欢迎访问https://blog.csdn.net/lxt_Lucia~~
宇宙第一小仙女\(^o^)/~~萌量爆表求带飞=≡Σ((( つ^o^)つ~ dalao们点个关注呗~~
一.LCA详解
转自:https://www.cnblogs.com/ECJTUACM-873284962/p/6613379.html
首先是最近公共祖先的概念(什么是最近公共祖先?):
在一棵没有环的树上,每个节点肯定有其父亲节点和祖先节点,而最近公共祖先,就是两个节点在这棵树上深度最大的公共的祖先节点。
换句话说,就是两个点在这棵树上距离最近的公共祖先节点。
所以LCA主要是用来处理当两个点仅有唯一一条确定的最短路径时的路径。
有人可能会问:那他本身或者其父亲节点是否可以作为祖先节点呢?
答案是肯定的,很简单,按照人的亲戚观念来说,你的父亲也是你的祖先,而LCA还可以将自己视为祖先节点。
举个例子吧,如下图所示4和5的最近公共祖先是2,5和3的最近公共祖先是1,2和1的最近公共祖先是1。 
这就是最近公共祖先的基本概念了,那么我们该如何去求这个最近公共祖先呢?
通常初学者都会想到最简单粗暴的一个办法:对于每个询问,遍历所有的点,时间复杂度为O(n*q),很明显,n和q一般不会很小。
常用的求LCA的算法有:Tarjan/DFS+ST/倍增
后两个算法都是在线算法,也很相似,时间复杂度在O(logn)~O(nlogn)之间,我个人认为较难理解。
有的题目是可以用线段树来做的,但是其代码量很大,时间复杂度也偏高,在O(n)~O(nlogn)之间,优点在于也是简单粗暴。
这篇博客主要是要介绍一下Tarjan算法(其实是我不会在线...)。
什么是Tarjan(离线)算法呢?顾名思义,就是在一次遍历中把所有询问一次性解决,所以其时间复杂度是O(n+q)。
Tarjan算法的优点在于相对稳定,时间复杂度也比较居中,也很容易理解。
下面详细介绍一下Tarjan算法的基本思路:
1.任选一个点为根节点,从根节点开始。
2.遍历该点u所有子节点v,并标记这些子节点v已被访问过。
3.若是v还有子节点,返回2,否则下一步。
4.合并v到u上。
5.寻找与当前点u有询问关系的点v。
6.若是v已经被访问过了,则可以确认u和v的最近公共祖先为v被合并到的父亲节点a。
遍历的话需要用到dfs来遍历(我相信来看的人都懂吧...),至于合并,最优化的方式就是利用并查集来合并两个节点。
下面上伪代码:
Tarjan(u)//marge和find为并查集合并函数和查找函数
{
for each(u,v) //访问所有u子节点v
{
Tarjan(v); //继续往下遍历
marge(u,v); //合并v到u上
标记v被访问过;
}
for each(u,e) //访问所有和u有询问关系的e
{
如果e被访问过;
u,e的最近公共祖先为find(e);
}
}
个人感觉这样还是有很多人不太理解,所以我打算模拟一遍给大家看。
建议拿着纸和笔跟着我的描述一起模拟!!
假设我们有一组数据 9个节点 8条边 联通情况如下:
1--2,1--3,2--4,2--5,3--6,5--7,5--8,7--9 即下图所示的树
设我们要查找最近公共祖先的点为9--8,4--6,7--5,5--3;
设f[ ]数组为并查集的父亲节点数组,初始化f [ i ] = i,vis[ ]数组为是否访问过的数组,初始为0; 
下面开始模拟过程:
取1为根节点,往下搜索发现有两个儿子2和3;
先搜2,发现2有两个儿子4和5,先搜索4,发现4没有子节点,则寻找与其有关系的点;
发现6与4有关系,但是vis[6]=0,即6还没被搜过,所以不操作;
发现没有和4有询问关系的点了,返回此前一次搜索,更新vis[4]=1;

