机器学习的类别
机器学习分为四大块,如下图所示,分别是:
classification (分类),regression (回归), clustering (聚类), dimensionality reduction (降维)。
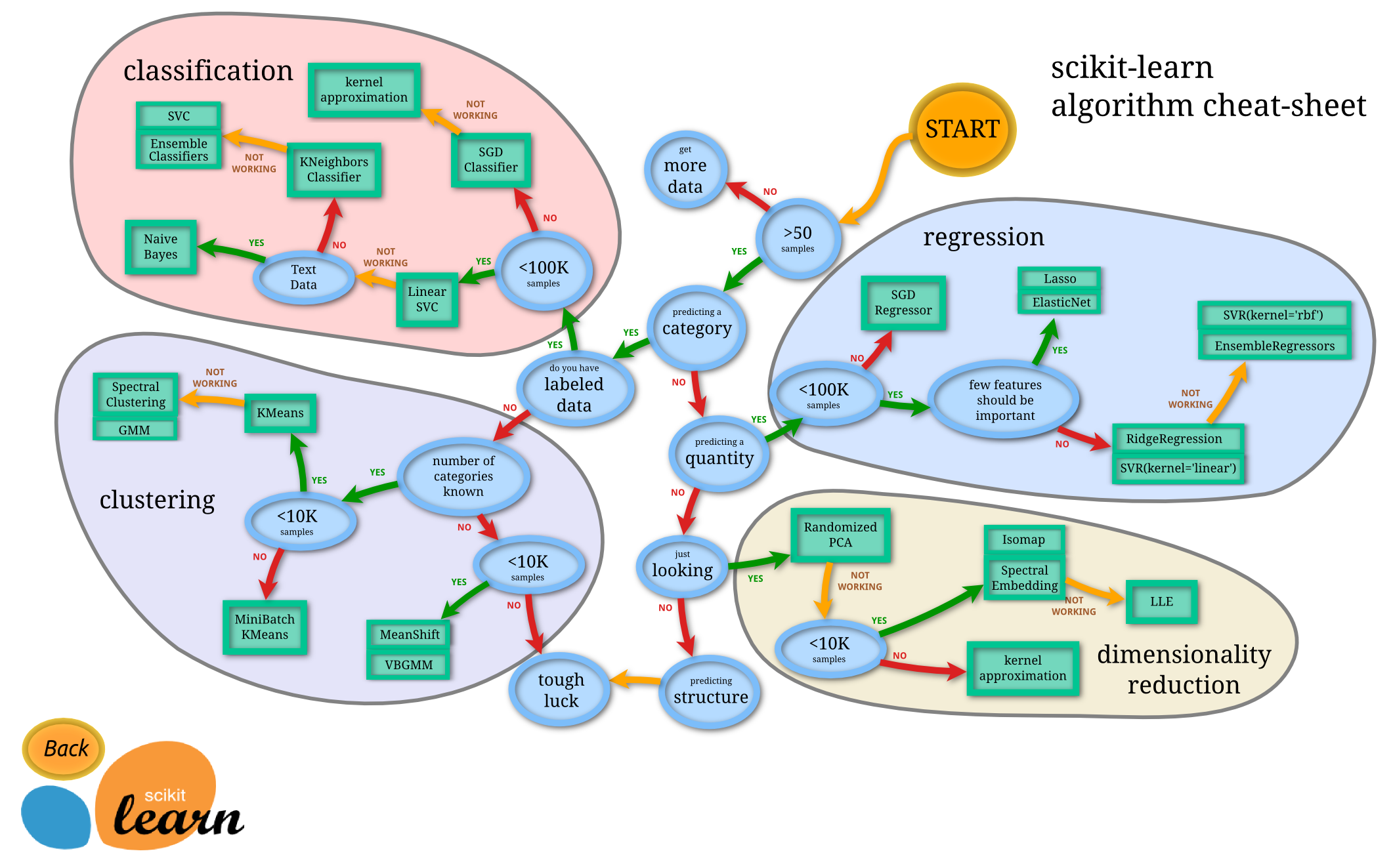
区分方式
给定一个样本特征 , 我们希望预测其对应的属性值 , 如果 是离散的, 那么这就是一个分类问题,反之,如果 是连续的实数, 这就是一个回归问题。
给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在多维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
如果我们想用维数更低的子空间来表示原来高维的特征空间, 那么这就是降维问题。
详解
1.classification & regression
无论是分类还是回归,都是想建立一个预测模型 ,给定一个输入 , 可以得到一个输出;不同的只是在分类问题中,预测结果是离散的; 而在回归问题中预测结果是连续的。所以总得来说,两种问题的学习算法都很类似。所以在这个图谱上,我们看到在分类问题中用到的学习算法,在回归问题中也能使用。分类问题最常用的学习算法包括 SVM (支持向量机) , SGD (随机梯度下降算法), Bayes (贝叶斯估计), Ensemble(集成), KNN 等。而回归问题也能使用 SVR, SGD, Ensemble 等算法,以及其它线性回归算法。
2.clustering
聚类也是分析样本的属性, 有点类似classification, 不同的就是classification 在预测之前是知道结果属性的范围, 或者说知道到底有几个类别, 而聚类是不知道属性的范围的。所以classification 也常常被称为 supervised learning, 而clustering就被称为unsupervised learning。
clustering 事先不知道样本的属性范围,只能凭借样本在特征空间的分布来分析样本的属性。这种问题一般更复杂。而常用的算法包括 k-means (K-均值), GMM (高斯混合模型) 等。
3.dimensionality reduction
降维是机器学习另一个重要的领域, 降维有很多重要的应用, 特征的维数过高, 会增加训练的负担与存储空间, 降维就是希望去除特征的冗余, 用更加少的维数来表示特征.降维算法最基础的就是PCA了, 后面的很多算法都是以PCA为基础演化而来。