将所学的内容整理出并结合实例推演,若有错误,敬请指教。欢迎讨论哈,机器学习爬坑中
目录
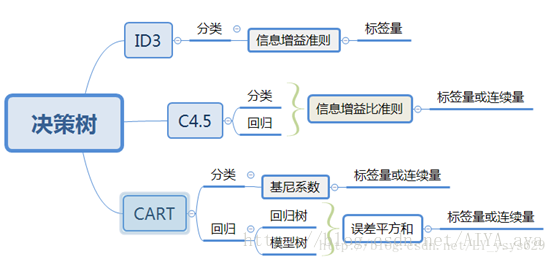
不同算法特征选择依据
信息熵
信息熵(entropy)度量信息不确定性的量化问题。在信息论中,熵是表示随机变量不确定性的度量。熵的取值越大,随机变量的不确定性也越大。单位,比特(bit)
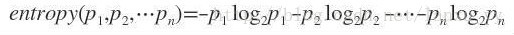
即:
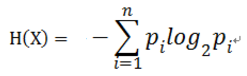
对于样本集合D来说,随机变量X是样本的类别,即,假设样本有k个类别,每个类别的概率是,其中|Ck|表示类别k的样本个数,|D|表示样本总数
则对于样本集合D来说熵(经验熵)为:
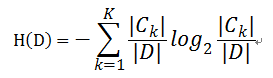
信息增益ID3
熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
前提:我们在构建最优的决策树的时候总希望能更快速到达纯度更高的集合。
根据公式:
信息增益 = entroy(前) - entroy(后)
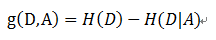
对于数据集D,其熵(entroy(前))是一定的,entroy(后)越小说明使用此特征划分得到的子集的不确定性越小(纯度越高),因此根据公式我们选择使得信息增益g(D,A)最大的特征A来划分当前数据集D。
信息增益比C4.5
信息增益比 = 惩罚参数 * 信息增益
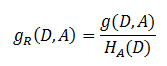
它是信息增益和特征熵的比值。其中的HA(D),对于样本集合D,将当前特征A作为随机变量(取值是特征A的各个特征值),求得的经验熵。公式为
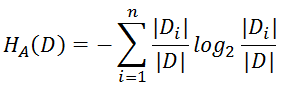
惩罚参数:数据集D以特征A作为随机变量的熵的倒数
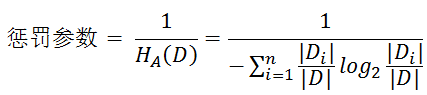
使用信息增益比:选择大信息增益比的特征。
PS:
ID3,C4.5是基于熵的,由于我们关注的数据输出的熵在知道一些特征信息后,一般熵会变小。变小的部分即为信息增益。直接取熵做比较的话无法反应特征和输出之间的关系。
基尼系数CART
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高
基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
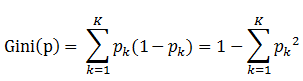
样本集合D的Gini指数 : 假设集合中有K个类别,则:
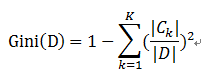
基于特征A划分样本集合D之后的基尼指数:
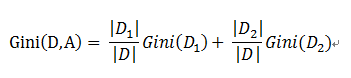
为了确定测试条件的效果,我们需要比较父结点(划分前)的不纯程度和子女结点(划分后) 的不纯程度,它们的差越大,测试条件的效果就越好。增益Δ是一种可以用来确定划分效果的标准:
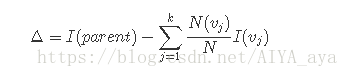
通常选择最大化增益Δ的测试条件,因为对所有的测试条件来说,I(parent)是一个不变的值,所以最大化增益等价于最小化子女结点的不纯性度量的加权平均值。
注意:对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值),然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
配合实例来了解一下以上三种特征选取方式
首先:例子引用于网络,计算过程为记录 自己编写。
假设我们是一家智能的租车公司,因此我们需要分析用户在什么样的情况下会用车,然后在用户可能需要用车的时候通过手机应用或者短信推送促销信息。那么我们要怎么分析用户的行为呢?可以交给计算机来做数据挖掘。
首先,我们可以从传统的租车公司拿到历史用户租车的记录,假设主要数据如下(局部引用)
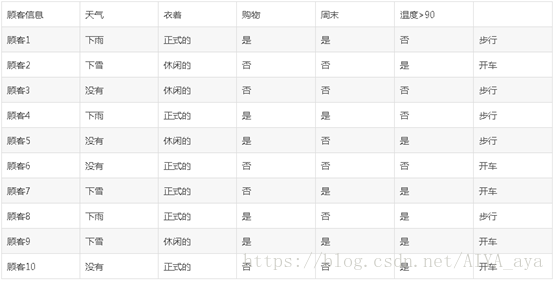
然后,我们构造一棵决策树(如下图)。

具体计算过程
现在根据以上三种方式,来划分数据集。
假设 我们要预测的结果是 用户开车与步行。即相关特征有天气,衣着,购物,周末,温度,5个维度的特征。
公式不好弄,直接截图了。要是CSDN能直接将WORD文件直接转存上来,保留原公式,符号该多完美!!
