DAG介绍
●DAG是什么
DAG(Directed Acyclic Graph有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是RDD执行的流程)
原始的RDD通过一系列的转换操作就形成了DAG有向无环图,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)
●DAG的边界
开始:通过SparkContext创建的RDD
结束:触发Action,一旦触发Action就形成了一个完整的DAG
●注意:
一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action
一个DAG中会有不同的阶段/stage,划分阶段/stage的依据就是宽依赖
一个阶段/stage中可以有多个Task,一个分区对应一个Task
DAG划分Stage
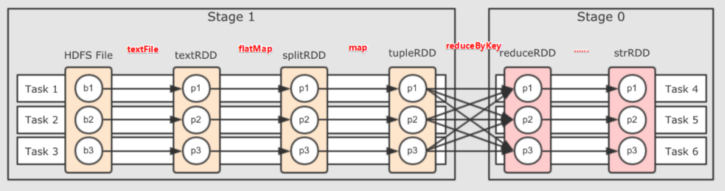
●为什么要划分Stage? --并行计算
一个复杂的业务逻辑如果有shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle进行划分(也就是按照宽依赖就行划分),就可以将一个DAG划分成多个Stage/阶段,在同一个Stage中,会有多个算子操作,可以形成一个pipeline流水线,流水线内的多个平行的分区可以并行执行
●如何划分DAG的stage
对于窄依赖,partition的转换处理在stage中完成计算,不划分(将窄依赖尽量放在在同一个stage中,可以实现流水线计算)
对于宽依赖,由于有shuffle的存在,只能在父RDD处理完成后,才能开始接下来的计算,也就是说需要要划分stage(出现宽依赖即拆分)
●总结
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中
