验证
学习目标:
-
使用多个特征而非单个特征来进一步提高模型的有效性
-
调试模型输入数据中的问题
-
使用测试数据集检查模型是否过拟合验证数据
与在之前的练习中一样,我们将使用加利福尼亚州住房数据集,尝试根据 1990 年的人口普查数据在城市街区级别预测 median_house_value。
第1步:设置+数据预处理
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.ERROR)
pd.options.display.max_rows = 10
pd.options.display.float_format = '{:.1f}'.format
california_housing_dataframe = pd.read_csv("https://storage.googleapis.com/mledu-datasets/california_housing_train.csv", sep=",")
# california_housing_dataframe = california_housing_dataframe.reindex(
# np.random.permutation(california_housing_dataframe.index))def preprocess_features(california_housing_dataframe):
#Prepares input features from California housing data set.
#对表格进行预处理,从表格中读取数据到selected_features中
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]]
processed_features = selected_features.copy()
# Create a synthetic feature.#创建合成特征,创建一个人均拥有房间数的特征
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
def preprocess_targets(california_housing_dataframe):
#创建目标
output_targets = pd.DataFrame()
# 把目标房屋的价格调整成以千美元为单位
output_targets["median_house_value"] = (
california_housing_dataframe["median_house_value"] / 1000.0)
return output_targets
def preprocess_features(california_housing_dataframe):
#Prepares input features from California housing data set.
#对表格进行预处理,从表格中读取数据到selected_features中
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]]
processed_features = selected_features.copy()
# Create a synthetic feature.#创建合成特征,创建一个人均拥有房间数的特征
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
def preprocess_targets(california_housing_dataframe):
#创建目标
output_targets = pd.DataFrame()
# 把目标房屋的价格调整成以千美元为单位
output_targets["median_house_value"] = (
california_housing_dataframe["median_house_value"] / 1000.0)
return output_targets第2步:检查数据
#训练特征集选择17000个样本中的前12000个样本。(!!!此处注意,未随机打乱样本,是个错误的做法,为练习需要,特地做错。)
training_examples = preprocess_features(california_housing_dataframe.head(12000))
training_examples.describe()#输出数据总览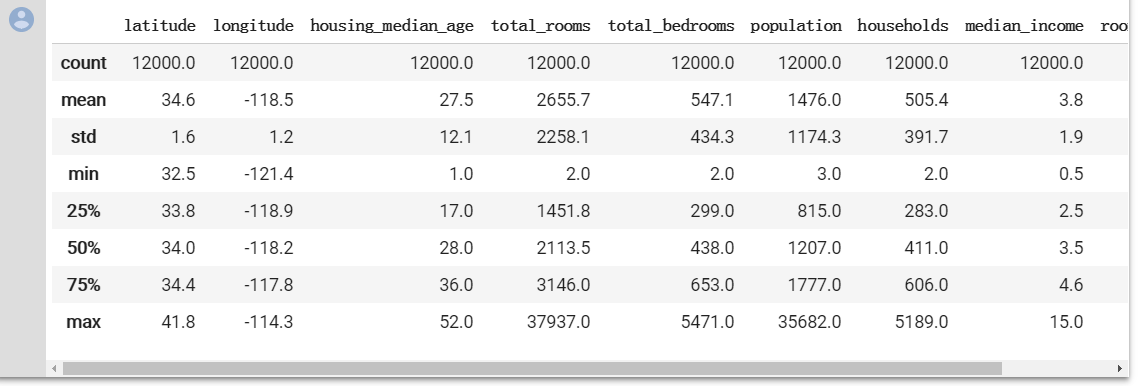
#训练目标集选择17000个样本中的前12000个样本。
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
training_targets.describe()#输出数据总览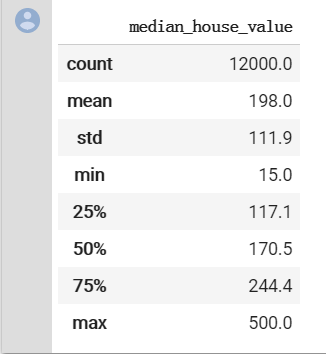
#验证特征集选取17000个样本中的后5000个样本
