中文技术博客上描述的反向传播算法有一些跳跃性非常大,对于理解神经网络乃至深度学习的过程非常不利,我在网上找到一篇Backpropagation 的推导过程实例(https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/),写得明白透彻,按照最典型的梯度下降算法来进行推导,现将学习过程记录如下。
1. loss 函数的优化
笼统来讲:
设计loss函数是为了衡量网络输出值和理想值之间的差距,尽管网络的直接输出并不显式的包含权重因子,但是输出是同权重因子直接相关的,因此仍然可以将loss函数视作在权重因子空间中的一个函数。
可以将loss 记为E(w),这里为了便于说明,省去了偏值项,正则项等等,仅仅将loss认为是w的函数,
训练网络:
对网络训练的目标在数学上的显示表现就是使得loss取值最小化,这个问题就变成了在权重空间w中求loss全局极值的一个优化问题,对于这种问题,通常的解决方案是对loss求w的偏导
2. 链式推导过程
假定如下图示的神经元结构:
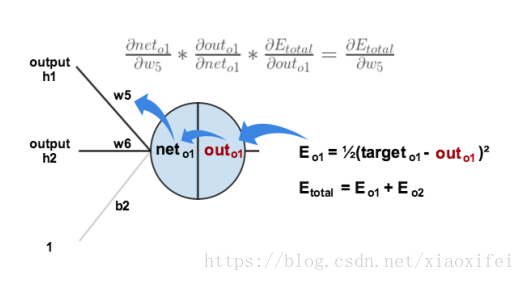
很显然对于E的w偏导数,可以利用链式法则得到如下表示:(根据上述引用材料的记载Etotal由out1和out2构成,具体数值由材料所给出)
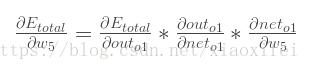
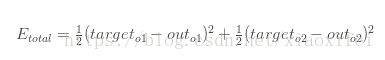
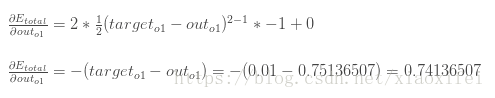
outo1是由sigmoid激活函数给出,因此如下所示:
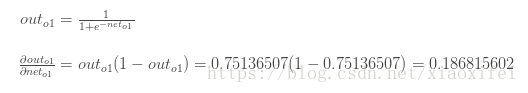
由上图所示:
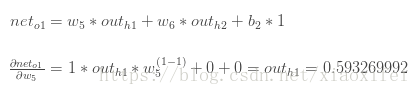
此时可以得到关于E和w5的偏导公式的各个组元,然后将数据代入,可以得到偏导数的值

在往常的一些记载中会使用如下的记法来表示:

所以最终的偏导可以记为:
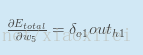
根据梯度下降算法的思路,为了修正w5,认为对w5的更新项,应当如下式表示:
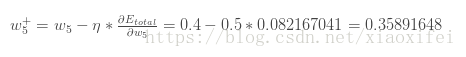
其中偏导前的系数为人为设置的常数,就是常说的学习率,这里设置为0.5,这样整个回路就完成了对权重因子w5的更新
有了以上的实例,再看UFDL 的介绍就更加明白了(http://deeplearning.stanford.edu/wiki/index.php/Backpropagation_Algorithm)