RMPE: Regional Multi-Person Pose Estimation
ICCV2017
Code is based Caffe and Torch!
https://github.com/MVIG-SJTU/RMPE
https://github.com/MVIG-SJTU/AlphaPose
多人人体姿态估计本文解决思路: 多人检测+单人人体姿态估计 Faster-RCNN + SPPE Stacked Hourglass model
对 SPPE 进行了改进,引入了 三个模块: Symmetric Spatial Transformer Network (SSTN),
Parametric Pose Non-Maximum-Suppression(NMS), and Pose-Guided Proposals Generator (PGPG)
多人人体姿态估计目前主要有两类方法: two-step framework 和 part-based framework
two-step framework:先将每个人检测出来,用矩形框框出来,然后对每个人独立的进行人体姿态估计
part-based framework: 首先将人体 body parts 全部检测出来,然后 组装这些部件形成多人姿态估计。
这里我们采用 two-step framework:Faster-RCNN + SPPE Stacked Hourglass model,下图显示存在的问题

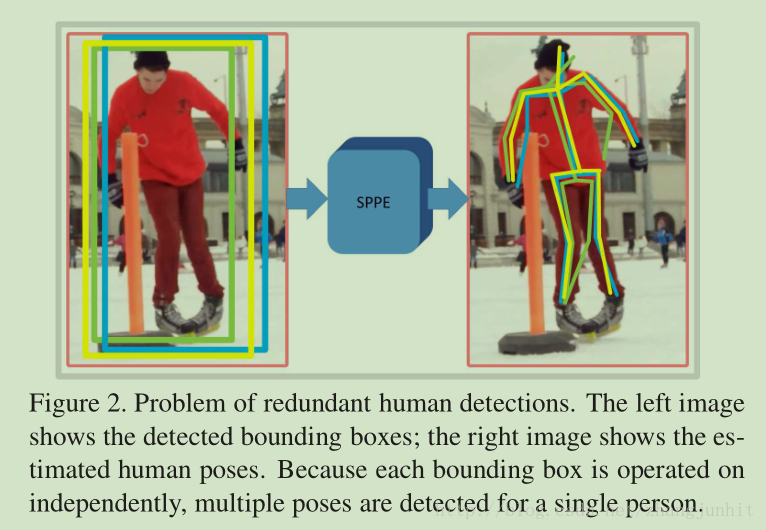
主要的问题有两个: localization error problem 和 redundant detection problem
SPPE 对于矩形框位置误差很敏感。SPPE 对每个矩形框都会产生一个姿态,所以重复检测导致了冗余姿态
为了解决上述两个问题, 我们提出一个 regional multi-person pose estimation (RMPE) framework
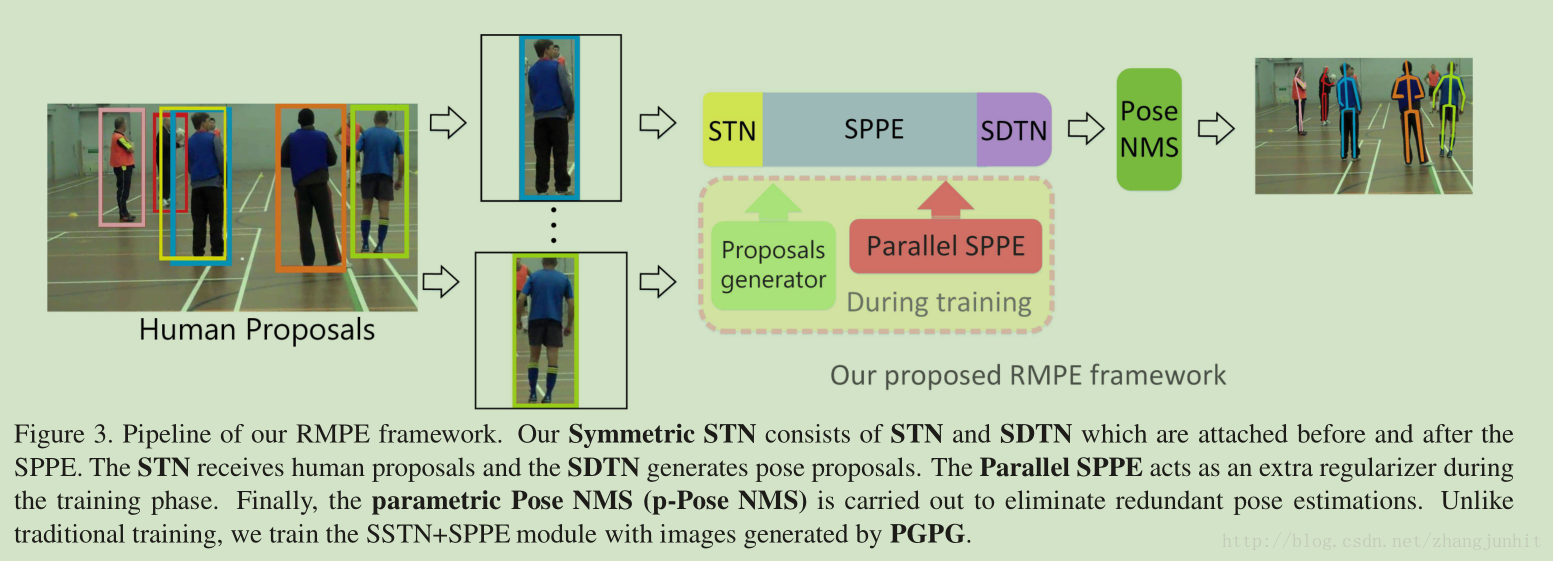
3 Regional Multi-person Pose Estimation
首先用人体检测器得到 human bounding boxes, 可以用 SSD 或 Faster R-CNN。然后将这些人体矩形框输入 “Symmetric STN + SPPE” 模块,自动输出 pose proposals,对这些 pose proposals 我们用 parametric Pose NMS 微调得到 最终的 人体姿态估计。