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
validation_examples.describe()#输出数据总览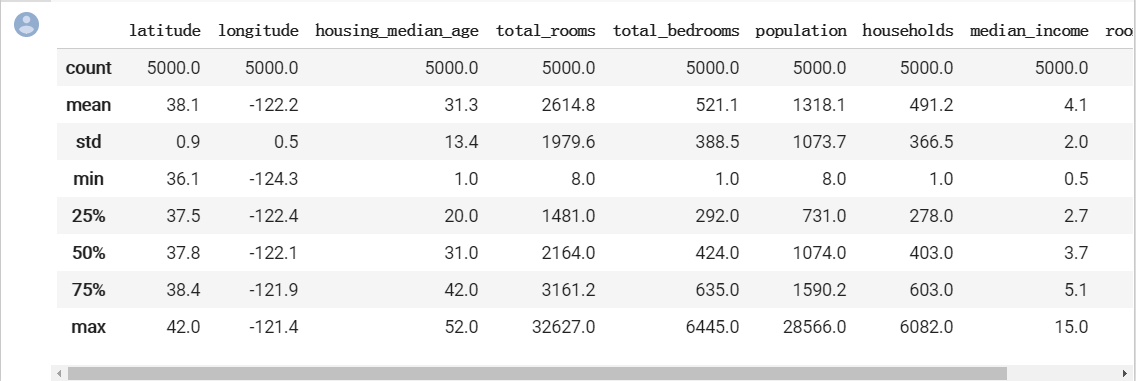
#验证目标集选取17000个样本中的后5000个样本
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
validation_targets.describe()#输出数据总览
扫描二维码关注公众号,回复:
2372899 查看本文章

与在之好的,我们看一下上面的数据。可以使用的输入特征有 9 个。
快速浏览一下表格中的值。我们会发现一些不正常的地方:
-
对于一些值(例如 median_house_value),我们可以检查这些值是否位于合理的范围内(请注意,这是 1990 年的数据,不是现在的!)。
-
对于 latitude 和 longitude 等其他值,我们可以通过 Google 进行快速搜索,并快速检查一下它们与预期值是否一致。
如果您仔细看,可能会发现下列异常情况:
-
median_income 位于 3 到 15 的范围内。我们完全不清楚此范围究竟指的是什么,看起来可能是某对数尺度?无法找到相关记录;我们所能假设的只是,值越高,相应的收入越高。
-
median_house_value 的最大值是 500001。这看起来像是某种人为设定的上限。
-
rooms_per_person 特征通常在正常范围内,其中第 75 百分位数的值约为 2。但也有一些非常大的值(例如 18 或 55),这可能表明数据有一定程度的损坏。
第3步:绘制纬度/经度与房屋价值中位数的曲线图
plt.figure(figsize=(13, 8))#新建绘画窗口,自定义画布大小为13*8
ax = plt.subplot(1, 2, 1)# 设置画布划分以及图像在画布上输出的位置1行2列,绘制在第1个位置
ax.set_title("Validation Data")#创建表头
ax.set_autoscaley_on(False)#y轴自动缩放:关
ax.set_ylim([32, 43])#y轴坐标为(32,43)
ax.set_autoscalex_on(False)#x轴自动缩放:关
ax.set_xlim([-126, -112])#x轴坐标为(-126,-112)
#绘制散点图x轴为经度y轴为纬度,颜色图谱为冷暖色,颜色数值为房价
plt.scatter(validation_examples["longitude"],
validation_examples["latitude"],
cmap="coolwarm",
c=validation_targets["median_house_value"] / validation_targets["median_house_value"].max())
ax = plt.subplot(1,2,2)# 设置画布划分以及图像在画布上输出的位置1行2列,绘制在第2个位置
ax.set_title("Training Data")#下面注释同上
ax.set_autoscaley_on(False)
ax.set_ylim([32, 43])
ax.set_autoscalex_on(False)
ax.set_xlim([-126, -112])
plt.scatter(training_examples["longitude"],
training_examples["latitude"],
cmap="coolwarm",
c=training_targets["median_house_value"] / training_targets["median_house_value"].max())
_ = plt.plot()结果如图:
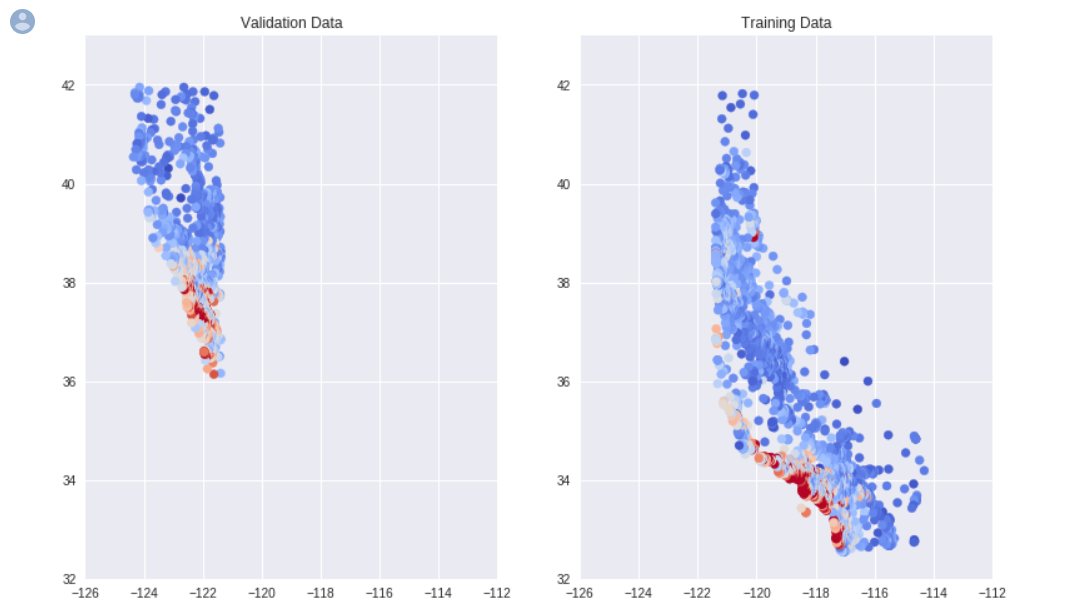
我们会发现训练集和验证集的分布分隔成了两部分,就像是把加州的地图给剪开了一样,这是因为我们在创建训练集和验证集之前没有对数据进行正确的随机化处理。
第4步:训练和评估模型
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
# 自定义个输入函数
# 输入的参数分别为
# features:特征值(房间数量)
# targets: 目标值(房屋价格中位数)
# batch_size:每次处理训练的样本数(这里设置为1)
# shuffle: 如果 `shuffle` 设置为 `True`,则我们会对数据进行随机处理
# num_epochs:将默认值 `num_epochs=None` 传递到 `repeat()`,输入数据会无限期重复
# dict(features).items():将输入的特征值转换为dictinary(python的一种数据类型,
# 通过for语句遍历,得到其所有的一一对应的值(key:value)
features = {key:np.array(value) for key,value in dict(features).items()}
