吴恩达(andrew ng),Geoff Hinton, Yann LeCun, Yoshua Bengio,Andrej Karpathy
ImageNet竞赛
michael nielsen(book),Andrew Ng(公开课)
Andrej Karpathy的CS231n课程笔记(卷积神经网络中的数学)
- 网络选择
情感分析等文本处理:RNTN(recurrent net,递归网络)
图像识别:深度信念网络(DBN)、卷积网络
物体识别:卷积网络,RNTN
语言识别:recurrent net
分类:MLP/RELU,deep belief net
时间序列分析:递归网络
反向传播,会碰到梯度消失和梯度爆炸问题,影响精度
需要计算损失值,不断调整权重
训练过程需要利用梯度,梯度衡量损失关于权重或者偏差的变化速率
梯度大,网络训练快
- 受限波尔兹曼机RBM
RBM浅层二层网络,第一层是可见层,第二层是隐含层,可见层每个节点与隐含层每个节点相连
等价与双向翻译机
RBM不需要标签
多轮前向和后向的传播计算,RBM能调节权重和偏差,重构输入数据
用KL离散值衡量损失,使输入值和重构值尽可能接近
特征抽取神经网络,发现重要特征
自编码器,对自身结构进行编码
抽取特征,重构输入数据——》处理梯度消失问题—深度信念网络
- 深度信念网络
反向传播的替代
DBM与MLP网络相似,训练不同
DBN可以看成是一堆RBM,前面顶RBM的隐含层是后面RBM的可见层
DBN的每一层都学习到了最原始的输入
DBN根据完整的输入,慢慢的更新整个模型
在初始训练之后,RBM能够检测数据的内在模式,需要用少量标签(有监督训练)
优势:精确
- 卷积神经网络CNN(监督学习,需要标签)
前面的网络层检测简单的模式,后面的网络层将其结合起来
人脸识别:前面的层用来检测边,后面的层用前几层的结果,形成面部特征
用CNN解决机器视觉项目
卷积层:
每个过滤器都是同一个过滤器,多个过滤器形成一个过滤器,过滤器能够判断图片中某个特定的模式是否存在,以及才存在的区域。实践中,不同的过滤器会同时照射在同一个点,它们会同时检测一组模式。若有四个过滤器搜索不同的模式,构成三维卷积网络(8×4×3)。
网路使用卷积操作搜索特定模式,过滤图片中的特定模式,权重和偏差会影响这个效果,每个手电筒(过滤器)代表一个CNN的一个神经元,每一层的神经元都会激活。另一方面,在卷积层,神经元会进行卷积操作。每一个神经元仅仅连接部分神经元。一个特定过滤器中的所有神经元,都共享相同的权重和偏差值。这意味着,在过滤器中,一个特定的神经元都连接了相同数量的输入神经元,并有相同的权重和偏差值,这使得过滤器能够在图片的不同部分寻找相同模式。
RELU和pooling层:
每一层都有利于构建卷积层发现的简单模式,卷积层与其他层连接,使用的激活函数叫做矫正线性单元(RELU)。RELU的数学定义,每一层的梯度差不多会是一个常量。RELU激活函数使得网络能够更好的训练,在前面重要的几层不会出现有害的梯度减小。
pooling层
池化层用于降维,为了构建更复杂的模式,CNN会把多个卷积层和RELU层堆起来,但是这样侦测出来的模型会变成非常大。池化层让网络能够关注到卷积层和RELU层发现的最重要且相关的模式
全关联层
这三种类型的网络层能够发现非常复杂的模式,但这些网络会不知道发现的模式具体表示什么,最后需要加一个全关联层,帮助网络对数据样本进行分类。
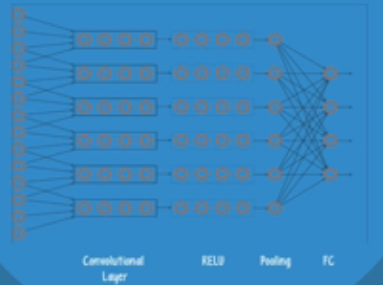
