Deep Learning 基础 – 激活函数/损失函数
Tags: Deep_Learning
本文主要包含如下内容:
激活函数
如果不使用激活函数,你的网络的分类能力基本等同于一个线性分类器(线性回归),网络表达能力不足,无法逼近任意函数,所以激活函数是相当关键的。
激活函数的特征:非线性\可微性(用于梯度下降算法)\单调性(保证单层网络是凸函数)
Sigmoid非线性函数
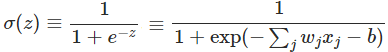

优点:
它输入实数值并将其压缩到0到1范围内,即很大的负数变为0,很大的正数变为1。
缺点:
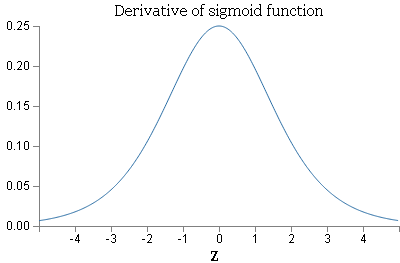
Sigmoid函数饱和使梯度消失:当函数激活值接近于0或者1时,函数的梯度接近于0。在反向传播计算梯度过程中:每层残差接近于0,计算出的梯度也不可避免地接近于0。这样在参数微调过程中,会引起参数弥散问题,传到前几层的梯度已经非常靠近0了,参数几乎不会再更新。为了防止梯度消失,必须对于权重矩阵初始化特别留意。(梯度最大值为0.25)
Sigmoid函数的输出不是零中心的。这会导致后一层的神经元将得到上一层输出的非 0 均值的信号作为输入。
exp指数函数运算复杂,会花费大量的时间。
Tanh非线性函数
导数为:f(z)’ = 1 − (f(z))2,最大值为1.
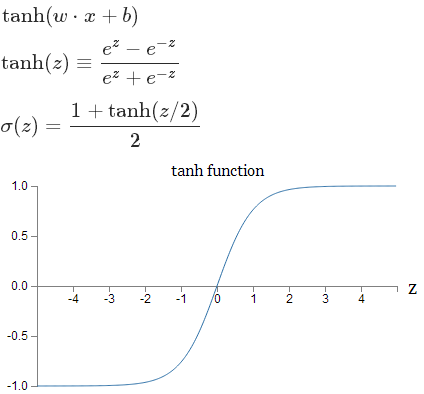

它将实数值压缩到[-1,1]之间。和
sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。因此,在实际操作中,
tanh非线性函数比
sigmoid非线性函数更受欢迎。
ReLU激活函数

优点:
计算高效:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用。在反向传播过程中,减轻了梯度弥散的问题,神经网络前几层的参数也可以很快的更。
正向传播过程中,sigmoid和tanh函数计算激活值时需要计算指数,而Relu函数仅需要设置阈值。如果,如果。加快了正向传播的计算速度。
ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
缺点:
梯度为0或者为1,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。
与sigmoid类似,ReLU的输出均值也大于0,偏移现象和 神经元死亡会共同影响网络的收敛性。
Leaky ReLU激活函数
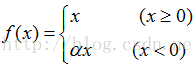
α 是一个很小的常数(如0.25)。这样,即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。
优点:
不会饱和\计算高效\收敛速度快\不会死
Exponential Linear Units (ELU)
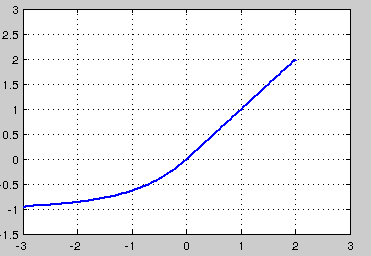
优点:
不会死\输出接近0均值
缺点:
计算量大,需要指数运算
Maxout激活函数
Maxout是对ReLU和leaky ReLU的一般化归纳。ReLU和Leaky ReLU都是这个公式的特殊情况(比如ReLU就是当w_1,b_1=0的时候)。这样Maxout神经元就拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)。然而和ReLU对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
损失函数
MSE损失 + Sigmoid激活函数
对于Sigmoid,当z的取值越来越大后,函数曲线变得越来越平缓,意味着此时的导数σ′(z)也越来越小。同样的,当z的取值越来越小时,也有这个问题。仅仅在z取值为0附近时,导数σ′(z)的取值较大。在均方差+Sigmoid的反向传播算法中,每一层向前递推都要乘以σ′(z),得到梯度变化值。Sigmoid的这个曲线意味着在大多数时候,我们的梯度变化值很小,导致我们的W,b更新到极值的速度较慢,也就是我们的算法收敛速度较慢。

SigmoidCrossEntropyLoss(交叉熵损失+Sigmoid激活函数)


使用交叉熵,得到的的梯度表达式没有了σ′(z),梯度为预测值和真实值的差距,这样求得的Wl,bl的梯度也不包含σ′(z),因此避免了反向传播收敛速度慢的问题。
SoftmaxWithLoss(广义线性回归分析损失层) (对数似然损失+softmax进行分类输出)
解决分类问题,输出层神经元输出的值在0到1之间,同时所有输出值之和为1.



可见,梯度计算也很简洁,也没有第一节说的训练速度慢的问题。
EuclideanLoss(欧式损失层)
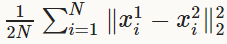
当预测值与目标值相差很大时, 梯度容易爆炸, 因为梯度里包含了x−t.
Smooth L1 Loss
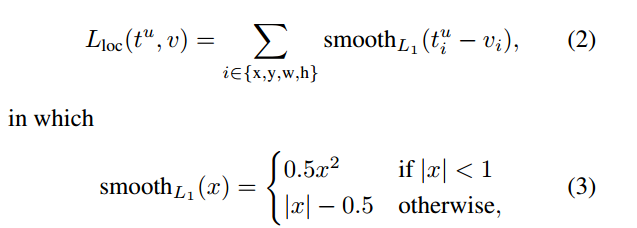
当差值太大时, 原先L2梯度里的x−t被替换成了±1, 这样就避免了梯度爆炸, 也就是它更加健壮.