Spark性能优化
- 官方网址
- 基础优化
- RDD算子优化
-
-
- 0.collect/top慎用
- 0.foreach和foreachPartition/map和mapPartition
- 1.复用RDD
- 2.对于大量的数据可以尽早进行filter过滤,减少后续操作的成本(但是也得根据实际业务来)
- 3.读取大量小文件可以使用wholeTextFiles
- 4.尽量使用mapPartition和foreachPartition
- 5.可以使用filter过滤减少数据后,再使用repartition/coalesce减少分区
- 6.repartition/coalesce(分区数,true)可以调节并行度/分区数/Task数
- 7.使用reduceByKey而不是groupByKey+sum
-
- shuffle
- 数据倾斜
- JVM参数调优
- 故障排除
官方网址
- http://spark.apache.org/docs/latest/configuration.html
- http://spark.apache.org/docs/latest/tuning.html
基础优化
1.资源参数:
- 根据实际的任务数据量/优先级/公司集群的规模进行设置
增加Executor·个数- 在资源允许的情况下,增加
Executor的个数可以提高执行task的并行度。 - 比如有4个Executor,每个Executor有2个CPU core,那么可以并行执行8个task,
如果将Executor的个数增加到8个(资源允许的情况下),那么可以并行执行16个task,此时的并行能力提升了一倍
- 在资源允许的情况下,增加
增加每个Executor的CPU core个数- 在资源允许的情况下,增加每个Executor的
Cpu core个数,可以提高执行task的并行度。 - 比如有4个Executor,每个Executor有2个CPU core,那么可以并行执行8个task,如果将每个Executor的CPU core个数增加到4个(资源允许的情况下),那么可以并行执行16个task,此时的并行能力提升了一倍。
- 在资源允许的情况下,增加每个Executor的
增加每个Executor的内存量- 在资源允许的情况下,增加每个
Executor的内存量以后,对性能的提升有三点:- 1.可以
缓存更多的数据(即对RDD进行cache),写入磁盘的数据相应减少,
甚至可以不写入磁盘,减少了可能的磁盘IO; - 2.可以
为shuffle操作提供更多内存,即有更多空间来存放reduce端拉取的数据,
写入磁盘的数据相应减少,甚至可以不写入磁盘,减少了可能的磁盘IO; - 3.可以为task的执行提供更多内存,在task的执行过程中可能创建很多对象,
内存较小时会引发频繁的GC,增加内存后,可以避免频繁的GC,提升整体性能。
- 1.可以
- 在资源允许的情况下,增加每个
2.并行度(分区数/Task数)
- 原则是充分利用CPU的Core,一般可以设置为
CPU核数的2~3倍,这样可以充分压榨利用CPU的计算资源,如有100CPU, 那么可以将平行度设置为200~300(当然设置为100可以做的真正的并行,但是设置为200`300可以让CPU的计算资源更加充分的被利用)
3.持久化+Checkpoint
- 对于频繁使用且计算复杂的rdd执行如下操作:
sc.setCheckpointDir("HDFS路径")
rdd.persist(StorageLevel.MEMORY_ANDDISK)
rdd.checkpoint
4.使用广播变量
val 广播变量名= sc.broadcast(会被各个Task用到的变量即需要广播的变量)
广播变量名.value //获取广播变量
- 注意:
广播变量中的数据不能变化,如果数据有变化需要重新广播
5.使用Kryo序列化