# dict(features).items():将输入的特征值转换为dictinary(python的一种数据类型,
# 通过for语句遍历,得到其所有的一一对应的值(key:value)
ds = Dataset.from_tensor_slices((features,targets)) # warning: 2GB limit
ds = ds.batch(batch_size).repeat(num_epochs)
# 混洗数据的批次大小
if shuffle:
ds = ds.shuffle(10000)
# 对所有数据遍历一遍,迭代的时候返回所有的结果
# 向 LinearRegressor 返回下一批数据
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
def construct_feature_columns(input_features):
#创建输入特征的特征列并数字格式化
return set([tf.feature_column.numeric_column(my_feature)
for my_feature in input_features])#创建训练模型
def train_model(
learning_rate,
steps,
batch_size,
training_examples,
training_targets,
validation_examples,
validation_targets):
#创建一个训练模型,除了训练功能外次函数还包括了打印进度信息
#以及随时间推移的训练和验证损失的情况。
#learning_rate:学习率
#step:训练的总步数,训练的步数包括前进的步数和后退的步数
#training_examples:训练样本
#training_targets:训练目标
#validation_examples:验证样本
#validation_targets:验证目标
periods = 10 #周期数为10,即每(训练步数/周期数)步输出一次
steps_per_period = steps / periods #每个周期的步数
#创建一个线性回归
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0)#使用梯度剪切防止梯度爆炸
#配置线性回归模型
linear_regressor = tf.estimator.LinearRegressor(
feature_columns=construct_feature_columns(training_examples),
optimizer=my_optimizer
) # 创建输入函数
#把训练样本和训练目标以及批次大小导入训练输入函数
training_input_fn = lambda: my_input_fn(
training_examples,
training_targets["median_house_value"],
batch_size=batch_size)
#训练预测函数:把训练样本,目标,和传递值(重复值)导入训练预测函数
predict_training_input_fn = lambda: my_input_fn(
training_examples,
training_targets["median_house_value"],
num_epochs=1,
shuffle=False)
#验证函数:把验证样本,目标,和传递值(重复值)导入验证预测函数
predict_validation_input_fn = lambda: my_input_fn(
validation_examples, validation_targets["median_house_value"],
num_epochs=1,
shuffle=False)#开始训练模型并输出训练过程中的数据
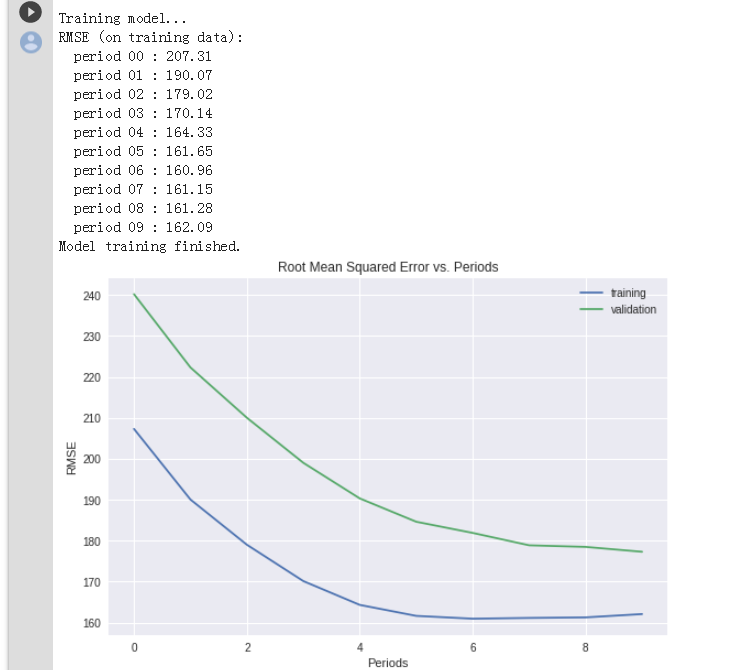
print "Training model..."
print "RMSE (on training data):"
training_rmse = []
validation_rmse = []
for period in range (0, periods):
# 继续训练模型,从上一次停止位置继续(停下来输出训练过程中的数据)
linear_regressor.train(
input_fn=training_input_fn,
steps=steps_per_period,
)
# 返回和计算以及验证的预测值
training_predictions = linear_regressor.predict(input_fn=predict_training_input_fn)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
