上一讲的答案,0这题是真心不难,就是复习了一下easygui。




点No。结束程序。

如果一开始点Cancel,
点yes,程序就结束了。其他功能你们可以自己去验证。上面中有一个地方我们没有见过,就是os._exit(0),以前只介绍过sys.exit(0),那么它们有什么区别呢,里面的0是什么含义?下面就来说这个事情。参考了https://blog.csdn.net/geekleee/article/details/52794826。


我们在上面这段代码里实验一下,我先说好哈,我这里其实是刻意写的结构,只是为了让大家学习一下两种exit()的方式而已,不是说非得那么写,后面就会看到别的写法。我们也来看一下python文档是怎么说的。

在python里先试一下。看到os._exit(0)直接Restart了IDLE这个SHELL。


在原来的程序上改一下

发现程序是ok的,还是可以运行的,目前来说,我们只需要知道给os._exit()一个整数就可以,至于这个整数的不同会有什么区别,后面可能会讲到。如果是用sys.exit(0)会如何?先在python里看一看文档。和上面说的基本一样。参数默认是0,一般非零的都在1到127,如果System Exit异常被捕获,异常处理except后面的语句就会执行。但是这个arg也可以不是整数。


所以可以想象如果把上面改为arg会出现什么现象。


点Cancel
点Yes,

显然是不对的。以前没有出现时因为用的python3.4,上面也写了python3.6时有改动的。因为这个SystemExit被捕获了,然后就跳到异常处理里面了。解决方法其实有很多。下面给出几种。第一种是指定异常类型。

第二种,让sys.exit()或者raise SystemExit(知道了上面,其实也可以用raise SystemExit,sys.exit(0)本身就是引发这个一个异常)不在try里面。

第三种,上面有了,可以用os._exit(0)。你们都可以试试,可能方法有很多。退出就像补充这么多。
1.这个登陆就必须用到cookies什么是cookies呢?可以参考下面的网站https://www.cnblogs.com/yanganok/p/5322411.html

我觉得学编程的不会英语是不行的。


也就是cookies存的是客户端的一些信息和状态。再Network里点一个事件就会对应一个cookies。



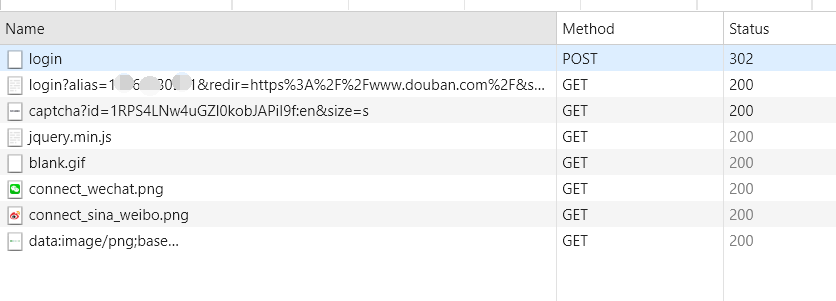
我们还得看一下豆瓣,知己知彼才行嘛。成功登陆豆瓣之后,就会在Networks里出现以下的事件,点第一个login进去。

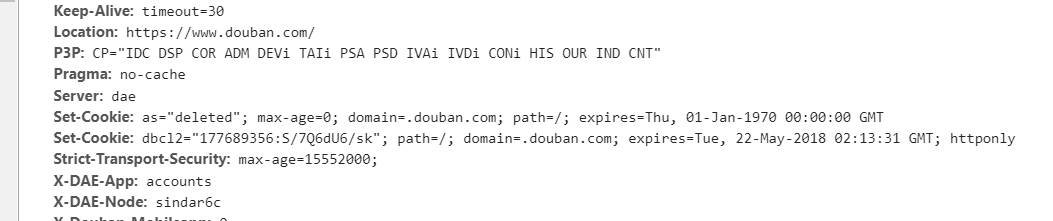

from data里面是我们的用户名和密码信息。

下面那个captcha就是图片验证码里面的内容,captcha-id是图片的一个标识。如果没有注册,会这样

但是要想登陆豆瓣这些知识还是不够的,我反思了一下,这道题确实拿出来太早了,暂时先不给答案,等到把所有的预备知识都介绍完了,再给出答案。下面开始本节的内容。
瞒天过海
前面曾经说过这么一件事

如果你是用python访问的网页user agent 会显示你电脑上python的版本号,有些网站就会有烦爬虫的机制,看到这种就会把你屏蔽掉。那么我们就没有办法了吗?呵呵,那就太小看python爬虫的功能了。我们是可以改user-agent的内容的。下面就是如何去改headers 里面Request headers里的user agent。