典型的深度CNN有三种类型的网络层,一个卷积层,一个RELU和一个池化层,每一层都会出现多次。这些层之后会带有一些全关联层来支持分类。
- 递归网络(recurrent nets)RNN
数据随时间变化,该模型有一个简单的反馈循环结构,使其成为一个预测引擎。RNN可以从应用到语音识别、无人驾驶
RNN中,前一层的输出会加入到下一层的输入,灌入到同一层,一般这都是整个网络中的唯一一层。一个回归网络可以接受一串值作为输入,也可以产生一串值作为输出,能够处理一串值的数据。
输入是单一值,输出是一串值,应用:图片说明
输入是一串值,输出是一个值,应用:文本分类任务
输入是一串值,输出是一串值,应用:对视频内容一帧帧分类
当延时机制引入后,这个网络可以用来预测供应链中的需求
将RNN堆叠起来,可以得到一个比单独RNN更复杂的输出。
反向传播会引起梯度消失问题
RNN很难训练,因为这些网络需要使用反向传播,这会遇到梯度消失。由于每次每个时间步骤的训练都相当于一个前向网络的一整层。训练100次前向网络,会引起非常小的梯度,信息也会随时间衰减掉。
解决:
gating units(LSTM,GRU):让网络选择忘记最近的输入,或者在之后的步骤中记得它。
gradient clipping(梯度建材)、steeper gates,better optimizers
用RNN而不是前向网络:前向网络输出一个值,在大多数情况下是一个类别或者一个预测值(分类、回归);RNN适合处理时间序列数据,输出值是序列中下一个值或之后几个值(预测)
- 自编码器:
应用标签时,能访问重要的数据特征是非常方便的,自编码器适合这类任务的神经网络。
受限玻尔兹曼机是自编码器的一个例子,其他:降噪自编码器和搜索编码器。
与RBM一样,一个自编码器接受一组无标签输入,对其进行编码之后,尝试精确的重构原始数据。最后的结果,网络必须决定哪些数据特征是最重要的,主要是作为一个特征抽取引擎。
自编码器一般十分浅,输入层+输出层+隐含层,RBM是一个只有两层的自编码器。
两步:编码步骤+解码步骤。隐含层编码特征的权重和输出层重构图片的权重一样。
自编码器用loss度量训练反向传播,与cost不一样,loss衡量了重构输入数据过程中有多少信息丢失,一个有少量loss的网络差不多可以重构出原始输入数据。
深度自编码器对于数据降维非常有用,深度自编码器能够将一张图片编码成30个数字,却能保留其关键图片特征。当解码输出时,网络如同双向翻译器。某些类型的网络会在编码解码过程中引入随机噪声,有助于提高最终模式的鲁棒性。
深度自编码器在降维方面表现比主成分分析(PCA)更好。
- 回归神经张量网络(recursive neural tensor nets, RNTN)
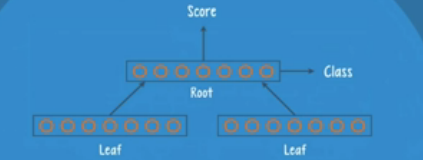
数据中有非常有用的层次结构信息,比如一些语句的解析树,在这种情况下RNTN比前向和递归网络更适合。RNTN的意图是去分析哪些含有层次结构信息的数据,普遍用于处理情感分析问题,一个句子的感情色彩不仅依赖于其组成单词,还和单词的句法顺序以及结合方面的信息有关
RNTN的结构:
RNTN有三个基本组成部分,一个叫父亲组,即根,另一个叫做孩子组,即叶子。每个组都有一系列的神经元,神经元的数量依赖于输入数据的复杂程度。根和叶子构成了二叉树。
叶子结点接收数据,根结点用分类器输出一个类别和分数。RNTN与递归网络一样,结构简单,但数据在网络中流动的过程非常复杂。RNTN的处理过程是递归的。
