一 问题描述
选取最优方案划分泰坦尼克灾难数据集,构建决策树完成分类,并使用测试集进行生存状况的预测。
二 数据预处理
Titanic: Machine Learning from Disaster原始数据集包含10个变量,在本次训练和测试中仅使用前6个变量。

>训练集中共有891位乘客的数据信息,其中277位乘客的年龄数据缺失,余下数据年龄平均值为29.7,用30补全缺失项。 >由于年龄的分布广且随机,直接使用原始数据进行决策树划分多有不便,所以将年龄划分为children:0-19,和adult:20以上,分别用0和1表示。 >sibsp和parch项用1-0表示有或无。
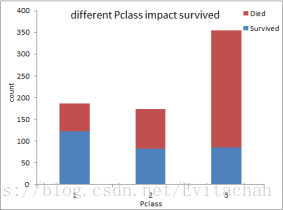

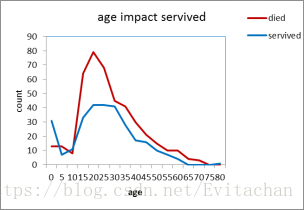

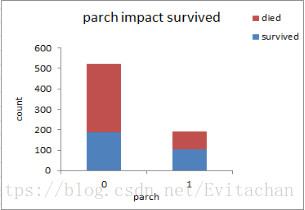
通过观察五张图,我们可以大致得出以下结论:
1. 舱位越好,存活率越高:一等舱>二等舱>三等舱
2. 女性存活率比男性高
3. 存活和死亡人群中年龄呈正态分布,未成年人和老年人存活率比壮年高
三 决策树原理
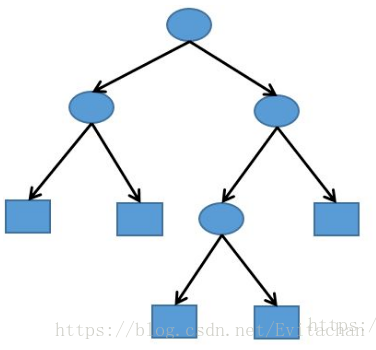
决策树是一种基于描述的对实例进行分类的树形结构,本质是多叉树。决策树包括内结点和叶结点,内结点代表特征,叶结点代表类,对于一个测试样本,从根结点开始判断该特征,将其分配到子结点,递归测试直到达到叶结点,得到分类结果。
五 决策树构建
从根结点开始,选择一种属性选择度量(如信息熵、增益率和基尼指数)来找到分类特征,选择分类效果最好的特征,按照这一特征将训练数据划分子集,如果子集能够准确分类,构建叶结点,将子集分配到叶结点上,如果不能准确划分,继续划分子集,直到所有子集都分配到叶结点上,这样就生成了一棵决策树。
属性选择度量是一种选择分裂准则,如果按照分裂准则的输出把数据集划分为较小的子集,理想的情况是,每个子集应该是纯的(即在同一个子集的所有样本点属于相同类)。下面介绍三种常用的属性选择度量:信息增益,增益率,基尼指数。
1. 信息增益
ID3算法使用信息增益作为属性选择度量。划分数据集前后信息量的变化称为信息增益。我们可以计算每个特征划分数据集的信息增益,一般来说,信息增益越大,使用这个特征进行划分的纯度提升越大。
对于数据集D,熵为:

