版权声明:本文为博主 http://blog.csdn.net/churximi 原创文章,未经允许不得转载,谢谢。 https://blog.csdn.net/churximi/article/details/79499897
毕业以后就没再写过博客,又想起来了。
Ps:本文只是个人笔记总结,没有大段的详细讲解,仅仅是将自己不熟悉和认为重要的东西总结下来,算是一个大纲,用的时候方便回忆和查找。
Ps2:部分笔记内容见图片。
相关课程内容
一、神经网络和深度学习
- 第一周 深度学习概论
- 第二周 神经网络基础
知识点总结
1. 神经网络
- 神经元:neuron
2. 房屋价格预测
- 若干输入特征→输出
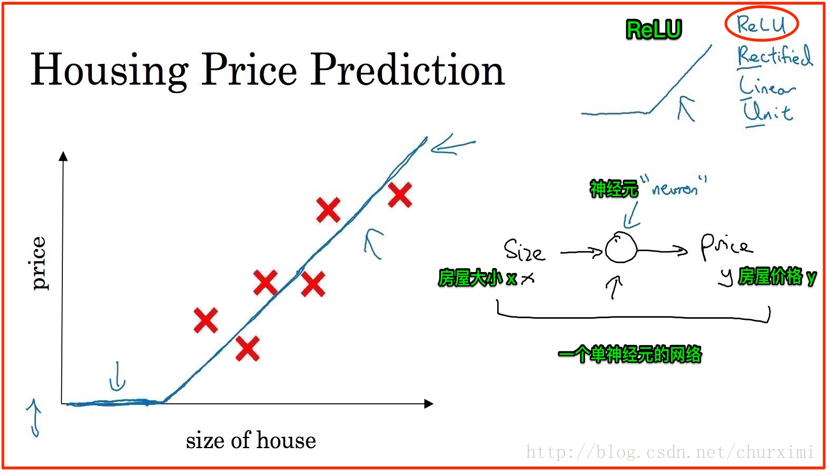
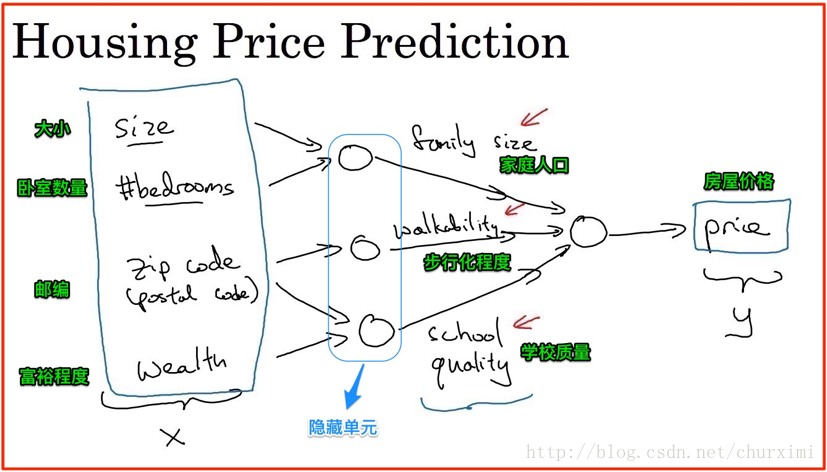
3. 标准神经网络
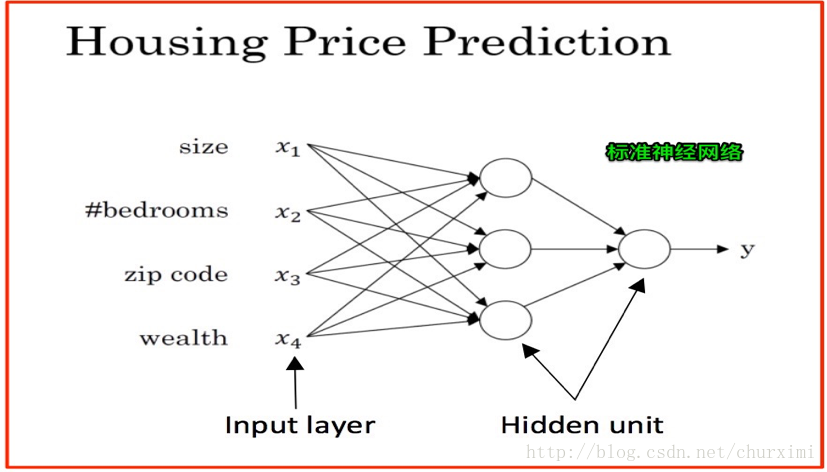
4. 猫的图像识别
- 二元分类
- 逻辑回归
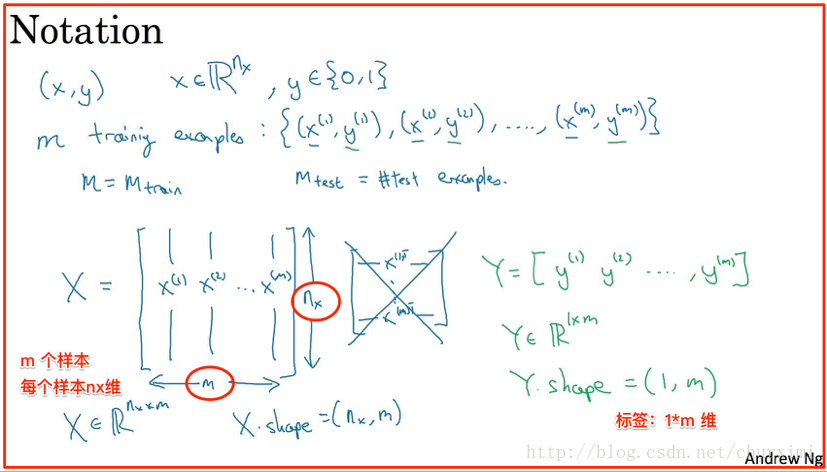
(1)图像表示/转换
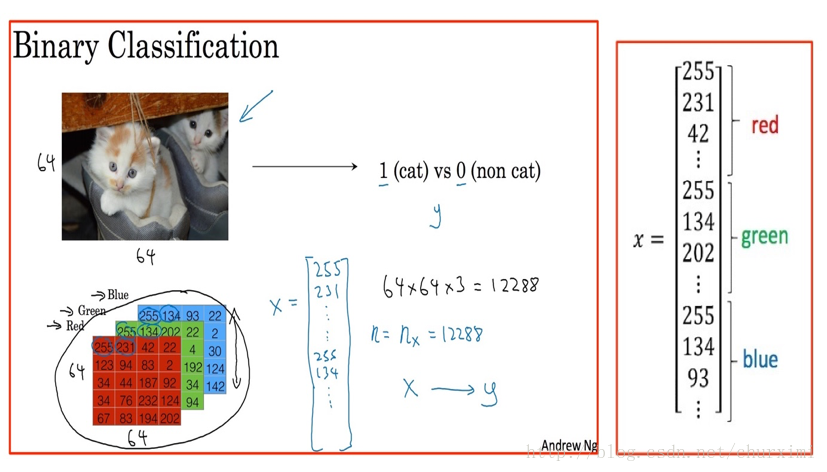
(2)数据集表示
- X维度:(n, m)
- Y维度:(1, m)
5. 激活函数