例子:将一个英语句子输入到这个网络,然后输出这个句子的解析树。第一部,把前两个单词分别输入到第一和第二个叶节点,叶节点实际上并不接受这些单词,而用向量表示单词。一个向量是一组有序的数字,神经网络对于某些特定的向量表示,效果很好。两个单词的向量表示越能反应这两个单词的相似度,那么神经网络的效果越好。这两个向量在网络中线上走到根节点处,根节点会处理这些值并输出一个类别和一个分数,分数代表了当前解析的质量,类别代表了这次解析结构的编码。进而到网络开始递归的时候。在下一步,第一个叶子节点获取当前解析的结果作为输入,而不是之前的单词。第二个叶子节点接收句子中的下一个单词作为输入,此时,根节点会输出这三个单词的解析分数,直到所有的输入单词用完后,这个网络得到包含每个单词的解析树。
实际应用,不一定会用第二个叶子节点去使用语句中的下一个单词,RNTN会使用之后的所有单词,最终输出的向量会代表整个子解析,通过在每个递归过程进行这一步处理,最后的深度网络就能解析出所有的语法树,并打分。
有三种常用的解析树,深度网络使用根节点输出的分数值来选择最好的那棵,在递归过程的每一步挑选分数最高的子结构,深度神经网络就产生了最高分数的解析树为其最终输出。当深度网络有了其最终输出结构,它可以回溯这棵解析树,来得到语句各个部分的正确文法标签。
它先处理第一个节点(The car),然后标记其为一个名词短语,然后作用到第二个节点,得到一个动词短语(is fast),然后继续往上,当它到达顶端,它会给一个特殊的标签标示解析树的开始。
RNTN用反向传播方法训练,会把预测的语句结构信息和已经标记好的正确的语句结构信息对比。一旦训练好,这个深度网络会给和它在训练中看到的解析树结构相似的输出结果更高的分数
RNTN在自然语言处理的语法解析和情感分析中有使用,当用于解析图像,主要是在一张图片中含有不同的场景时使用。
- 应用
机器视觉:
图像搜索系统使用深度学习:图片分类、自动标签
物体识别:根据图片中的物体搜索图片
Clarifai:通过使用卷积网络识别数字图像中的物体
视频解析:无人驾驶、远程
文本:抽取关系,机器翻译
情感分析:电影评分、产品介绍
Metamind:用RNTN进行twitter情感分析
递归网络在字符级别的文本处理和文本分类中应用
数字广告:根据用户购买力分段,个性化推荐,广告竞价
- 深度网络平台
软件平台、全平台
深度学习平台:为构建自己的深度网络提供一系列工具和接口
给用户提供一系列模型选择
集成不同数据源,操作数据,通过UI管理模型的工具
为训练一个巨大的数据集提供性能帮助
优点:能够通过UI直观的调整深度网络的超参数,开箱即用,不需要了解代码就能使用工具,可快速部署一个深度网络
缺点:深度网络的选择范围和配置选项的选择有限,没有几个平台能提供RNTN使用
Ersatz Labs(全平台)、H2O.ai(软件平台)、GraphaLab Create(软件平台)
H2O.ai:只提供多层感知机深度网络和机器学习算法,开源的机器学习平台,提供数据预处理,有非常精妙的数据加工处理能力,直观的模型管理界面,提供集成训练方法。其他支持机器学习的模型有广义线性模型、分布式随机森林、K-means、多个随机数集成的梯度加速机、cox比例风险模型、朴素贝叶斯分类器。反向传播的训练是使用L-BFGS算法
H2O集成HDF5、Amazon S3,SQL,和NoSQL。
H2O提供可下载的软件包,需要在硬件平台上部署和管理,平台提供基于内存的map-reduce功能,实现分布式的并行处理、基于列的压缩