表示4已经被搜完,更新f[4]=2,继续搜5,发现5有两个儿子7和8;
先搜7,发现7有一个子节点9,搜索9,发现没有子节点,寻找与其有关系的点;
发现8和9有关系,但是vis[8]=0,即8没被搜到过,所以不操作;
发现没有和9有询问关系的点了,返回此前一次搜索,更新vis[9]=1;
表示9已经被搜完,更新f[9]=7,发现7没有没被搜过的子节点了,寻找与其有关系的点;
发现5和7有关系,但是vis[5]=0,所以不操作;
发现没有和7有关系的点了,返回此前一次搜索,更新vis[7]=1;

表示7已经被搜完,更新f[7]=5,继续搜8,发现8没有子节点,则寻找与其有关系的点;
发现9与8有关系,此时vis[9]=1,则他们的最近公共祖先为find(9)=5;
(find(9)的顺序为f[9]=7-->f[7]=5-->f[5]=5 return 5;)
发现没有与8有关系的点了,返回此前一次搜索,更新vis[8]=1;
表示8已经被搜完,更新f[8]=5,发现5没有没搜过的子节点了,寻找与其有关系的点;

发现7和5有关系,此时vis[7]=1,所以他们的最近公共祖先为find(7)=5;
(find(7)的顺序为f[7]=5-->f[5]=5 return 5;)
又发现5和3有关系,但是vis[3]=0,所以不操作,此时5的子节点全部搜完了;
返回此前一次搜索,更新vis[5]=1,表示5已经被搜完,更新f[5]=2;
发现2没有未被搜完的子节点,寻找与其有关系的点;
又发现没有和2有关系的点,则此前一次搜索,更新vis[2]=1;

表示2已经被搜完,更新f[2]=1,继续搜3,发现3有一个子节点6;
搜索6,发现6没有子节点,则寻找与6有关系的点,发现4和6有关系;
此时vis[4]=1,所以它们的最近公共祖先为find(4)=1;
(find(4)的顺序为f[4]=2-->f[2]=2-->f[1]=1 return 1;)
发现没有与6有关系的点了,返回此前一次搜索,更新vis[6]=1,表示6已经被搜完了;

更新f[6]=3,发现3没有没被搜过的子节点了,则寻找与3有关系的点;
发现5和3有关系,此时vis[5]=1,则它们的最近公共祖先为find(5)=1;
(find(5)的顺序为f[5]=2-->f[2]=1-->f[1]=1 return 1;)
发现没有和3有关系的点了,返回此前一次搜索,更新vis[3]=1;

