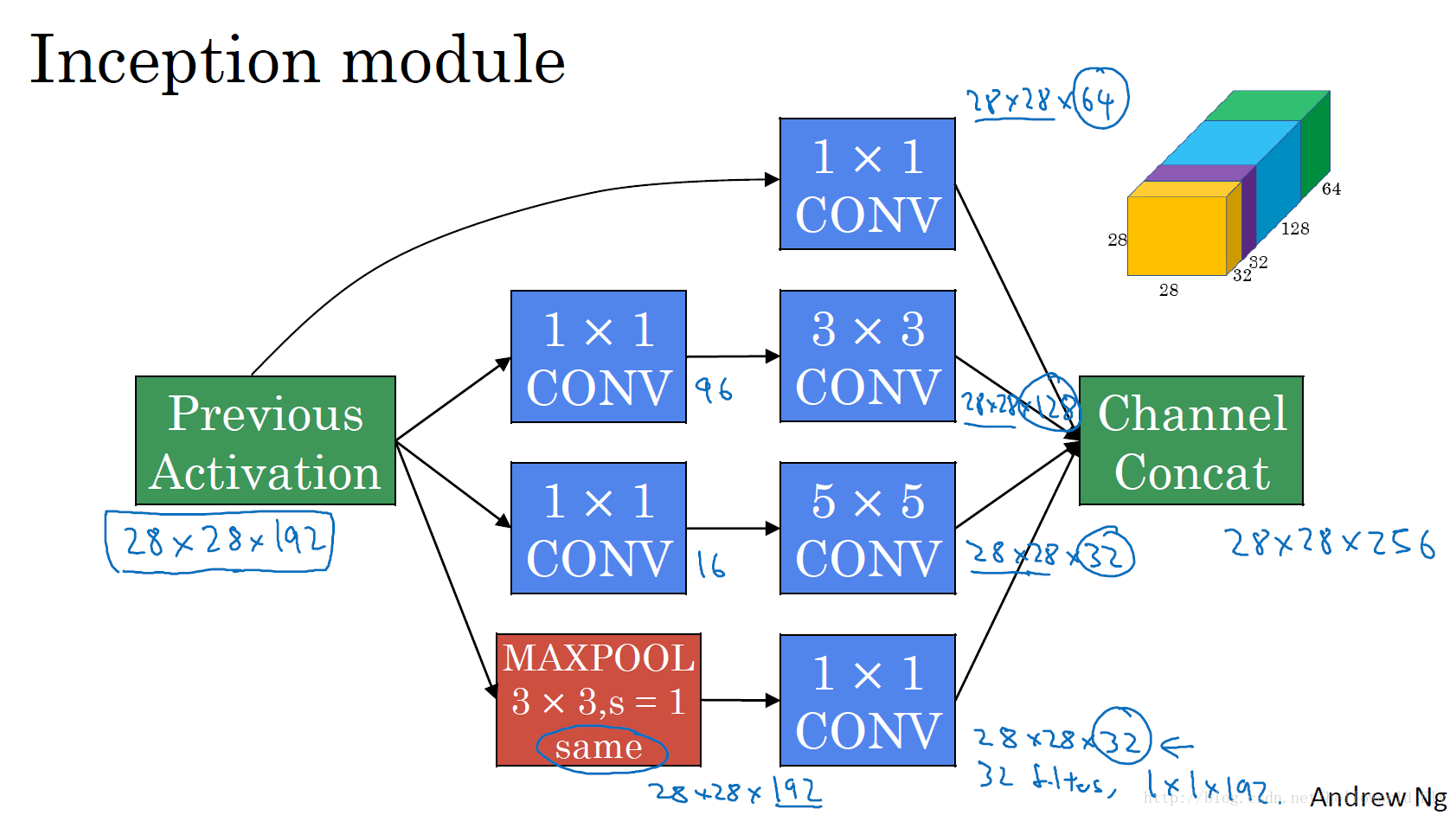
此为Inception模块的典型结构,区别于传统的单通道卷积结构,它使用的是多路径卷积的思想,可有效获取高度非线性特征,同时加入1* 1卷积可有效降低计算参数,图中已经标注了每个卷积转换后的输出,通过四个路径的结果叠加,最终将输入的28* 28* 192转换为28* 28*256。
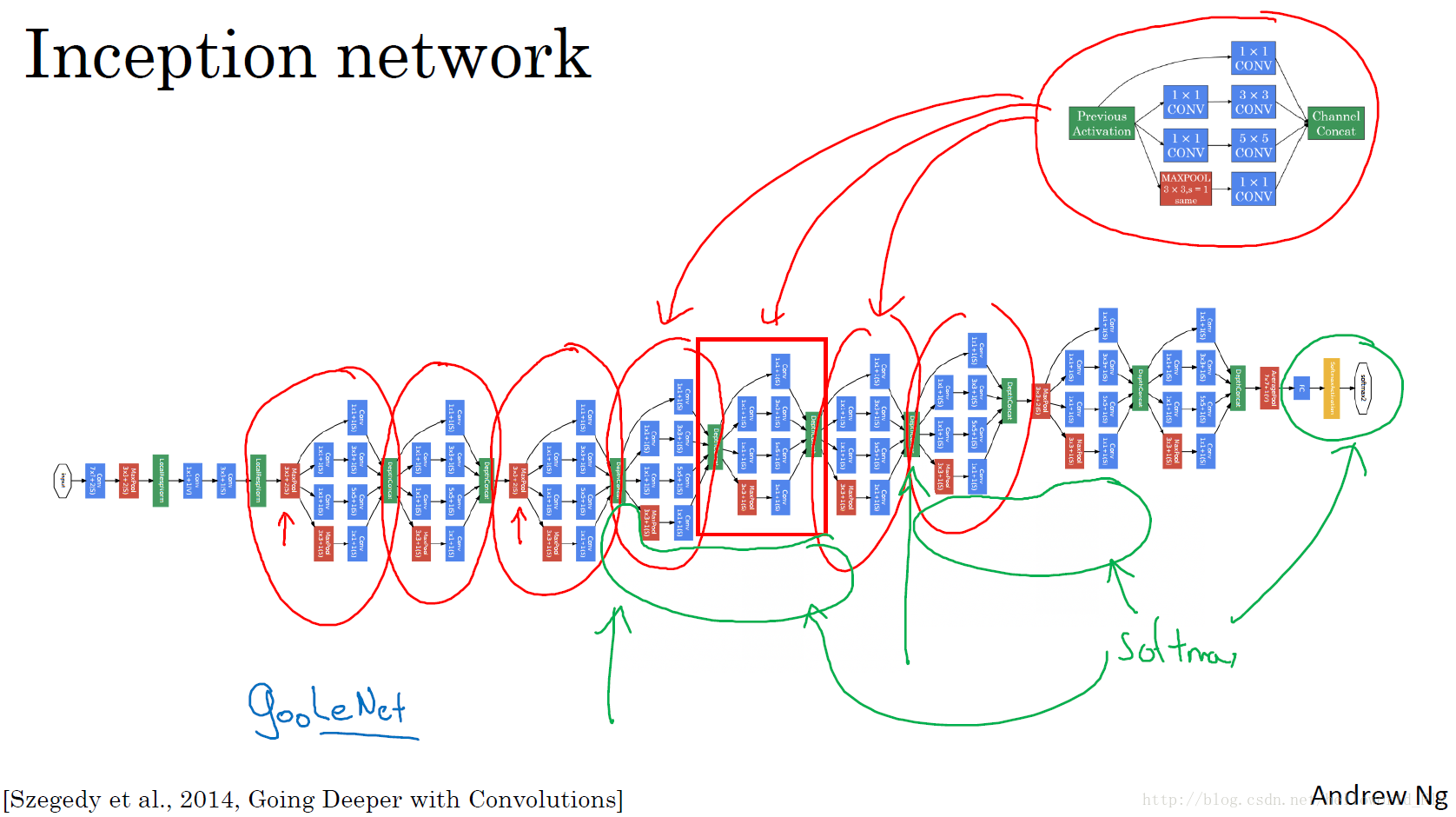
整体结构如图所示,先将输入卷积操作后输入3大块Inception模块,同时在其侧面和最后共有三个分类器,他们分别计算分类结果并去加权平方值,保证结果的准确性。GoogleNet共有四个进化版本,有兴趣可以进一步了解。
总结
1.经典模型:三大部件组成,网络深度逐渐增加,激活函数改变,但仍然很难达到超越人类的识别准确率;
2.进阶模型:残差网络在加入了shot cut之后,可有效地解决了反向传播梯度消失的问题,使得网络加深并保持稳定性能成为可能,且在imagenet比赛中,准确率超过人类3.5%错误率;