Dato GraphLab:提供两种深度网络和一整套机器学习和图算法工具的软件平台,图分析(独一无二)
提供GraphLab图片数据:选择卷积网络;其他,选择多层感知机。提供文本分析、推荐系统、分类、回归、聚类
集成了数据库、Hadoop、Spark、Amazon S3、Pandas data frame和其他数据工。提供模型管理界面、可视化交互
GraphLab提供三个不同的开源存储类型:基于列表式的SArray、表存储模型的Sframe、图模型的SGraph,这些工具设计成能够快速处理TB级的数据分析,支持GPU
- 库
软件库提供了一些函数和模块,可以在代码中调用功能,深度网络库给了很多格外的模型选择余地,和超参数的配置方式。
商业级软件库:deeplearning4j、Torch、Caffe
教育或者科研:Theano,deepmat
- Theano
Theano是一个python编程语言库,能够用向量和矩阵来定义和运算数学表达式。向量和矩阵是一维或多维的数组,神经网络和输入数据都可以用矩阵进行标示,转化成矩阵的运算,计算机能快速实现矩阵操作,Theano能并行处理多个矩阵值,如果使用这种底层数据结构来实现神经网络,可以在合理的时间窗口内用GPU在单台机器上训练一个较大的神经网络。
需要手动编写神经网络的:模型、各层中的节点、激活函数、训练方法、避免过拟合的特殊方法。Theano能用向量化的函数来实现自己的神经网络。
扩展了Theano库功能的库:Block平台提供了封装。通过参数访问相应的函数;Lasagne package能基于Theano构建方便调整每一层超参数的神经网络;Keras,有最小的设计,能方便地一层层构建网络,训练,然后运行;Niche库适合做需要递归网络来完成的文本分析应用。
不提供分布式节点,不支持在Hadoop上用Theano训练深度网络
- Deeplearning4J

能够在分布式多节点环境中运行的商业级别深度学习库,用java编写,能够选择它的超参数来配置一个深度网络,提供分布式框架下的GPU支持。可以在scala和clojure语言平台上运行。
支持所有深度网络。DL4j包含向量化计算的库Canova。
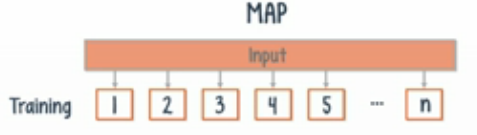
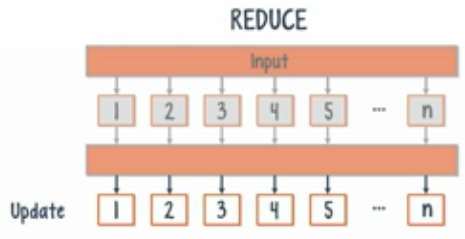
DL4j在分布式框架下训练机器学习模型:要求使用Iterative Map-Reduce的两步操作。在Map阶段,输入的数据会被分配到集群中的所有节点,每一个节点用它接收到的那部分数据训练神经网络。在Reduce阶段,集群中所有节点的权重和偏差会取平均值。网络中的每一个节点用这个平均值来作为其参数值。这两步会一直重复直到error变得足够小
传统的map-reduce:过程是顺序的,并且一次只能运行其中一步
- Torch
有大量扩展和大的社区支持的高质量深度学习库。Torch提供GPU支持,通过配置超参数来构建深度网络以及其他有用特性。Torch基于LuaJIT的库,LuaJIT是Lua编程语言的流行实现。该库提供了深度学习算法中相关数学的向量化实现。
扩展库:CUDA库(CuTorch)提供GPU支持;NN库能够使用不同网络架构;Cephes将Torch扩展成专有的数学计算库;DP库是使R&D过程流式化的深度学习库;NNgraph给NN库提供图工具的支持
- Caffe
机器视觉或者预测相关。可以构建自己的具有复杂层配置选项的深度网络。
