Vanishing/Exploring gradients 梯度消失/爆炸
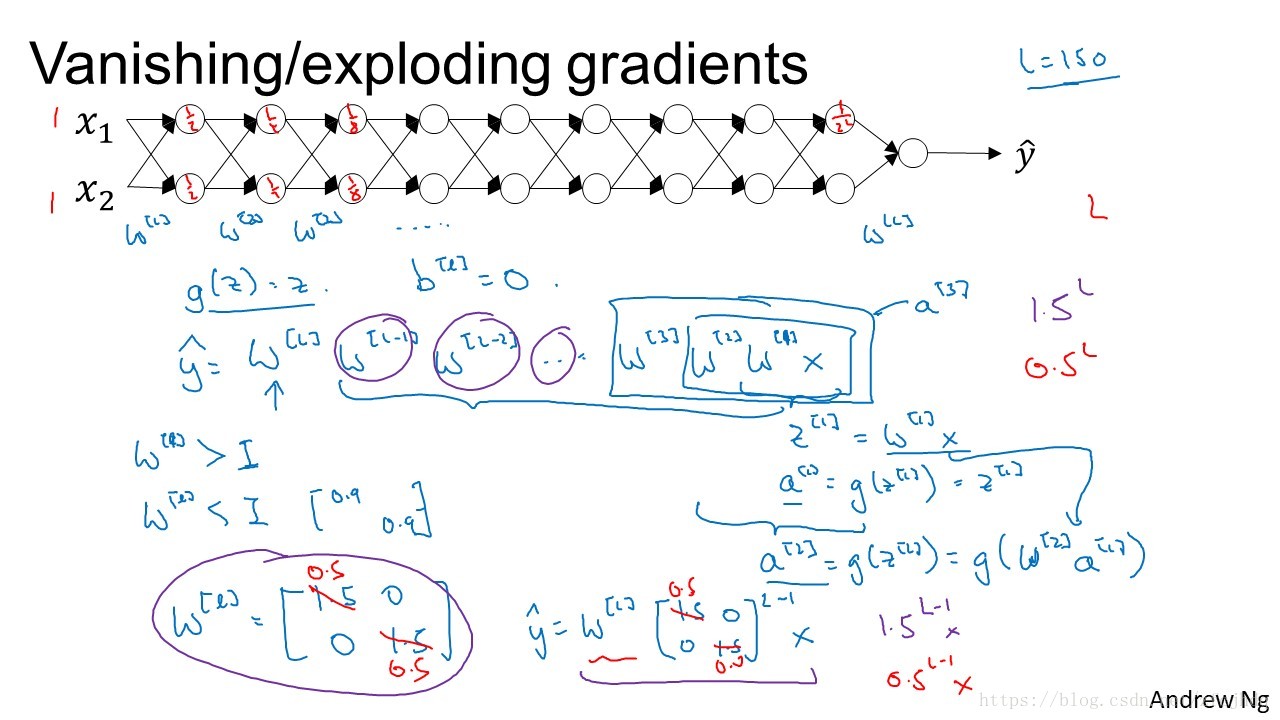
如图所示,由于深度神经网络深度较大,当每一层的
w
都小于1或者都大于1时,最终的输出值会成指数级较小或上升,造成梯度消失或者爆炸,从而使得梯度下降变得困难
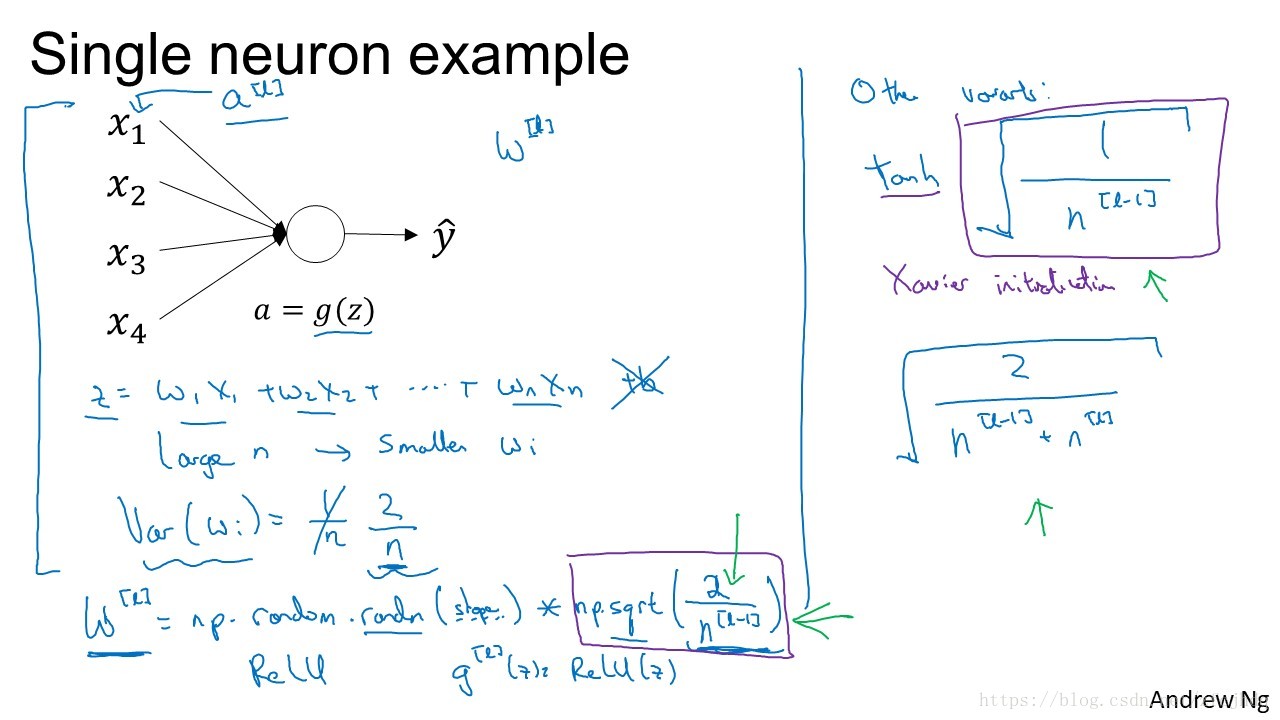
1. 为了不让
z
太大,当
n
越大时,
w
的值应该越小
2. 针对
ReLU
,初始化
w[l]=np.random.randn(shape)∗np.sqrt(2n[l−1])
3. 针对
tanh
,初始化
w[l]=np.random.randn(shape)∗np.sqrt(1n[l−1])
,方法叫做Xavier initialization.
4. 还有些小众一点的,如
w[l]=np.random.randn(shape)∗np.sqrt(2n[l−1]+n[l])
通过以上方法,并不能完全解决梯度消失/爆炸问题,但是可以减缓影像,加速训练