特征集
学习目标:创建一个包含极少特征但效果与更复杂的特征集一样出色的集合。
到目前为止,我们已经将所有特征添加到了模型中。具有较少特征的模型会使用较少的资源,并且更易于维护。我们来看看能否构建这样一种模型:包含极少的住房特征,但效果与使用数据集中所有特征的模型一样出色。
第1步:设置:加载必要的库+加载数据+数据预处理
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.ERROR)
pd.options.display.max_rows = 10
pd.options.display.float_format = '{:.1f}'.format
california_housing_dataframe = pd.read_csv("https://storage.googleapis.com/mledu-datasets/california_housing_train.csv", sep=",")
#打乱表格数据顺序,这是一个极其重要的步骤!
california_housing_dataframe = california_housing_dataframe.reindex(
np.random.permutation(california_housing_dataframe.index))
def preprocess_features(california_housing_dataframe):
#加州房价表的信息载入预处理特征
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]]
processed_features = selected_features.copy()
# Create a synthetic feature.
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
def preprocess_targets(california_housing_dataframe):
#预处理目标
output_targets = pd.DataFrame()
# Scale the target to be in units of thousands of dollars.
output_targets["median_house_value"] = (
california_housing_dataframe["median_house_value"] / 1000.0)
return output_targets第2步:预览检查数据
#预览数据
# Choose the first 12000 (out of 17000) examples for training.
training_examples = preprocess_features(california_housing_dataframe.head(12000))
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
# Choose the last 5000 (out of 17000) examples for validation.
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
# Double-check that we've done the right thing.
print "Training examples summary:"
display.display(training_examples.describe())
print "Validation examples summary:"
display.display(validation_examples.describe())
print "Training targets summary:"
display.display(training_targets.describe())
print "Validation targets summary:"
display.display(validation_targets.describe())

第3步:查看“皮尔逊相关系数”
correlation_dataframe = training_examples.copy()
correlation_dataframe["target"] = training_targets["median_house_value"]
correlation_dataframe.corr()#输出“皮尔逊相关系数”-1.0:完全负相关,0.0:不相关,1.0:完全正相关
第4步:创建线性回归模型
def construct_feature_columns(input_features):
#创建特征列
return set([tf.feature_column.numeric_column(my_feature)
for my_feature in input_features])
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
#Trains a linear regression model of one feature.
#训练一个特征的线性回归模型
#features: pandas DataFrame of features
#特征:来自pandas表格的特征
#targets: pandas DataFrame of targets
#目标:来自pandas表格的目标
#batch_size: Size of batches to be passed to the model
#批次大小:单次传入模型的数据量大小
#shuffle: True or False. Whether to shuffle the data.
#洗牌:是否对数据进行洗牌
#num_epochs: Number of epochs for which data should be repeated. None = repeat indefinitely
#数据重复使用次数
# dict(features).items():将输入的特征值转换为dictinary(python的一种数据类型)
# 通过for语句遍历,得到其所有的一一对应的值(key:value)
features = {key:np.array(value) for key,value in dict(features).items()}
# Construct a dataset, and configure batching/repeating
ds = Dataset.from_tensor_slices((features,targets)) # warning: 2GB limit
ds = ds.batch(batch_size).repeat(num_epochs)
# Shuffle the data, if specified
if shuffle:
ds = ds.shuffle(10000)
# Return the next batch of data
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels第5步:创建训练模型
#创建训练模型
def train_model(
learning_rate,
steps,
batch_size,
training_examples,
training_targets,
validation_examples,
validation_targets):
"""Trains a linear regression model.
In addition to training, this function also prints training progress information,
as well as a plot of the training and validation loss over time.
Args:
learning_rate: A `float`, the learning rate.
steps: A non-zero `int`, the total number of training steps. A training step
consists of a forward and backward pass using a single batch.
batch_size: A non-zero `int`, the batch size.
training_examples: A `DataFrame` containing one or more columns from
`california_housing_dataframe` to use as input features for training.
training_targets: A `DataFrame` containing exactly one column from
`california_housing_dataframe` to use as target for training.
validation_examples: A `DataFrame` containing one or more columns from
`california_housing_dataframe` to use as input features for validation.
validation_targets: A `DataFrame` containing exactly one column from
`california_housing_dataframe` to use as target for validation.
"""
periods = 10
steps_per_period = steps / periods
# Create a linear regressor object.
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0)
linear_regressor = tf.estimator.LinearRegressor(
feature_columns=construct_feature_columns(training_examples),
optimizer=my_optimizer
)
# Create input functions
training_input_fn = lambda: my_input_fn(training_examples,
training_targets["median_house_value"],
batch_size=batch_size)
predict_training_input_fn = lambda: my_input_fn(training_examples,
training_targets["median_house_value"],
num_epochs=1,
shuffle=False)
predict_validation_input_fn = lambda: my_input_fn(validation_examples,
validation_targets["median_house_value"],
num_epochs=1,
shuffle=False)