初衷解决机器视觉问题,非常适合做卷积神经网络。最新版的Caffe库提供语音和文本、增强学习和递归网络。Caffe用C++编写,并使用CUDA。通过配置超参数,构建一个深度学习网络,然而,层次配置的参数非常复杂,可以用不同类型的层构建深度学习网络:视觉层、loss层、激活层。
Caffe有一个Model Zoo,在开发社区中的用户可以将其深度学习网络共享到这里,AlexNet和GoogleNet是这个社区较火的由用户共享的深度模型网络。
Caffe通过blob把输入数据向量化层特殊的数据表示形式,一个blob是一种能够在CPU和GPU平台上加速数据分析并且提供同步功能的数组。
- 拟合
训练一个模型时,遵守goldilocks原则。欠拟合/过拟合
解决欠拟合:增加能够区分样本的更多数据的特征
过拟合:输入的特征数量太多,或者模型的结构过于复杂,即每一层的节点和隐含层的层次数比实际需求多太多。过拟合会在权重和偏差中有所体现,训练过程中,神经网络分配不同权重给各个特征,这决定了特征的重要程度和结合方式,过拟合时,模型会给特征分配不需要的权重,造成过复杂的模式。
解决过拟合:划分数据集(训练集、测试集、交叉验证集),该方法与参数平均一起使用,确保模型不过于依赖整个数据集的某个部分子集;正则化,不同的类型,L1和L2,都遵循同一个通用原则,模型的权重和偏差太大的化,会受到惩罚;Max Norm Constraints:对权重或偏差直接加了一个大小的限制;dropout,随机关掉神经网络中某些特定神经元,阻止模型过于依赖某一组神经元,以及其关联的权重和偏差。
- TensorFlow
用python构建商业级深度学习应用的库
TensorFlow提高机器学习模型的可移植性。与Theano相似,TensorFlow基于计算图的概念构建,在一个计算图中,节点代表了可持续化的数据或者一个数学操作,图上的边代表了节点之间的数据流动,在边上流动(Flow)的数据是多维的数组,称之为张量(Tensor)。
一个操作或一系列操作的输出会作为下一步操作的输入,也可应用与数据流动图建模。
采用Theano的有用特性:自动求导、共享变量、符号变量、共有子表达式的消除。
Udacity上TensorFlow免费公开课
TF由发展规划图,细化了一下将来有用的特性,超参数的配置目前还没有。使用Keras超参数配置。
TF和Theano区别:TF支持并行,distributed TensorFlow,数据并行能在每一步的训练中,可以在不同的节点里训练数据的不同子集,之后会对整个集群中的节点进行参数平均及替换。支持模型并行化,模型的不同股部分会在不同的设备上并行训练。eg。使用模型并行化把每个RNN部署在不同设备上,训练stacked RNN。
支持GPU计算的新标准OpenCL
TensorBoard:能对网络架构和性能进行可视化展示,该工具能在训练过程中看到网络不同层的性能指标。
- 衡量metrics
性能测算指标叫做Error:分类错误的比例。缺陷:当个类别的数据不均衡时,
混淆矩阵
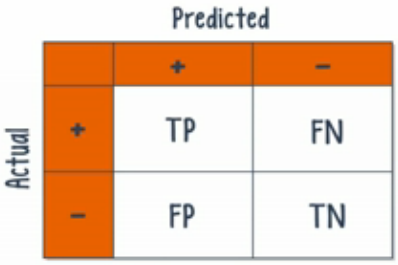
使用混淆矩阵,可以设计出解决error指标问题的新指标。
召回率(recall):positive样本被模型正确归类
精确率(precision):多少被预测为positive的是真正positive样本
精确率(precision)
的公式是

,它计算的是所有"正确被检索的item(TP)"占所有"实际被检索到的(TP+FP)"的比例.