其中pi是属于第i类的非零概率。现在按照特征A来划分D,并且特征A有v中可能取值{a1,a2,...,av}。如果A是离散的,用A对D划分为v个子集{D1,D2,...,Dv}。Dj的A值为aj。基于A对D划分的期望信息为:
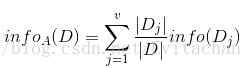
信息增益为原来的信息需求(仅基于类比例)和新的信息需求(对A划分后)之差:
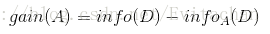
选择具有最高增益gain(A)的特征A作为分裂属性。
2. 增益率
C4.5算法使用增益率作为属性选择度量。先将信息增益规范化为分裂信息:
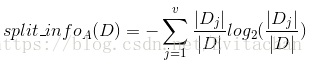
该值代表由数据集D划分为对于特征A的v个输出的v个子集的信息。
增益率定义为:
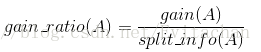
选择具有最大增益率的特征作为分裂属性。
3. 基尼指数
基尼指数:假设有K个分类,样本点属于k类的概率为pk,则概率分布的基尼指数定义为:
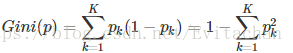
对于给定集合D的基尼指数为:
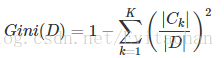
假如以A的v元划分将D化为两个子集D1和D2,在这种划分下, 基尼指数为:
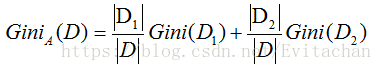
对于每种特征,考虑划分后产生的最小基尼指数的子集作为分裂子集。
六 模型建立
1. 最佳划分方式
将全部数据集输入calcShannonEnt函数返回香农熵,splitDataSet函数按照选定特征将全部数据集划分为选定特征值相同的子数据集,chooseBestFeatureToSplit函数中遍历calcShannonEnt和splitDataSet函数的到最佳划分方式。
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
2. 决策树的构建
createTree函数输入数据集和标签列表,计算得到字典变量myTree包含所有划分信息。迭代第一次得到使得划分后信息增益最大的特征,过滤后对子数据集迭代,直到所有特征划分完毕。
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat, value),subLabels)
return myTree
3. 测试模型
example()函数中根据泰坦尼克数据集和标签列表得到决策树。调用treePlotter函数绘出决策树。
file2matrix函数将原始的txt文件转换为元组储存在titanicDataMat中。遍历测试集,比较分类器分类结果和实际结果,若错误,错误计数加1,遍历完毕后就能得到错误率。理论上使用测试函数可以直接得到错误率。
def example():
fr=open('titanictrain.txt')
titanic=[inst.strip().split('\t') for inst in fr.readlines()]
titanicLabels=['Pclass','Sex','Age','SibSp','Parch']
titanicTree=createTree(titanic,titanicLabels)
return titanicTree
def datingClassTest():
myTree =example()
fr1=open('test.txt')
Lenses=[inst1.strip().split('\t') for inst1 in fr1.readlines()]
labels=['Pclass','Sex','Age','SibSp','Parch']
errorCount = 0.0
realResult=[]
testResult=[]
for Lense in Lenses:
realResult.append(Lense[-1])
testResult.append(classify(myTree,labels,Lense))
for i in range(0,len(realResult)):
print("test result: %s, the real answer is: %s"% (testResult[i], realResult[i]))
if (testResult[i] !=realResult[i]): errorCount += 1.0
str= "error rate is: %f" % (errorCount/float(len(Lenses)))
print(str)
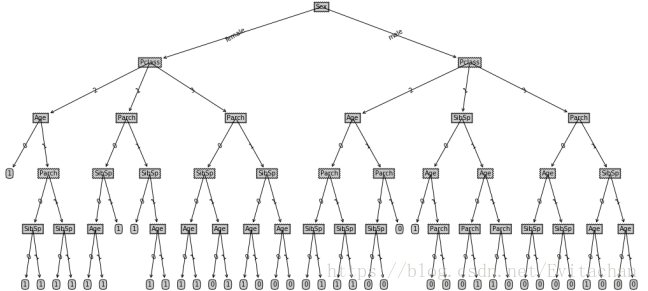
测试结果错误率为0.29
七 总结
1. 该决策树算法只适用对离散特征值进行分类,连续特征值必须离散化或者以分裂点区间作为分类标准。
2. 该算法没有剪枝,所以最后的决策树有冗余结点。
3. 特征值选择本身是降维过程,主观选择对决策树影响较大,考虑在改进算法中使用主成分分析法。
4. 对缺失数据项的处理方法可能会影响决策树的构建。
参考资料
【1】《机器学习实战》 Peter Harrington 著 人民邮电出版社
【2】《机器学习》 周志华 著 清华大学出版社
【3】《数据挖掘概念与技术》 Jiawei Han等 著 机械工业出版社