- 2.0之后对于简单基本类型及其集合类型+String类型及其集合类型默认使用的就是Kryo,自定义类型需要注册
第一步:将自己的类实现KryoRegistrator接口并重写方法
public class MyClass implements KryoRegistrator{
@Override
public void registerClasses(Kryo kryo){
kryo.register(MyClass.class);
}
}
第二步:在SparkConf注册
//创建SparkConf对象
val conf = new SparkConf().setMaster(…).setAppName(…)
//使用Kryo序列化库
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//在Kryo序列化库中注册自定义的类集合
conf.set("spark.kryo.registrator", "cn.hanjiaxiaozhi.MyClass");
6.数据本地化查找等待时间-不要轻易改动
- 因为官方默认值已经是大多数情况下的默认值
val conf = new SparkConf().set("spark.locality.wait", "6")

RDD算子优化
0.collect/top慎用
0.foreach和foreachPartition/map和mapPartition
选用带Partition
1.复用RDD
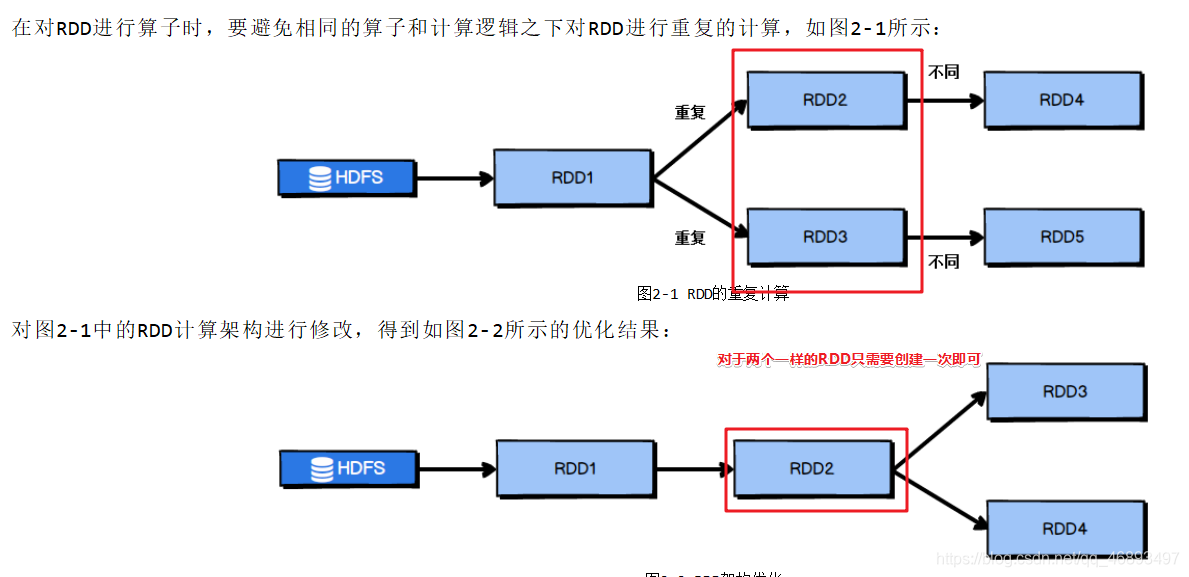
2.对于大量的数据可以尽早进行filter过滤,减少后续操作的成本(但是也得根据实际业务来)
3.读取大量小文件可以使用wholeTextFiles
- 因为普通的
sc.textFile("")有多少小文件就有多少分区 - 而wholeTextFiles的分区数有参数决定
package cn.hanjiaxiaozhi.hello
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object WordCount_bak2 {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")//设置运行参数
val sc: SparkContext = new SparkContext(conf)//创建sc
sc.setLogLevel("WARN") //设置日志级别
//2.读取文件夹下的多个小文件
//RDD[(文件名, 内容)]
//val fileRDD: RDD[String] = sc.textFile("")
val filesRDD: RDD[(String, String)] = sc.wholeTextFiles("D:\\data\\spark\\files", minPartitions = 3)
//指定分区数为3,哪怕有1000个小文件也只有3个分区,避免了使用textFiles,有多少小文件就有多少分区
//_._2不再是之前的每一行数据,而是每一个文件中的内容
//而每一个文件中的内容多行,所以用换行符进行切分
//RDD[每一行]
val linesRDD: RDD[String] = filesRDD.flatMap(_._2.split("\\r\\n"))
//RDD[单词]
val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
wordsRDD.map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}
4.尽量使用mapPartition和foreachPartition
- 比如将数据存入的数据库,使用foreachPartition每个分区开启关闭连接一次.