召回率(recall)
的公式是

,它计算的是所有"正确被检索的item(TP)"占所有"应该检索到的item(TP+FN)"的比例
模型能够找回多少positive的样本,以及真正的预测有多精确。
准确率就是
找得对
,召回率就是
找得全
使用混合的衡量方法平衡准确率和召回率
F1:对准确率和召回率计算调合平均值,当有异常值时,比算术平均值有效,当特征值在0-1之间时,调和平均值对特征标准化很有用。
 ,即
,即

画图检测准确率和召回率,计算曲线下的面积,最大化这个面积的模型一般来说性能最佳。
多分类问题
- 性能(performance)
在使用CPU的情况下训练神经网络
1.用向量实现深度学习网络:向量代数,比如加法、点积,装置,都是可以并行处理的操作。以点积为例,每个乘法操作可以并行执行,最后的结果将会被加在一起。再硬件层实现的并行叫做并行处理,在软件层实现的并行叫并行编程。
并行处理分成:共享内存,分布式计算。
· 共享内存
GPU常用在训练过程,GPU支持并行处理
GPU的替代品时现场可编程逻辑门阵列(FPGA):是高可配置的,硬件,可以用于运行深度学习模型,并产生预测,运行大规模卷积网络。
特定电路集成电路(ASIC):设计在硬件和集成电路层级的,谷歌的Tensor Processing Unit(TPU),Nervana Systen芯片
· 分布式计算实现并行(数据并行、模型并行、流水线并行)
· 并行编程(Open HP公开课)
设计并行算法时,留意并行性,充分利用硬件并行能力。
3种并行化代码的方法
(1)将数据模型分解成几个chunk,每个chunk需要处理一个task,每一行代表数据的一个chunk,每个chunk之间是独立的,通过把数据组织成这种形式,每一行就能并行的作为输入

(2)发现有相互依赖的task,将它们分到同一组,通过创建多个组,每个组之间没有相互依赖性,就可并行处理这个最终任务。
(3)实现线程,每个线程处理不同task或task组,该方法能独自应用,与第二个方法结合使用效果更佳
- 深度学习中文本分析NLP
理解无结构的文本数据,标准的自然语言处理技术,深度学习更好
NLP:词性还原、命名体识别、语言词性标注,句法分析,事实提取、情感分析、机器翻译。这些方法依赖于语言模型能够计算在自然语言中出现某一部分的概率。以trigram模型为例,用来计算自然语言语料中三个连续单词串出现的概率。语言主观、模糊。
深度学习与传统NLP最大的区别是使用了向量,深度学习用one-hot向量代表一个词。每个词表示成了向量,向量的长度是整个词汇表的大小,除了对应于单词位置的值是1,向量中的所有其他值都是0,但若词汇表太大,该方法会失控。
降维能够解决one-hot向量的问题.
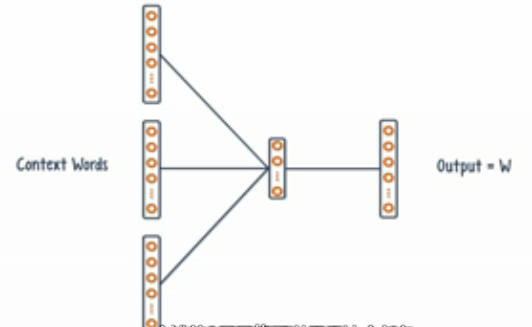
continuous bag of words(CBOW)模型为例,context作为特征来预测w,一个浅的3层网络可以用于这个任务,其中输入层是context单词的one-hot向量,输出层是需要预测的目标单词w
skip grams:能对给定单词,预测单词的context单词,因为仅目标单词作为输入,隐含层的输入会小很多,可以用隐含层的激活值作为目标单词的表示,而非原来长长的one-hot向量表示,降低里输入向量的维度
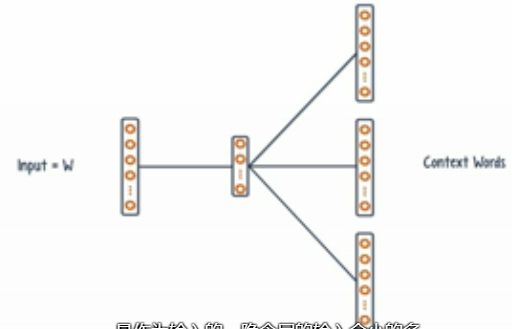
将单词转成向量的工具:Word2Vec和Glove
句法分析:用回归神经张量网络RNTN,一个RNTN包含了一个根节点以及两个叶节点,两个单词会作为输入分别传给两个叶节点,叶子结点将单词传给根节点,根节点处理这些单词,并产生一个中间解析以及一个分数,这个解析和句子中的下一个单词会输入给叶子节点,整个过程递归进行,直到句子中所有单词处理完。这个递归过程很复杂,在每一步递归过程中网络需要分析所有可能的子解析,而非仅是下一个单词。它能对所有可能的句法分析进行分析和算出分数。