这里重复一遍上一讲其实也说过的内容。

也就是user agent是我们发送给服务端的,那么我们自然是可以修改的了。在哪里修改呢?
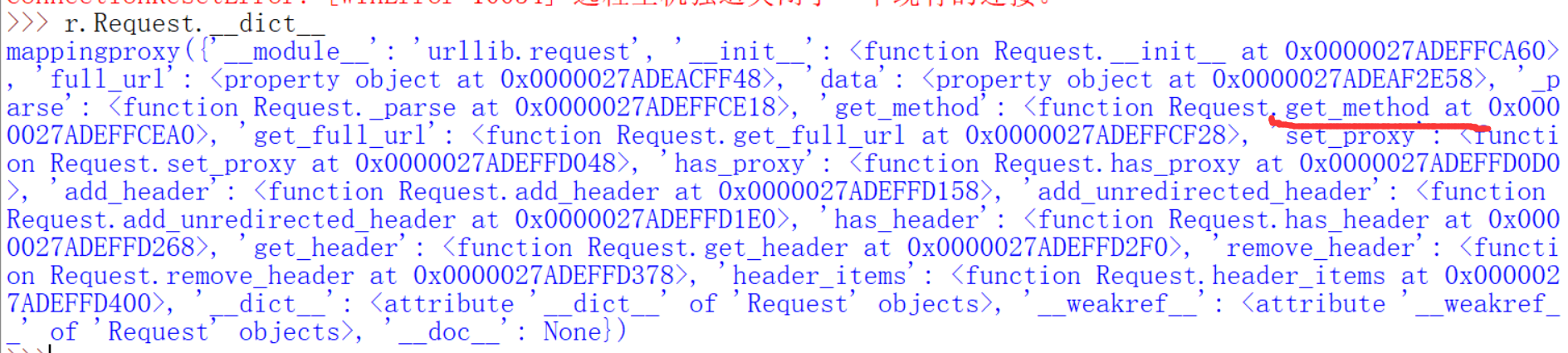
我们来查看一下上一讲说过的一个Request的参数,Request和urlopen的关系前面也说过了。
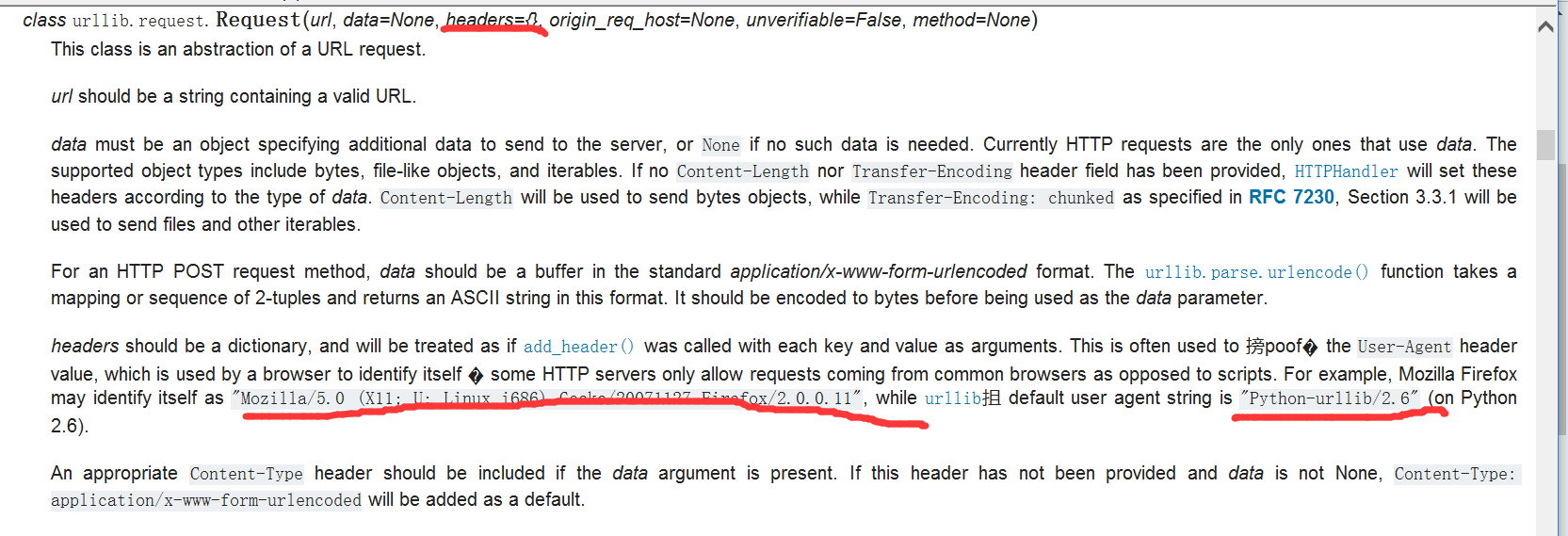
说这个header是一个字典,你也可以用add_headers函数去加字典的内容,通常用来修改user-agent来欺骗服务端,如果你用python去访问网站,默认的user agent就是python的版本号(在python2.6是这样子的,现在看到了headers默认的参数是空的)。也就是有下面两种方法:

