逻辑回归和支持向量机之间的区别也是面试经常会问的一道题,特地找了一些相关资料看了下。
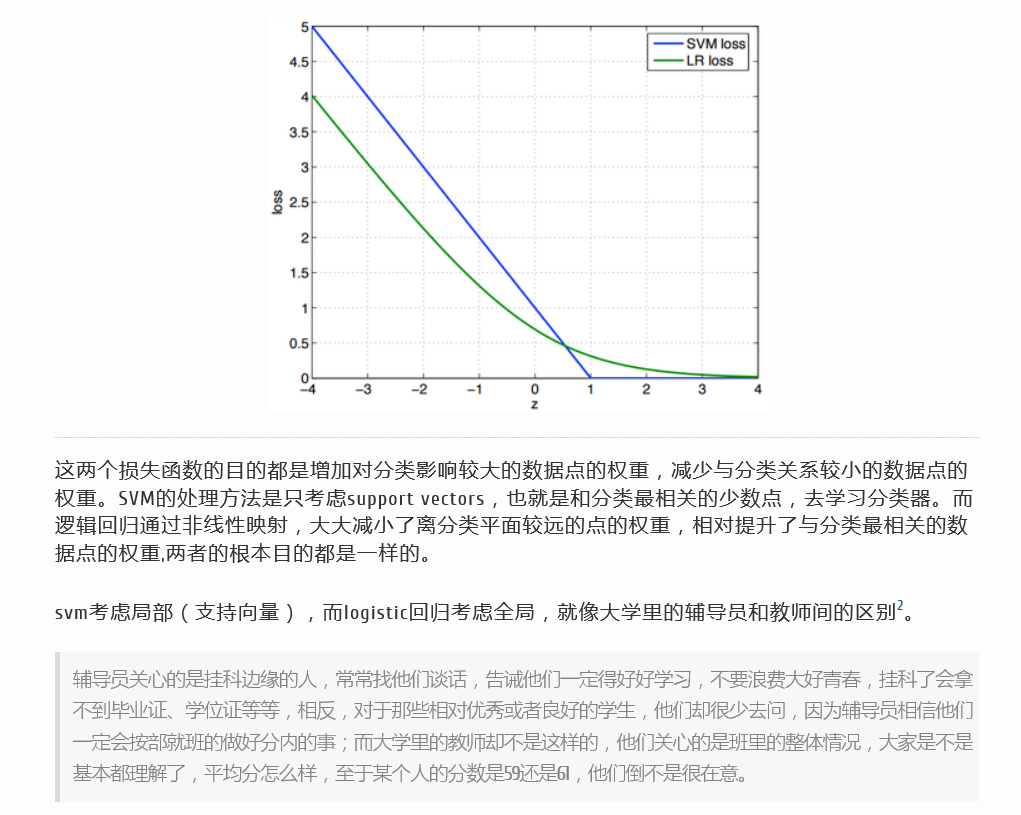
损失函数

原文地址:http://charlesx.top/2016/03/LR-SVM/
不好意思啊,我不太懂你说的log loss是log likelihood吗。我记得课上说logistic regression是用Maximum log Likelihood 来的.。
实质上,在这个问题里面,对数损失和极大似然估计是等价的。
- 我们知道损失函数是用来衡量预测的错误程度,机器学习的基本策略就是使得经验风险最小化,也就是模型在训练上的损失最小,这是一种普适的思路。
- 而对于涉及到概率的问题,极大似然估计也是使得估计错误最小的一种思路,从数学推导上来看,LR的经验风险就是极大似然估计取个对数加个负号而已。
