模型评估
余弦相似度
对于两个向量A和B,其余弦相似度定义为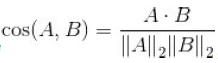 ,即两个向量夹角的余弦,关注的是向量之间的角度关系,并不关心绝对大小, 其取值范围为[-1,1]。有着“相同时为1,正交时为0,相反时为-1”的性质。当一对文本在长度相似度很大,但内容相近时,如果使用词频或者词向量作为特征,它们在特征空间的欧氏距离通常很大;而如果使用余弦相似度的话,它们之间的夹角可能很小,因而相似度高。
,即两个向量夹角的余弦,关注的是向量之间的角度关系,并不关心绝对大小, 其取值范围为[-1,1]。有着“相同时为1,正交时为0,相反时为-1”的性质。当一对文本在长度相似度很大,但内容相近时,如果使用词频或者词向量作为特征,它们在特征空间的欧氏距离通常很大;而如果使用余弦相似度的话,它们之间的夹角可能很小,因而相似度高。
如果希望得到类似于距离的表示,将1减去余弦相似度即为余弦距离:![]()
而在一些场景例如Word2Vec中,向量的模长经过归一化,此时欧氏距离和余弦距离有着单调的关系,即
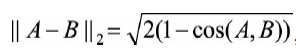
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。例如,统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为(1,0),此时两者的余弦距离很大,而欧氏距离很小。此时我们更关注相对差异,显然应当使用余弦距离。而当分析用户活跃度,以登陆次数和平均观看时长作为特征时,很显然此时应该使用欧氏距离。
余弦距离不是一个“严格定义”的距离?
距离的定义:正定性、对称性、三角不等式。
余弦距离满足正定性
,由于
,故余弦距离恒大于等于0,满足正定性。
余弦距离满足对称性
余弦距离不满足三角不等式,假定给定A=(1,0),B=(1,1),C=(0,1)
and
and
。
有
同样不满足距离的定义的还有相对熵(KL距离),它常用于计算两个分布之间的差异。
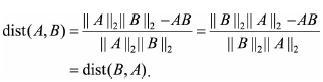
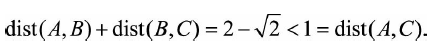
A/B TEST
原因:
- 离线评估无法完全消除过拟合的影响,因此结果无法完全替代线上评估结果。
- 离线评估无法完全还原线上的工程环境。如延迟、数据丢失、标签数据缺失等情况。
- 线上系统的某些商业指标在离线评估中无法计算。比如,上线新的推荐算法,离线评估往往只关注ROC曲线、PR曲线等改进,而线上评估可以全面了解该推荐算法带来的用户点击率、留存时长等。
做法:
主要手段是对用户进行分桶,将用户分为实验组和对照组,实验组的用户使用新模型,对照组使用旧模型,确保每一个用户每次只能分到同一个桶中。
Holdout检验与交叉验证
这两种都是通过划分训练集和测试集的方法。
Holdout检验简单直接,将原始样本随机划分为训练集和验证集两部分,如70%和30%,但是缺点也很明显,最后评估指标和原
始分组有很大关系。
k-fold交叉验证:将全部样本划分为k个大小相等的样本子集。依次遍历k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,最后把k次评估指标的平均值作为最终的评估指标。
自助法
样本总数为n,进行n次有放回随机抽样,得到大小为n的训练集。n次采样过程中,有的样本会被重复采样,有的样本没有被抽出过,将未被抽出过的样本作为验证集。
当n趋于无穷大时,有多少数据未被选择过?
这个问题在随机森林(使用bootstrap,有放回采样)也提到过。
一个样本在一次抽样中未被抽中的概率为
,n次都未被抽中的概率为
,
当n趋于无穷大时,求极限
所以当样本数很大时,约36.8%的样本从未被选择过,可作为验证集。
模型调优
超参数调优一般会采用网格搜索、随机搜索、贝叶斯优化等算法。
首先需要明确超参数搜索算法包括的因素:
- 目标函数
- 搜索范围
- 其他参数,如搜索步长
网格搜索
使用最广泛的方法。通过查找范围内的所有点来确定最优值,如果采用较大的范围和较小的步长,网格搜索有很大的概率找到全局最优值。但缺点是十分耗费计算资源和时间。
在实际应用中,网格搜索一般会先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置。然后逐渐缩小搜索范围和步长,寻找更精确的最优值。但由于目标函数一般是非凸的,很可能会错过全局最优值。
随机搜索
在搜索范围中随机选取样本点。随机搜索一般比网格搜索更快,但结果仍然无法保证。
贝叶斯优化
通过对目标函数的形状进行学习。首先根据先验分布,假设一个搜集函数,然后,通过每次使用新点进行测试,贝叶斯优化会把每次测试后的新点加入先验分布(利用这个信息来更新目标函数的先验分布),然后通过后验分布在最可能出现全局最值的区域进行采样。关于贝叶斯更详细的介绍:个人总结:朴素贝叶斯。
贝叶斯优化的缺点是,一旦找到一个局部最优值,它会在该区有不断采样,所以很容易陷入局部最优值。为了弥补,贝叶斯会在“探索”和“利用”之间找到一个平衡点,“探索”就是在还未取样的区域获取采样点,“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。
过拟合与欠拟合

降低过拟合的方法,在个人总结:CNN、tf.nn.conv2d(卷积)与 tf.nn.conv2d_transpose(反卷积)以及激活函数也提到了如何处理CNN中过拟合的方法,这里部分类似:
- 增加更多数据。例如图像分类可以通过图像的平移、旋转、缩放等方式
- 降低模型复杂度。例如神经网络减少网络层数、神经元个数等,决策树中降低树的深度,剪枝等
- 正则化方法。给模型的参数加上正则化约束,如将权值大小加入损失函数
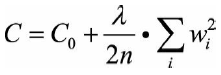
- L1、L2正则化。用贝叶斯理论来解释的话,相当于对参数分别加入了拉普拉斯先验和高斯先验,损失函数可看做似然函数,则把整个问题看做为一个最大后验概率估计。通过对参数引入先验分布,使得模型复杂度变小(缩小解空间),对于噪声以及outliers的鲁棒性增强(泛化能力)。
- 集成学习方法
降低欠拟合的方法:
- 添加新特征。如“上下文特征”“ID特征”“组合特征”。FM,GBDT,Deep-crossing也可以帮助构建特征
- 增加模型复杂度
- 减小正则化系数