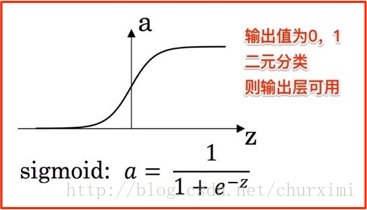
(1)Sigmoid函数(可以作二元分类输出层激活函数)及tanh函数
- 在Sigmoid函数和tanh函数(双曲正切)两端的斜率很小,梯度接近于0,在使用梯度下降法时,参数变化会非常缓慢,因此学习会变得非常缓慢。
- tanh函数通常比Sigmoid函数表现好。
(2)ReLU函数
- 对于所有的正值,斜率都为1。 大多数地方斜率远离0,能够使梯度下降法运行得更快。 缺点是左侧导数为0。
- 线性修正单元(Rectified Linear Unit),修正:取不小于0的值。
6. 成本函数(cost function)
- 衡量参数W和b在全部训练集上的效果。
- 成本函数是损失函数在全部训练集上的平均值。
- 成本函数计算公式如下:

7. 损失函数(Loss function)/误差函数(error function)
- 用于衡量单一训练样例预测输出值y_hat与实际值y的差距。
- 例如:误差平方可以用,但是不适合梯度下降法。

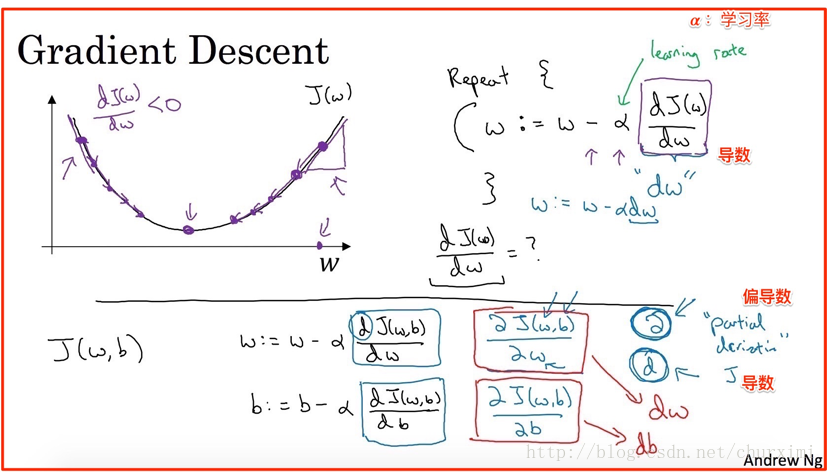
8. 梯度下降法(Gradient Descent)
我们需要找到能够使成本函数J(W, b)最小化的参数W和b。
(1)随机化一个初始点(例如全0)
(2)朝最陡的下坡方向走一步
(3)经过N次迭代后到达/接近全局最优解(global optimum)
- 凸函数(convex):
- 非凸函数(non-convex):有很多不同的局部最优

9. 导数
- 梯度下降法,需要计算成本函数J(W, b)对各个参数(W,b等)的导数。
正向计算:
计算损失函数L(a, y)对参数a,z,w,b的导数:
(1)★★★ da计算:
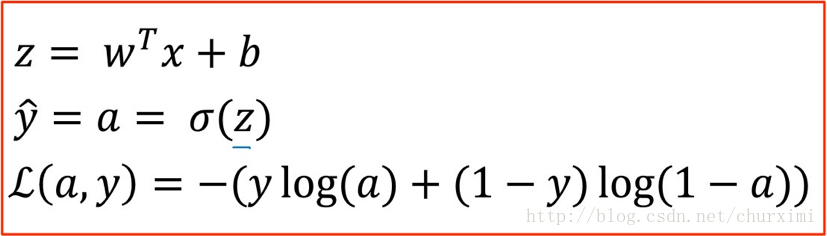
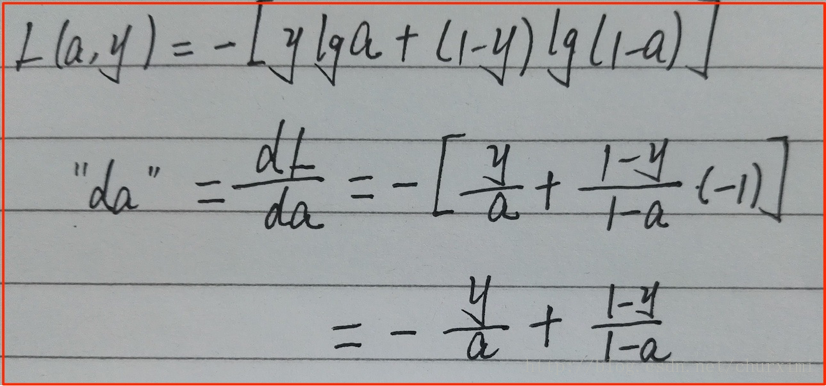
(2)★★★ dz计算:(结果为a-y)
- 链式法则:
- 【第一项】dL/da上面已经计算出来了
【第二项】da/dz即为激活函数求导
a的公式(Sigmoid函数):
sigmoid函数求导:
- 最终dz = 【第一项】·【第二项】= a - y
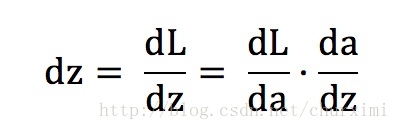

(3)★★★ dw,db计算:
- dw1 = x1 * dz
- dw2 = x2 * dz …
- dw = x * dz
- db = dz
10. 参数更新
- 最终da,dz,dw,db都能够通过x,y,a来计算。
- 学习率α:learning rate(新的参数)
- w1 = w1 - α*dw1
- w2 = w2 - α*dw2
- b = b - α*db

11. m个样本的梯度下降及向量化表示
- 成本函数 = sum(m个损失函数) / m
- dA,dZ,dW,db都能够通过X,Y,A来计算,其中(X, Y)有m个。
- 注意点:
(1)W的转置问题
(2)dW,db的计算要除以m取均值
(3)后续神经网络会有多层
12. 总结
- 公式不好输入,下面是图片