在训练阶段,我们引入 “Parallel SPPE” 来避免局部最小值,提升 SSTN 性能。The Parallel SPPE acts as an extra regularizer during the training phase
为了增强已有的训练样本,我们设计了 pose-guided proposals generator (PGPG)。
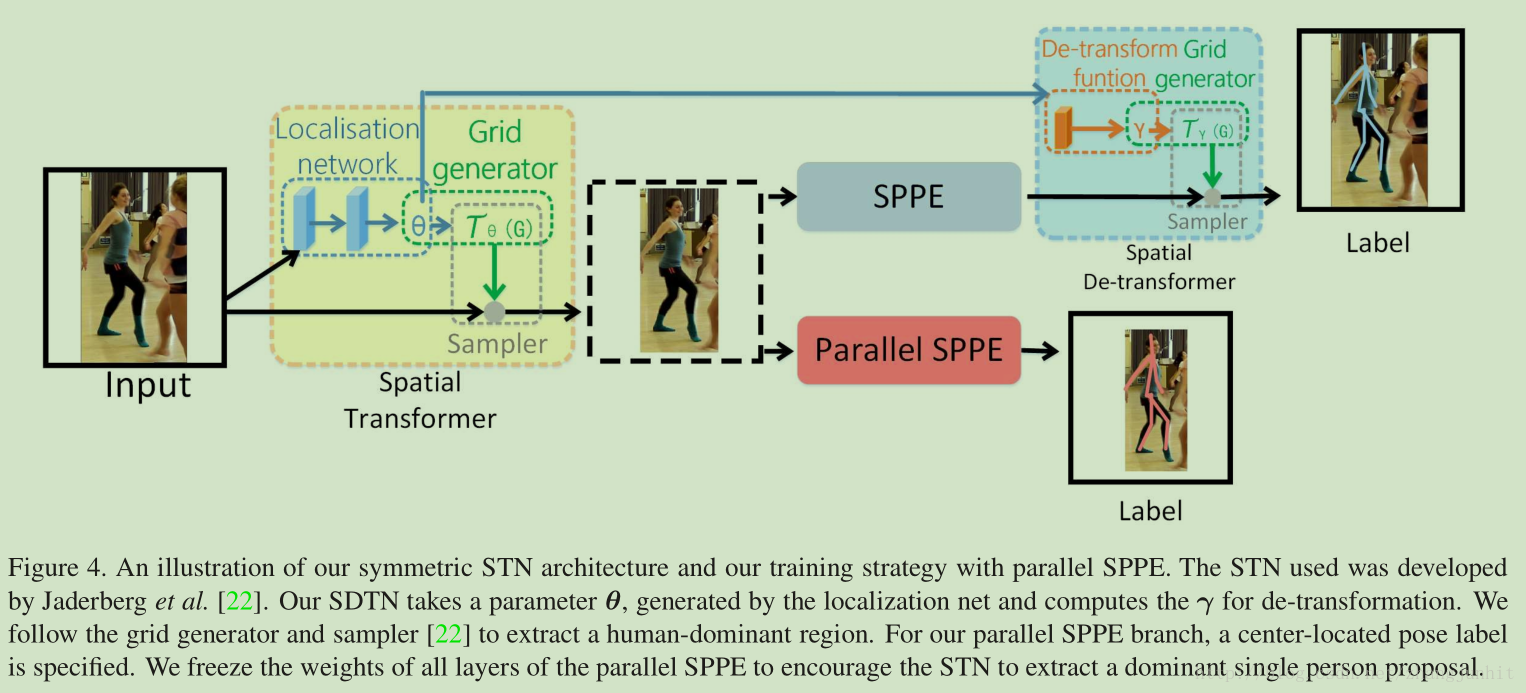
3.1. Symmetric STN and Parallel SPPE
由人体检测器得到的单人矩形框作为 SPPE的输入不是很合适。这是因为 SPPE 是针对单人图像训练的,对人体定位误差很敏感。实验中发现单人矩形框小的平移或裁剪对SPPE的性能影响很大。我们引入 对称STN+平行 SPPE 来提升SPPE的性能,减少单人矩形框小偏差的影响。
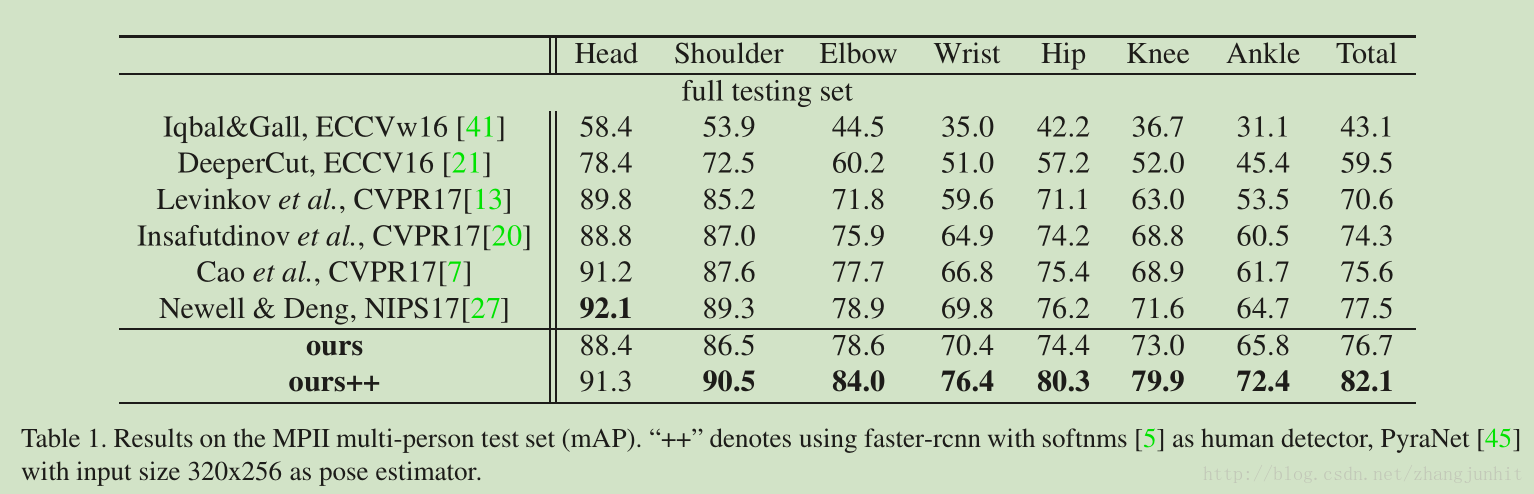
4 Experiments

11