Inception网络利用了多路传播和1*1卷积,大幅度减少计算参数(减少10倍),大大提高训练速度,同时三个分类器也在一定程度上提高了结果的准确率。
回顾
卷积神经网络的根本任务是:建立性能良好且具有泛化能力的模型,通过训练模型参数来提高表现性能,模型深度越深,表达能力越强,但参数计算量大和梯度消失问题难以解决!
从经典神经网络到Resnet网络,都是在努力提高模型性能,但1998年的Letnet-5因计算能力和数据限制,只能建立相对简单的卷积网络;2012年的Alexnet和2015年的VGG16都是在有了一定数据和计算能力之后才开始逐步加深,但随着网络加深,出现了反向传播梯度消失和爆炸的问题,这就限制了网络的深度。
2015年提出的ResNet采用加入shot cut的思路保证了梯度顺利传播,有效解决了提出消失的问题,使得卷积神经网络的深度可以达到上百近千层,这也大大加强了卷积神经网络的表达能力,不仅仅是为图像分类问题,还有场景识别、人体骨骼点定位等提供了有力的架构支持。
当然,好的网络架构是必须的,还有更多的超参数调试优化技术逐渐加入,如BN、dropout、正则化L2等等,既能保证模型的高效训练,也能减少模型的过拟合问题,大大促进了卷积神经网络甚至是计算机视觉领域的发展!