机器翻译:一个递归网络可以接收一串输入和一个时间延迟,然后产生一串输出,一个训练良好的递归网络能够学习出内在的语法和不同语言之间的语义关系。当递归网络接收一个语言的一串单词,它可以产生另一个语言的相应一串单词。
在情感分析中使用RNTN,情感和语法在本质上有层次结构,且一个单词所在的位置会影响整个句子的意思。
- 配置网络
超参数是架构和训练方法的重要设计选择。一个选择是架构layers:选择每层网络的类型,输入层很直观,受限于应用和输入数据集;隐含层的选择类型(卷积,池化,激活和loss),卷积和池化油漆各自的子参数,分别由过滤器的数量和池化类型,有些网络还内置矩形操作;输出层,需指定网络的cost函数,可以是平方差的和、多分类中的交叉熵。
选择各层后。需指定每一层的神经元数:生长(growing)和剪枝(pruning),有用但计算量大。若计算资源有限,适合使用多一点的神经元,然后加入正则化防止过拟合。
激活函数:logistic单元(Sigmoid)、双曲正切函数和矫正线性单元(ReLU)。ReLU是使用back-prop训练时解决梯度消失问题的方法。这些激活函数都有变种,
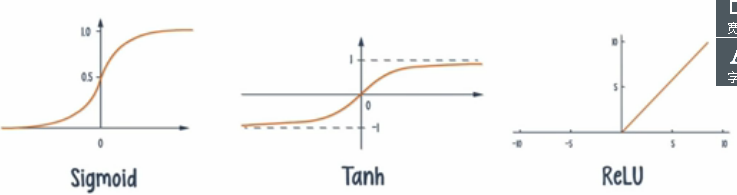
正则化:过度配置可能出现过拟合问题,当给一个过度配置的网络加上正则化,可以得到对新数据泛化不错的新模型,一个更多神经元的网络有更多的方法去结合其权重和偏差,造成的结果是,这个网络可以学习更多可能的模式,最终可能找到最低cost网络的权重和偏差组合
架构:若想自己建立递归网络,需考虑网络输入的内存大小,这决定了网络需记住多少过去的输入值。Gating单元,如GRU和LSTM,设计来帮助网络记住输入串中的不同部分,训练模型的成功依赖于参数的选择。xuexilv反向传播对学习率敏感,若学习率太大,容易忽略最小化整体cost的点;若学习率太小,训练过程需消耗大量时间,常用方法是随着训练的进行改变学习率的大小,通常学习率最开始的值比较大来加速性训练过程,随着训练进行,学习率逐渐变小。学习率改变策略:Adagrad、RMSprop、Adadelta
初始化:给权重和偏差赋值,最古老是随机值,DBN可以使用RMB的权重和偏差作为初始值,之后再进行监督学习,精调参数。使用RNN,可以用gradient clipping和steeper gates加速训练。
若网络性能还是不足,又别无他法,就提高训练的轮数(epoch),该策略对所有类型的深度学习网络有效。
- 迁移学习Transfer Learning with indico
Indico是一个基于云的深度学习服务,使用了迁移学习,通过迁移学习,他们的模型能够处理散乱的无结构化数据,将数据变得有效,迁移学习能将解决某个问题训练得到的模型,稍微修改就可用来解决其他问题,这因为深度神经网络学到很多层的特征,一旦训练良好,这些特征的知识对于解决相关问题非常有用。不需每次从头开始训练一个模型,可基于处理相似问题,提前训练好的模型来构建新模型,然后用自己的数据精调你的特征来解决自己的任务。不需要为每个不同的任务创建模型,可以使用其他任务的共同特征,再基于自己的数据精调模型
对于传统的机器学习,学到的特征都是手工写的,模型不会像深度学习模型那样自己搞清楚,迁移学习无法使用传统的机器学习特征。
Indico基于迁移学习,基于大量文本数据训练的,可对特定的自然语言处理任务精调这个接口,有了迁移学习后,只需很小的训练集就能获得不错的准确度,这个接口也在很多的图片上训练过。
- Neural Sturyteller with Somatic
是一个有趣的机器视觉项目,会观察一张数字图片,尝试基于其看到的东西,显现出一个简短的爱情故事