知道了如何修改下面就来实际操作一下,还是用下载猫片的那个程序。为了让外部可以访问url,我把它设为了全局变量

如果不修改user agent我们运行一下

其实也容易理解,因为前面的文档哪里默认的headers是空的。还有如果用上面的程序,一定要在输入宽高的地方点ok,不让程序没有运行到url就退出了,就会这样。

下面就来修改试一试。第一种修改方式:


第二种修改方式:


为什么不对呢?其实是因为格式问题,add_header格式如下,前面的Request指的是Request类的实例,上面的url就是



但是你也不要把别人当傻子。如果你一个ip地址短时间连续访问同一个网站,谁都可以看出来有异常啊,比如说你去看图片,几秒钟一个很快了,但是爬虫一秒钟就下载几百张甚至几千张,这不符合常理啊。所以会有一个频率的限制,如果频率太快,一般的做法是给你一个验证码,让你去填,当然现在很多网站都升级了,比如12306,前几年各种选出下列的败犬啊,等等。。。当然还有现在的拼图验证,因为简单的数字和字母现在通过一个机器学习识别太简单了,就不能识别是不是人类访问了,以后有机会会讲如何用机器学习智能填写验证码。如果你没有在一定时间内填写正确的验证码,那么就不管你的user agent了,直接拒绝你的ip访问。那么我们又该如何应对呢?一般有两种(上面机器学习的方法对一些验证码来说当然算一种,除了这种)。
第一种:延时请求
这种其实很简单,只需要用一个time模块里的sleep函数,来看一下这个函数的功能

就是一个延时函数而已,输入的是秒数,这样可以降低你代码执行的频率,你可以在每次循环的最后加一个time.sleep(1)来延时一秒才进入下一次循环。这个你们自己可以试一试。但是这样做效率太低了。于是我们有第二种。
第二种:使用代理


怎么看你访问网站的ip呢?下面这个网站可以告诉你
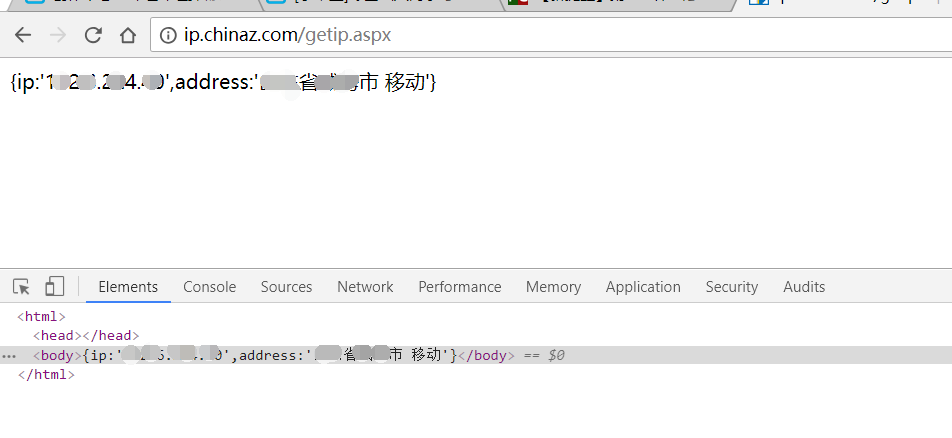
下面知识稍微科普一下ip的内容



使用代理的步骤如下:

这里涉及到了opener,下面是关于上面几个函数的文档





简单解释一下,其实前面学过的urlopen是一种默认的openerdirector.open的方式而我们现在url.request.build_opener()就是定制一个你自己的openerdirector实例

urllib.request.install_opener是一劳永逸,今后你的程序中的urlopen都会被比如上面的a.open()代替,而如果你只是偶尔用一下就用a.open这种方式,一般都是用后面的方式。
知道了上面这些,实际操作一下。先不使用代理。