信息增益


3 再计算出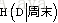
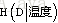 ,选择g(D,A)最大的特征作为划分点。之后进行第2个特征点选择,依次循环。
,选择g(D,A)最大的特征作为划分点。之后进行第2个特征点选择,依次循环。
信息增益比
如上3个表格 计算对应信息增益比:
信息增益比 = 惩罚参数 * 信息增益
信息增益g(D,A)已知,现计算特征HA(D)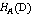
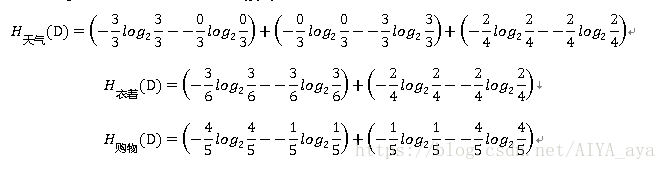
再计算出其他特征的熵,带入公式,选择信息增益率最高的特征。
循环划分
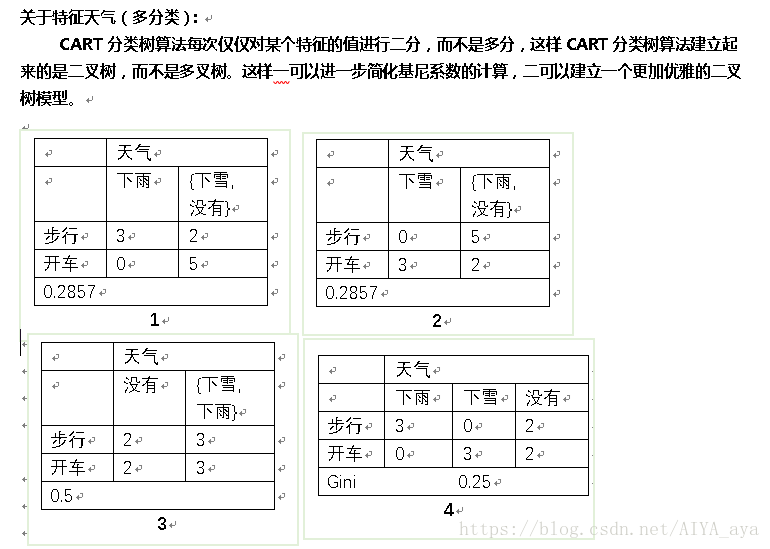
基尼系数
公式公式:
Gini系数增益:
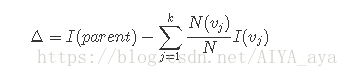
如上3个表格 计算对应基尼系数:
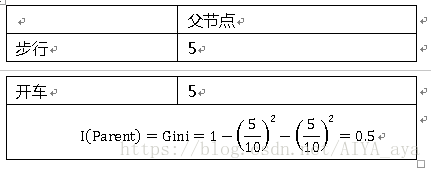
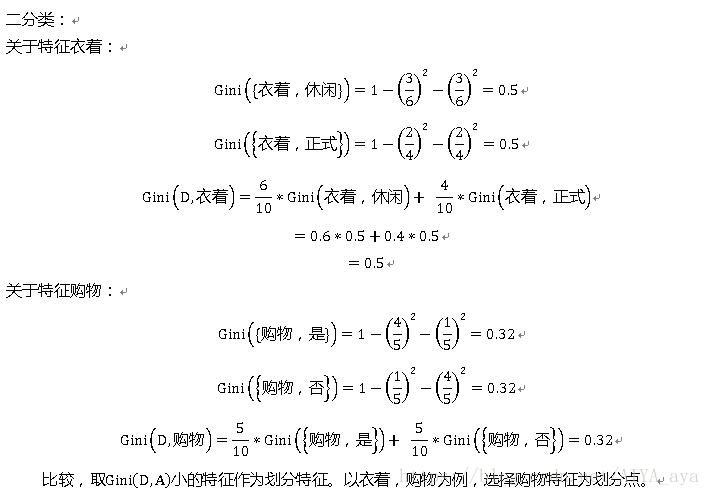
算法步骤(参考刘建平)
ID3算法的过程为:
1)初始化信息增益的阈值ϵϵ
2)判断样本是否为同一类输出DiDi,如果是则返回单节点树T。标记类别为DiDi
3) 判断特征是否为空,如果是则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
4)计算A中的各个特征(一共n个)对输出D的信息增益,选择信息增益最大的特征AgAg
5) 如果AgAg的信息增益小于阈值ϵϵ,则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
6)否则,按特征AgAg的不同取值AgiAgi将对应的样本输出D分成不同的类别DiDi。每个类别产生一个子节点。对应特征值为AgiAgi。返回增加了节点的数T。
7)对于所有的子节点,令D=Di,A=A−{Ag}D=Di,A=A−{Ag}递归调用2-6步,得到子树TiTi并返回。
C4.5算法与ID3过程相似,不同点在于选择特征的依据,ID3为信息增益,C4.5为信息增益比。
