目录
一、决策树简介
决策树既可以分类,也可以回归。构造决策树两种方式:预剪枝/后剪枝
难点:如何构造决策树,选什么特征作为结点。
特点:根节点是分类效果最好的,其余次之、再次之。
决策树停止划分结点的原因可能是:达到最大叶子节点数了、叶子结点样本数够少了、未达到划分结点的衡量标准(e.g 信息熵变化不明显)等等
二、构造决策树的小栗子
就用sklearn中自带的一个数据集进行演示
1. 读取数据、了解分布情况
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets.california_housing import fetch_california_housing #采用内置数据集
housing=fetch_california_housing()
print(housing.DESCR) #关于这个数据集的简介
print(housing.data.shape) #(20640, 8)
print(type(housing)) #<class 'sklearn.utils.Bunch'>
print(housing.data[0]) #输出一行数据瞅瞅啥样输出:关于这个数据集的介绍,从简介中可以看出,这个数据集包含8个属性:average income,housing average age, average rooms, average bedrooms, population,average occupation, latitude, and longitude

2. 数据预处理
因为是自带的数据库,数据没啥大问题,这步忽略,进入下一步
3. 建立决策树模型
为了简化模型,我们只考虑最后两项特征(经纬度)对房屋价格的影响
# 构造决策树
from sklearn import tree
dtr=tree.DecisionTreeRegressor(max_depth=2) #第一步:实例化树模型——传递参数
dtr.fit(housing.data[:,[6,7]],housing.target) #第二步:构造树模型——传入X值与y值输出:这个树的信息,构造过程用的参数情况,可以看到有非常多的参数,但要去设置的也不多,最重要的是max_depth和max_leaf_nodes。
DecisionTreeRegressor(criterion='mse', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
各参数的含义:


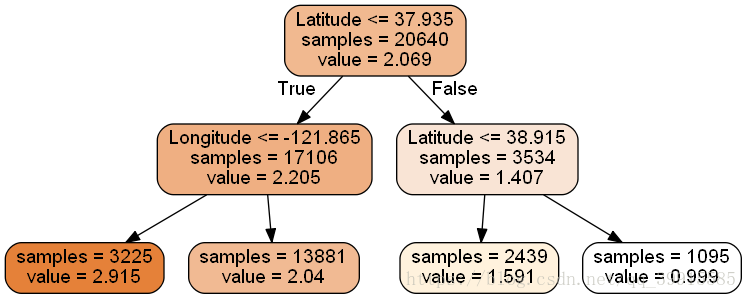
4. 决策树的可视化显示
此处要安装graphviz,在官网(http://www.graphviz.org/Download_windows.php)下载安装就可以了
# 先生成.dot文件
dot_data= \
tree.export_graphviz(
dtr, # 决策树的名字
out_file=None,
feature_names=housing.feature_names[6:8],#特征名字
filled=True,
impurity=False,
rounded=True
)
# 对.dot文件进行显示
import pydotplus #pip install pydotplus
graph=pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor('#FFF2DD')
from IPython.display import Image #notebook中不需要安装,但是pycharm中需要安装
Image(graph.create_png())
# 保存到本地
graph.write_png('dtr_white_background.png')结果:
5. 决策树的评估 .score
重新建立了一个决策树,把所有的性质都用上了
from sklearn.model_selection import train_test_split
data_train,data_test,target_train, target_test=\
train_test_split(housing.data, housing.target, test_size=0.1,random_state=42)
dtr=tree.DecisionTreeRegressor(random_state=42)
dtr.fit(data_train, target_train)
dtr.score(data_test, target_test)输出:0.637318351331017
三、随机森林进行决策
1. 通过随机森林进行决策
from sklearn.ensemble import RandomForestRegressor
rfr=RandomForestRegressor(random_state=42)
rfr.fit(data_train,target_train)
rfr.score(data_test,target_test)输出:0.7908649228096493
四、通过交叉验证将各特征进行排序
1. 交叉验证
## 交叉验证选出最好的参数
from sklearn.grid_search import GridSearchCV
tree_param_grid = { 'min_samples_split': list((3,6,9)),'n_estimators':list((10,50,100))}
grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5)
grid.fit(data_train, target_train)
grid.grid_scores_, grid.best_params_, grid.best_score_结果:
([mean: 0.78590, std: 0.00274, params: {'min_samples_split': 3, 'n_estimators': 10},
mean: 0.80537, std: 0.00404, params: {'min_samples_split': 3, 'n_estimators': 50},
mean: 0.80774, std: 0.00387, params: {'min_samples_split': 3, 'n_estimators': 100},
mean: 0.78896, std: 0.00314, params: {'min_samples_split': 6, 'n_estimators': 10},
mean: 0.80562, std: 0.00407, params: {'min_samples_split': 6, 'n_estimators': 50},
mean: 0.80690, std: 0.00366, params: {'min_samples_split': 6, 'n_estimators': 100},
mean: 0.78679, std: 0.00504, params: {'min_samples_split': 9, 'n_estimators': 10},
mean: 0.80455, std: 0.00470, params: {'min_samples_split': 9, 'n_estimators': 50},
mean: 0.80557, std: 0.00411, params: {'min_samples_split': 9, 'n_estimators': 100}],
{'min_samples_split': 3, 'n_estimators': 100},
0.8077425553717694)2. 用最好的一组参数构建决策树
# 用筛选出来最好的参数来构造决策树
rfr=RandomForestRegressor(min_samples_split=3,n_estimators=100,random_state=42)
rfr.fit(data_train,target_train)
rfr.score(data_test,target_test) #0.80908290496531583. 将特征进行排序
pd.Series(rfr.feature_importances_,index=housing.feature_names).sort_values(ascending=False) #将属性的重要性进行排序MedInc 0.524257
AveOccup 0.137947
Latitude 0.090622
Longitude 0.089414
HouseAge 0.053970
AveRooms 0.044443
Population 0.030263
AveBedrms 0.029084