第一步,将图片作为输入提供给神经网络,在输出层产生描述这张图片的语句,递归网络可以进行图像文字说明,接收一张图片作为输入,产生一些串作为输出。这些图像文字说明的训练是从MSCOCO数据库中得到的。需要一种能够产生故事的机制,这故事能由图片中的每个元素发散出去。
第二步,开发一个skip-thought模型,可以以爱情故事的方式产生文本,一个类似的模型是skip-gram模型,它使用了一个目标词来预测它周边的单词(上下文)。图像的文字说明语料和爱情故事语料风格不一致,文字模式不一样,这些语言风格的词向量应该不一样
第三步,建立一个能把一种风格转换成另一种,把这两种语言风格连接起来,
Neural Sturyteller将预先构建好的深度学习模型开放使用,可通过接口访问模型,提供了大多数主流编程语言库,使用爱情小说数据训练的
- Inceptionism with Somatic
可以产生幻觉的神经网络,将卷积神经网络不同层的特征展现出来,通过把学习到的特征应用到不同图片。
面部识别:学习边和颜色对比度的特征,这些简单的特征组成更复杂的面部特征(眼睛鼻子),神经网络不需人工介入可在训练过程中学习出所有东西,神经网络会自主学习出每一层做什么,学习什么
Inceptionism搞清楚每个网络层学到什么特征,然后运用到其他图片上
深度网络可以用来生成数据,对一个输出,能产生一系列和它相关的输入,
CNN判别模型的权重和偏差可以用来产生图像,通过从网络中抽取学到的特征,然后运用到一张随机图片中,图片中相关的特定特征会被加强,模型会把特征加入到图片中,让图片看起来越来越像网络中学到的特征。对于迁移学习很有用
- reinforcement learning增强学习(监督学习)
目标是通过最大化数值回报来学习如何在不确定的环境中前行。
代理需要遵循一个原则,或一系列规则和策略,来最大化最终分数
若要构建一个自动代理,如何建模:代理的动作会影响环境的状态,一个模型需要把当前的状态和行为作为输入,产生最大化的预期回报作为输出,并进入下一个状态,并考虑从当前状态到最终状态之间的所有期望的回报,
DeepMind:Deep Atari ,输出不是一个类别,是一个能获得的最大回报分数,实际上在处理回归问题而非分类问题,没有使用池化层,因为不像图片识别,因为每一个位置都很重要,不能减少。一个递归网络也可被使用,只要修改其输出来处理回归问题,并把行为和环境状态作为每一步输入,
Deep Q-Network(DQN):使用这个原则,用当前的状态和行为来预测最大的回报值,
增强学习是监督学习一种,监督学习基于历史样本来理解环境,增强学习完全关注最好的回报,增强学习看重最优分数,强调当前的行为会改变状态,监督学习不会。
增强学习的代理可以在探索和开发中权衡,选择可以达到最大预期回报的路径。
深度增强学习设计目标设定,计划和感知等概念
- 概率编程
不是透过数据分析来得出神经网络,而是使用概率编程。概率编程是一种技术,以假设作为开端,然后使用数据来细化并完善。概率编程所走的高效路线,被认为是在机器上实现真正人类思考的关键。神经网络需要大量标记仔细的数据,但现实中是难以实现的。不过正如深度学习并不是实现人工智能的唯一方法,概率编程,高斯过程,进化计算,强化学习等方法都将继续发展壮大。概率程序设计使研究人员能够像编译器编写计算机程序一样创建机器学习算法。但是,该技术的真正价值在于它处理不确定性的能力。将不确定数据转化为价值数据进行学习,这允许AI学习时不依赖特定数据,同时也可以帮助研究人员了解在什么情况下AI会做出特定的决定;如果他们不同意这些决定,则更容易进行AI调整。
学习:线性代数、概率、统计学、机器学习、数学建模、数据结构、算法、分布式系统;不要忘记沟通、仔细思考、散文写作技巧、软件编写技巧、软件工程、韧性、堆栈溢出等更难的技能。