更新f[3]=1,发现1没有被搜过的子节点也没有有关系的点,此时可以退出整个dfs了。
经过这次dfs我们得出了所有的答案,有没有觉得很神奇呢?是否对Tarjan算法有更深层次的理解了呢?
二.Tarjan算法模板代码
转自“星博”:https://blog.csdn.net/Akatsuki__Itachi/article/details/81279173
模板题:Nearest Common Ancestors ( POJ1330 )
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 33678 | Accepted: 17093 |
Description
A rooted tree is a well-known data structure in computer science and engineering. An example is shown below: 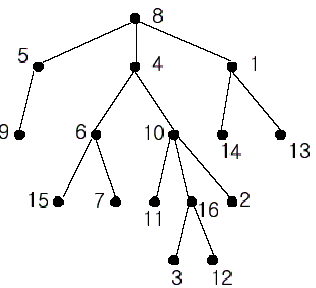
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
The input consists of T test cases. The number of test cases (T) is given in the first line of the input file. Each test case starts with a line containing an integer N , the number of nodes in a tree, 2<=N<=10,000. The nodes are labeled with integers 1, 2,..., N. Each of the next N -1 lines contains a pair of integers that represent an edge --the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N - 1 edges. The last line of each test case contains two distinct integers whose nearest common ancestor is to be computed.
Output
Print exactly one line for each test case. The line should contain the integer that is the nearest common ancestor.
Sample Input
2
16
1 14
8 5
10 16
5 9
4 6
8 4
4 10
1 13
6 15
10 11
6 7
10 2
16 3
8 1
16 12
16 7
5
2 3
3 4
3 1
1 5
3 5
Sample Output
4
3
Source
Taejon 2002
1.vector模拟邻接表:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<vector>
#include<queue>
#define eps 1e-8
#define memset(a,v) memset(a,v,sizeof(a))
using namespace std;
typedef long long int LL;
const int MAXL(1e4);
const int INF(0x7f7f7f7f);
const int mod(1e9+7);
int dir[4][2]= {{-1,0},{1,0},{0,1},{0,-1}};
int father[MAXL+50];
bool is_root[MAXL+50];
bool vis[MAXL+50];
vector<int>v[MAXL+50];
int root;
int cx,cy;
int ans;
int Find(int x)
{
if(x!=father[x])
father[x]=Find(father[x]);
return father[x];
}
void Join(int x,int y)
{
int fx=Find(x),fy=Find(y);
if(fx!=fy)
father[fy]=fx;
}
void LCA(int u)
{
for(int i=0; i<v[u].size(); i++)
{
int child=v[u][i];
if(!vis[child])
{
LCA(child);
Join(u,child);
vis[child]=true;
}
}
if(u==cx&&vis[cy]==true)
ans=Find(cy);
if(u==cy&&vis[cx]==true)
ans=Find(cx);
}
void init()
{
memset(is_root,true);
memset(vis,false);
int n;
scanf("%d",&n);
for(int i=0; i<=n; i++)
v[i].clear();
for(int i=1; i<=n; i++)
father[i]=i;
for(int i=1; i<n; i++)
{
int x,y;
scanf("%d%d",&x,&y);
v[x].push_back(y);
is_root[y]=false;
}
scanf("%d%d",&cx,&cy);
for(int i=1; i<=n; i++)
{
if(is_root[i]==true)
{
root=i;
break;
}
}
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
{
init();
LCA(root);
cout<<ans<<endl;
}
}2.链式前向星写法:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<vector>
#include<queue>
#define eps 1e-8
#define memset(a,v) memset(a,v,sizeof(a))
using namespace std;
typedef long long int LL;
const int MAXL(1e6);
const int INF(0x7f7f7f7f);
const int mod(1e9+7);
int dir[4][2]= {{-1,0},{1,0},{0,1},{0,-1}};
struct node
{
int to;
int next;
}edge[MAXL+50];
int head[MAXL+50];
int father[MAXL+50];
bool vis[MAXL+50];
bool is_root[MAXL+50];
int n;
int cnt;
int cx,cy;
int ans;
int root;
int Find(int x)
{
if(x!=father[x])
father[x]=Find(father[x]);
return father[x];
}
void Join(int x,int y)
{
int fx=Find(x),fy=Find(y);
if(fx!=fy)
father[fy]=fx;
}
void add_edge(int x,int y)
{
edge[cnt].to=y;
edge[cnt].next=head[x];
head[x]=cnt++;
}
void init()
{
cnt=0;
memset(head,-1);
memset(vis,false);
memset(is_root,true);
scanf("%d",&n);
for(int i=0;i<=n;i++)
father[i]=i;
for(int i=1;i<n;i++)
{
int x,y;
scanf("%d%d",&x,&y);
add_edge(x,y);
is_root[y]=false;
}
for(int i=1;i<=n;i++)
if(is_root[i]==true)
root=i;
}
void LCA(int u)
{
for(int i=head[u];~i;i=edge[i].next)
{
int v=edge[i].to;
LCA(v);
Join(u,v);
vis[v]=true;
}
if(cx==u&&vis[cy]==true)
ans=Find(cy);
if(cy==u&&vis[cx]==true)
ans=Find(cx);
}
void solve()
{
scanf("%d%d",&cx,&cy);
LCA(root);
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
{
init();
solve();
cout<<ans<<endl;
}
}