validation_predictions = linear_regressor.predict(input_fn=predict_validation_input_fn)
validation_predictions = np.array([item['predictions'][0] for item in validation_predictions])
#计算训练以及验证的误差
training_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(training_predictions, training_targets))
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(validation_predictions, validation_targets))
#打印当前计算的损失
print " period %02d : %0.2f" % (period, training_root_mean_squared_error)
# Add the loss metrics from this period to our list.
training_rmse.append(training_root_mean_squared_error)
validation_rmse.append(validation_root_mean_squared_error)
print "Model training finished."
#输出一段时间内的损失指标和图表
plt.ylabel("RMSE")
plt.xlabel("Periods")
plt.title("Root Mean Squared Error vs. Periods")
plt.tight_layout()
plt.plot(training_rmse, label="training")
plt.plot(validation_rmse, label="validation")
plt.legend()
return linear_regressor#调整训练模型参数,开始训练和输出
linear_regressor = train_model(
learning_rate=0.00003,
steps=500,
batch_size=5,
training_examples=training_examples,
training_targets=training_targets,
validation_examples=validation_examples,
validation_targets=validation_targets)输出结果:如图
第6步:基于测试数据进行评估
#载入测试数据
california_housing_test_data = pd.read_csv("https://storage.googleapis.com/mledu-datasets/california_housing_test.csv", sep=",")
#载入测试样本和测试目标
test_examples = preprocess_features(california_housing_test_data)
test_targets = preprocess_targets(california_housing_test_data)
#把测试样本和数据输入到模型中
predict_test_input_fn = lambda: my_input_fn(
test_examples,
test_targets["median_house_value"],
num_epochs=1,
shuffle=False)
#计算预测值
test_predictions = linear_regressor.predict(input_fn=predict_test_input_fn)
test_predictions = np.array([item['predictions'][0] for item in test_predictions])
#计算测试样本的损失
root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(test_predictions, test_targets))
#输出测试样本的损失
print "Final RMSE (on test data): %0.2f" % root_mean_squared_error输出结果:

本文请结合Google 机器学习,编程练习:使用TensorFlow的起始步骤一起观看
编程练习地址:https://colab.research.google.com/notebooks/mlcc/validation.ipynb?hl=zh-cn
图像绘制处理可参考:https://www.cnblogs.com/denny402/p/5122594.html