# Train the model, but do so inside a loop so that we can periodically assess
# loss metrics.
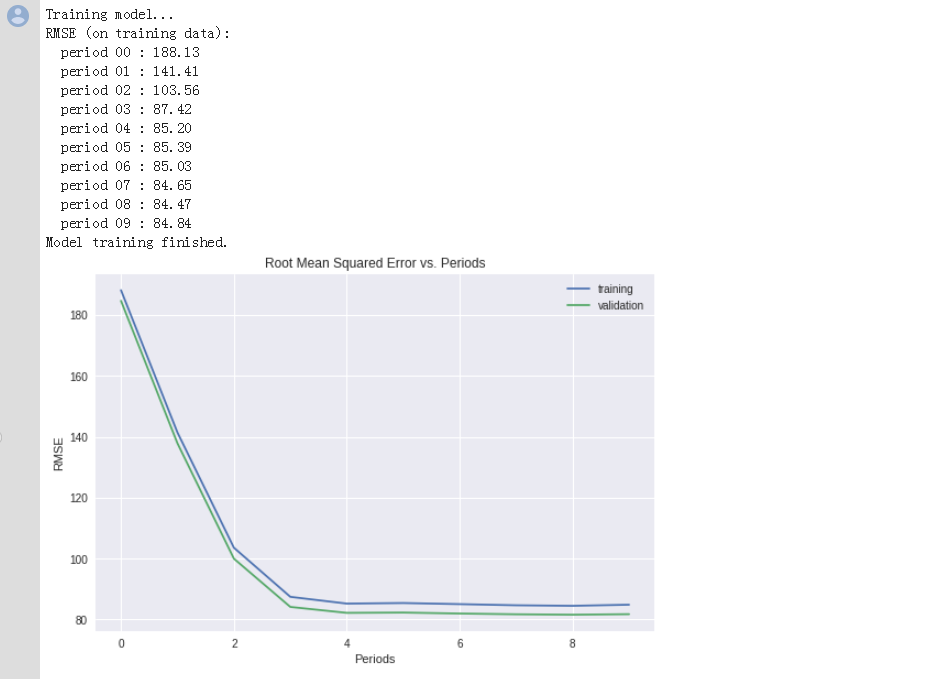
print "Training model..."
print "RMSE (on training data):"
training_rmse = []
validation_rmse = []
for period in range (0, periods):
# Train the model, starting from the prior state.
linear_regressor.train(
input_fn=training_input_fn,
steps=steps_per_period,
)
# Take a break and compute predictions.
training_predictions = linear_regressor.predict(input_fn=predict_training_input_fn)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
validation_predictions = linear_regressor.predict(input_fn=predict_validation_input_fn)
validation_predictions = np.array([item['predictions'][0] for item in validation_predictions])
# Compute training and validation loss.
training_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(training_predictions, training_targets))
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(validation_predictions, validation_targets))
# Occasionally print the current loss.
print " period %02d : %0.2f" % (period, training_root_mean_squared_error)
# Add the loss metrics from this period to our list.
training_rmse.append(training_root_mean_squared_error)
validation_rmse.append(validation_root_mean_squared_error)
print "Model training finished."
# Output a graph of loss metrics over periods.
plt.ylabel("RMSE")
plt.xlabel("Periods")
plt.title("Root Mean Squared Error vs. Periods")
plt.tight_layout()
plt.plot(training_rmse, label="training")
plt.plot(validation_rmse, label="validation")
plt.legend()
return linear_regressor
第6步:选择特征并调整参数模型
minimal_features = [
"median_income",
"latitude",
]
#把选择的特征载入训练样本
minimal_training_examples = training_examples[minimal_features]
minimal_validation_examples = validation_examples[minimal_features]
_ = train_model(
learning_rate=0.01,
steps=500,
batch_size=5,
training_examples=minimal_training_examples,
training_targets=training_targets,
validation_examples=minimal_validation_examples,
validation_targets=validation_targets)
第7步:优化尝试
为了获得更好的效果,我们尝试通过散点图看一下房价和纬度的关系
plt.scatter(training_examples["latitude"], training_targets["median_house_value"])
#绘制房价和纬度散点图
通过绘制 latitude 与 median_house_value 的图形后,表明两者确实不存在线性关系。
不过,有几个峰值与洛杉矶和旧金山大致相对应。
所以我们尝试创建一些能更好地利用纬度的合成特征。
我们可以将该空间分成 10 个不同的分桶(例如 latitude_32_to_33、latitude_33_to_34 等):如果 latitude 位于相应分桶范围内,则显示值 1.0;如果不在范围内,则显示值 0.0。
LATITUDE_RANGES = zip(xrange(32, 44), xrange(33, 45))
#(32~33)打包成一阶,(33~34)打包成一阶,一直到(44~45)打包成一阶
def select_and_transform_features(source_df):
selected_examples = pd.DataFrame()
selected_examples["median_income"] = source_df["median_income"]
for r in LATITUDE_RANGES:
#进行分桶操作
selected_examples["latitude_%d_to_%d" % r] = source_df["latitude"].apply(
lambda l: 1.0 if l >= r[0] and l < r[1] else 0.0)
return selected_examples
selected_training_examples = select_and_transform_features(training_examples)
selected_validation_examples = select_and_transform_features(validation_examples)#调整模型参数
_ = train_model(
learning_rate=0.05,
steps=500,
batch_size=5,
training_examples=selected_training_examples,
training_targets=training_targets,
validation_examples=selected_validation_examples,
validation_targets=validation_targets)结果如图:
问题和学习:
Q1:zip函数如何使用?
A1:zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
使用效果下:

关于更多zip函数的内容参考:http://www.runoob.com/python/python-func-zip.html
Q2:以下五行程序的如何理解?
selected_examples = pd.DataFrame()
selected_examples["median_income"] = source_df["median_income"]
for r in LATITUDE_RANGES:
#进行分桶操作
selected_examples["latitude_%d_to_%d" % r] = source_df["latitude"].apply(
lambda l: 1.0 if l >= r[0] and l < r[1] else 0.0)A2:只能理解到进行了分桶操作,如果数据处于分桶内输出1.0否则输出0.0,具体语法规则后续查Series.apply语法后进行补充。
本文请结合Google 机器学习,编程练习:使用TensorFlow的起始步骤一起观看
编程练习地址:https://colab.research.google.com/notebooks/mlcc/feature_sets.ipynb?hl=zh-cn#scrollTo=PzABdyjq7IZU
第5步:创建训练模型
第5步:选择特征并调整参数模型