CART分类树算法:决策树的生成就是递归地构建二叉决策树的过程,对回归树用平方误差最小准则,对分类树用基尼指数最小化准则,进行特征选择,生成二叉树。
输入训练集D,基尼系数的阈值,样本个数阈值。输出是决策树T。
我们的算法从根节点开始,用训练集递归的建立CART树。
1) 对于当前节点的数据集为D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前节点停止递归。
2) 计算样本集D的基尼系数,如果基尼系数大于阈值,则返回决策树子树,当前节点停止递归。
3) 计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数
4) 在计算出来的各个特征的各个特征值对数据集D的基尼系数中,选择基尼系数最小的特征A和对应的特征值a(比如天气特征A和下雨a)。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,做节点的数据集D为D1,右节点的数据集D为D2. 以后的切分过程不再使用该特征。
5) 对左右的子节点递归的调用1-4步,生成决策树。
对于生成的决策树做预测的时候,假如测试集里的样本A落到了某个叶子节点,而节点里有多个训练样本。则对于A的类别预测采用的是这个叶子节点里概率最大的类别。
CART连续型数据特征处理:首先需要对数据按升序排序,然后从小到大依次用相邻值的中间值b作为分隔将样本划分为两组。小于b的数据集在左右,其他的在右边。依次计算基尼系数增益。所需要的时间为O(NlogN)
以上为例简述CART流程:
因为:
Gini(D,衣着)=0.5 Gini(D,购物)=0.32
Gini(D,天气{下雨,其他})= Gini(D,天气{下雪,其他})=0.2857
Gini(D,天气{没有,其他})=0.5
IParent是固定的,在几个特征中,特征天气A,下雨或者下雪(a)最小=0,所以选择特征特征天气A,下雨或者下雪(a)为最优特征,a为其最优切分点。由于根结点生成两个子节点,一个是叶节点,对另一个结点继续使用以上方法在其他特征中选择最优特征及其最优切分点。为了防止层级过深,CART有剪枝过程,停止过度分裂。
算法的停止条件为:结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征。