5.可以使用filter过滤减少数据后,再使用repartition/coalesce减少分区
6.repartition/coalesce(分区数,true)可以调节并行度/分区数/Task数
7.使用reduceByKey而不是groupByKey+sum
- 因为reduceByKey只需要一步操作,并且
reduceByKey底层做了优化,进行本地预聚合,会在各个机器的本地局部聚合之后,再将聚合结果发给其他机器进行全局聚合
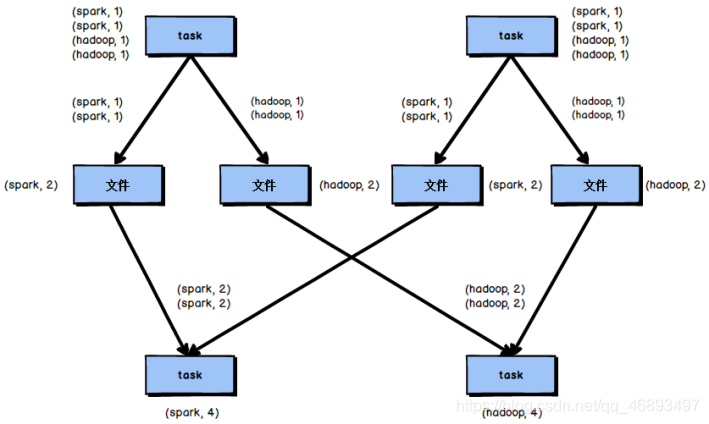
shuffle
shuffle分类和bypass机制的开启
- 1.未经优化的HashShuffle:小文件过多 —淘汰
- 2.优化之后的HashShuffle:小文件减少了,但是没有排序 —淘汰
- 3.普通机制的sortShuffle:在形成中间小文件前在内存中进行排序,并且小文件带有索引编号 --开发中ReduceTask>阈值(200)使用该机制(也就是shuffle之后/子RDD的分区数>200,就启用普通机制的sortShuffle)
- 4.==bypass机制的sortShuffle:==没有排序,进一步减了小文件,形成的文件带有索引编号(和优化之后的HashShuffle对比多了文件带有索引编号) --开发中ReduceTask<阈值(200)使用该机制(shuffle之后/子RDD的分区数<200,就启用普通机制的sortShuffle)
- 当shuffle是reasTask数量小于200的时候开启bypass机制,大于200时使用普通机制的sortShuffle
- 总结:Spark对于Shuffle做了很多了优化,不同的版本中所支持的shuffle也很多,但是对于程序员来说,只有两个选择(因为其他的已经淘汰了)
- 这两个选择中,
- 如果
需要排序使用普通机制reduceTask>阈值(默认200) - 如果
不需要排序使用bypass机制 reduceTask<阈值(默认200)
- 如果
- 如何切换? 设置阈值
val conf = new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "400")
- 在实际中,比如shufflet的reduceTask数量是300,默认会启动普通机制的sortShuffle会进行排序,但是可能后面的业务没有排序,那么shuffle时的排序就比较浪费性能,如何解决?
- 可以调整参数,将开启bypass机制的阈值调大为300以上
- val conf = new SparkConf().set(“spark.shuffle.sort.bypassMergeThreshold”, “400”)
map端和reduce端内存设置
-
val conf = new SparkConf().set(“spark.shuffle.file.buffer”, “64”)
- 上面参数调大可以减少map端溢写磁盘次数
-
val conf = new SparkConf().set(“spark.reducer.maxSizeInFlight”, “96”)
- 上面参数调大可以减少reduce端拉取次数
reduce端重试次数和等待时间间隔
为了避免减少拉取次数,导致每次拉取数据时间间隔变长,导致误任务拉取失败,可以调大拉取等待时间间隔和重试次数
val conf = new SparkConf().set(“spark.shuffle.io.maxRetries”, “6”)
val conf = new SparkConf().set(“spark.shuffle.io.retryWait”, “10s”)
数据倾斜
- 数据倾斜的本质就是
某一个分区对应的数据太多了,和其他分区不均衡 - 而数据分区由又key决定的
- 也就是
由key分布不均导致的数据倾斜 - 那么如果我们能够根据key自己去分配数据到不同的分区,那么就解决了数据倾斜问题
- 1.
提高并行度-repartition (比如分10个区,数据倾斜了,那么分15个区可能就解决了,因为分区编号 = key的hash % 分区数) - 2.预处理导致倾斜的key:如果
加盐/加随机数前缀/后缀 - 3.自定义分区器(终极解决方案)-想怎么分区怎么分区
- 1.
- Flnik中一个算子搞定: reblance()
- 八种解决 Spark 数据倾斜的方法
JVM参数调优
- 1.降低cache内存提高用于计算的内存
- val conf = new SparkConf().set(“spark.storage.memoryFraction”, “0.4”)
- 2.设置Executor堆外内存–不是JVM内存
- –conf spark.yarn.executor.memoryOverhead=2048
- 3.设置JVM进程间通信等待时间
- –conf spark.core.connection.ack.wait.timeout=300
故障排除
- 1.避免OOM-out of memory
- 将之前非计算的角色占用内存的设置调小(cache内存调小)或者增加机器内存
- 2.避免GC导致的shuffle文件拉取失败
- JVM的gc垃圾回收会让JVM出现短暂的暂停
- 了解:Flnik使用的自己封装的内存管理,能够避免JVM的GC所带来的对于Flink程序的影响
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "6")//调大重试次数
.set("spark.shuffle.io.retryWait", "10s")//调大拉取等待时间
- 3.YARN-CLIENT模式导致的网卡流量激增问题
- 使用cluster模式即可
- 4.YARN-CLUSTER模式的JVM栈内存溢出无法执行问题
- –conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
- 5.避免SparkSQL JVM栈内存溢出
- 将长SQL拆分为多条短SQL去分步执行
- 避免过多的表进行join操作