下面再使用代理试一试,代理ip也好找。

那么下面就来试一试用这些代理ip。
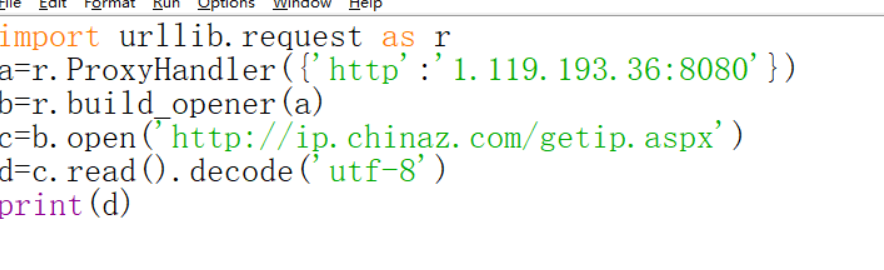

有时候会出现上面的情况,也很正常。多试几个ip,或者把ip加到一个列表里面,随机取一个。多运行几次,我试了一下,反而,美国,香港的代理ip成功率高。



下面简单介绍一下random.choice函数

从非空序列里面随机选出一个元素,注意一定是序列。
下面是一些补充:



这里还是用爬取猫的程序。


课后练习(答案还是老样子)
0

这道题个登陆豆瓣的其实一样,之所以不讲其实是因为还没有介绍正则表达式。想提前学习的戳http://bbs.fishc.com/thread-57073-1-1.html。
1
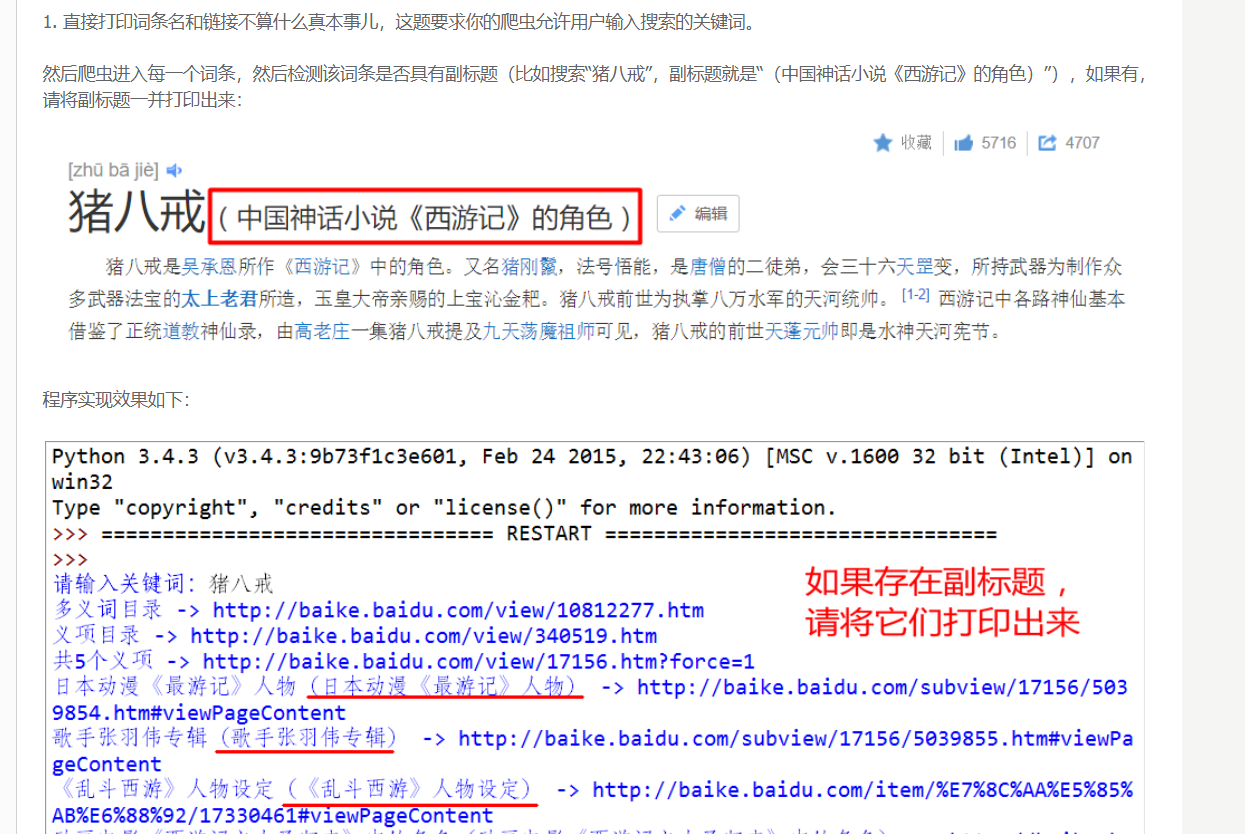
2


提示:不要忘记生成器。