这是两种思维方式,但本质上是一样的,损失函数这一套逻辑是机器学习的普适逻辑,而极大似然估计这套思想是来解决概率相关问题,如果对于回归问题,还怎么用极大似然估计?(MSE,MAE)
1,优化目标不同。LR的目标函数是logloss,SVM是最大化分类面间距。2,对非线性问题的处理方式不同。LR主要靠特征构造,必须组合交叉特征,特征离散化。SVM也可以这样,还可以通过kernel。3,处理的数据规模不同。LR一般用来处理大规模的学习问题。如十亿级别的样本,亿级别的特征。
http://www.zhihu.com/question/24904422
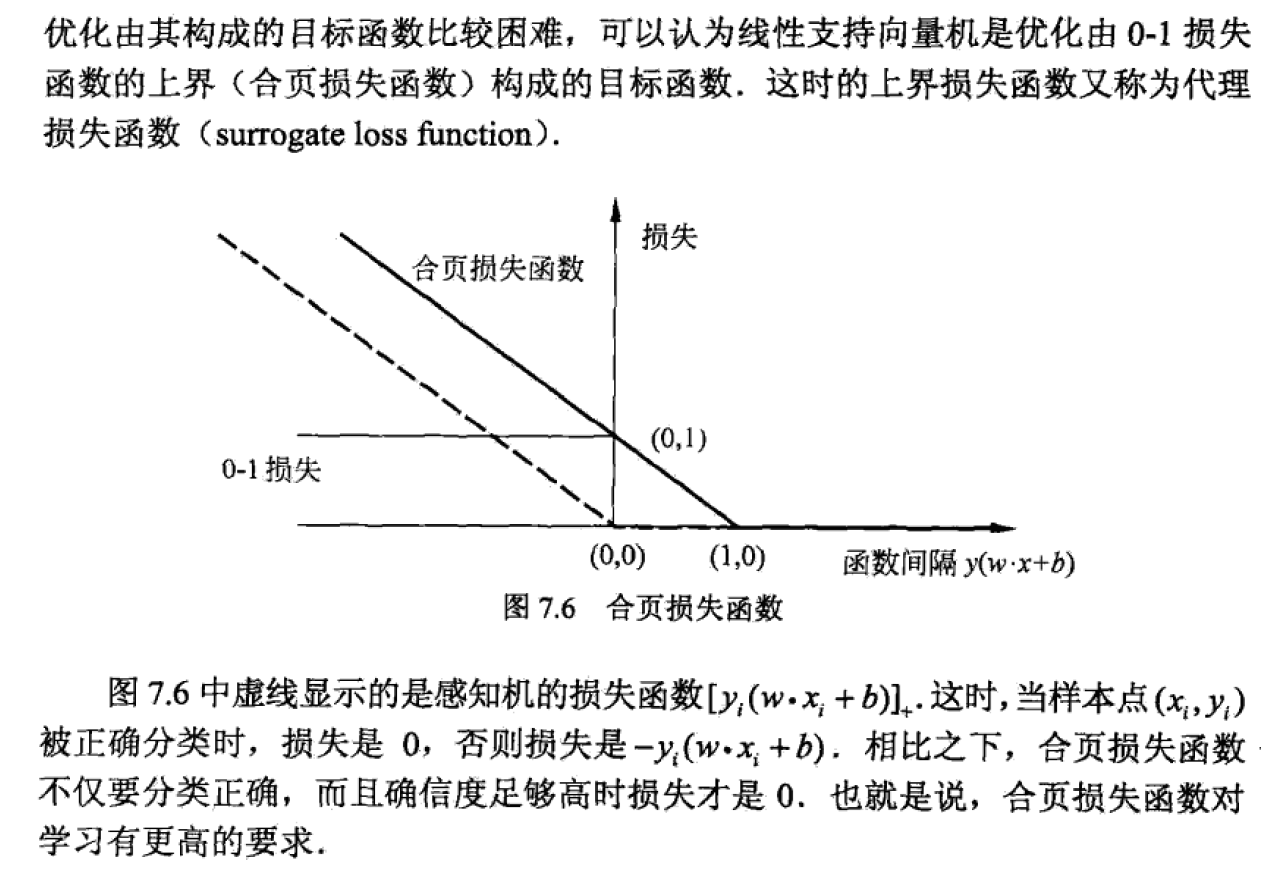
合页损失函数:《统计学习方法》