有人可能不知道怎么样来审查某个具体图片或者文字的元素。我来演示一下,你想审查那个图片或者那段文字其实很简单,以豆瓣为例。只需要右键,检查,就可以了。

还有一点想补充一下,就是join和+拼接字符串的问题,join的效率是要比+高的。我们可以来看一下时间。

可以看到join的时间是要短的,这还是拼接数量太少,不然差距更加显著。实战固然重要,但是回归书本也很重要,这一讲在前面实战的基础上,我们回归到知识点的讲解上来。毕竟理论->实践->理论->实践,如此循环往复才是最好的学习路线。
正则表达式特殊符号及用法
参考了http://bbs.fishc.com/thread-57691-1-1.html。前面我们已经用过很多次正则表达式的特殊符号了,但是还是有一些没有涉及到,这一讲就让我们做一个了解和总结。

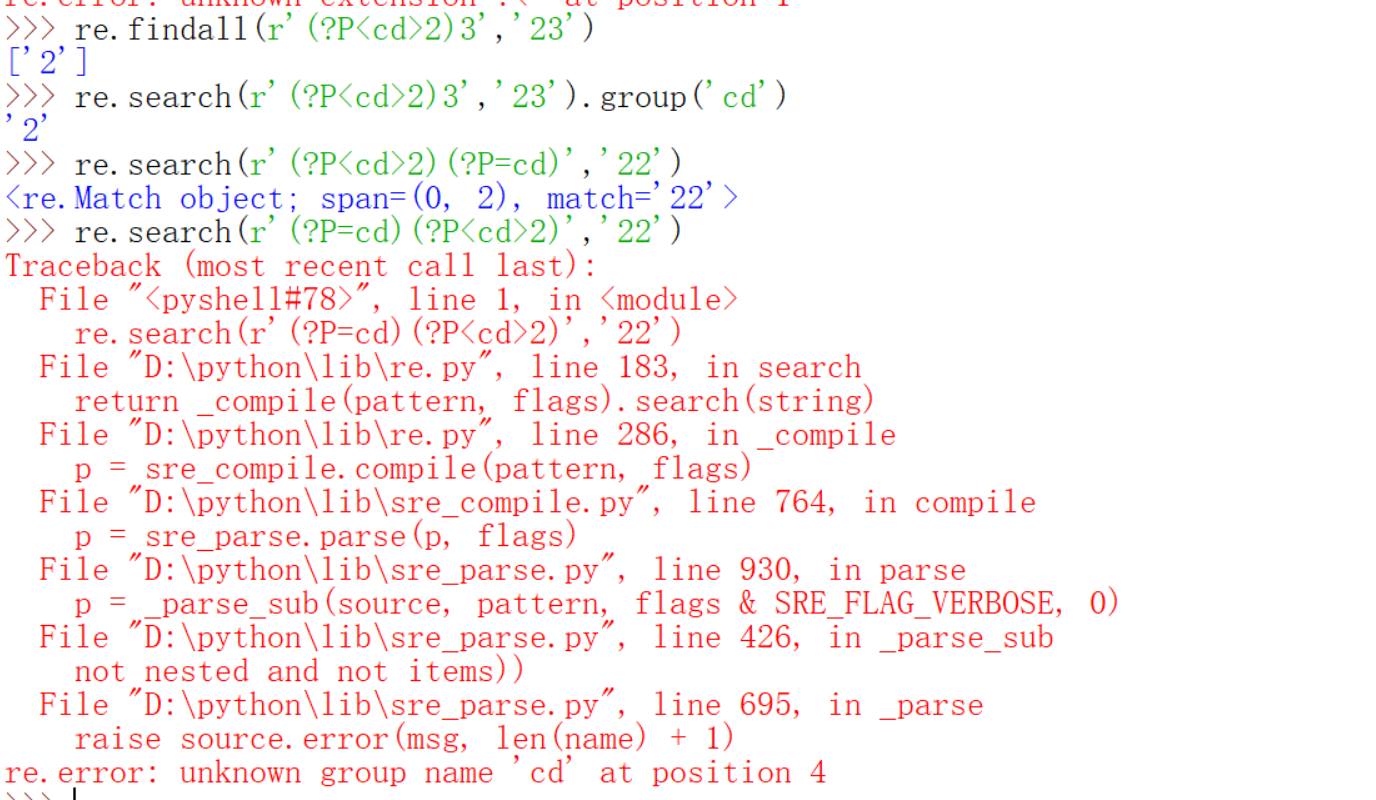
先来看看这张图上有什么我们前面没讲过的。.,^,$用法的2,\用法的3,[]的全部,还有非贪婪模式的说明都在下面的代码里体现。如果有两行紧邻着都是代码,那么说明上一条代码的结果是None。比如re.search(r'.','\n')返回的结果就是None。试了一下,感觉是$有没有re.MULTILINE的结果都是一样,这个multline就是多行的意思嘛。
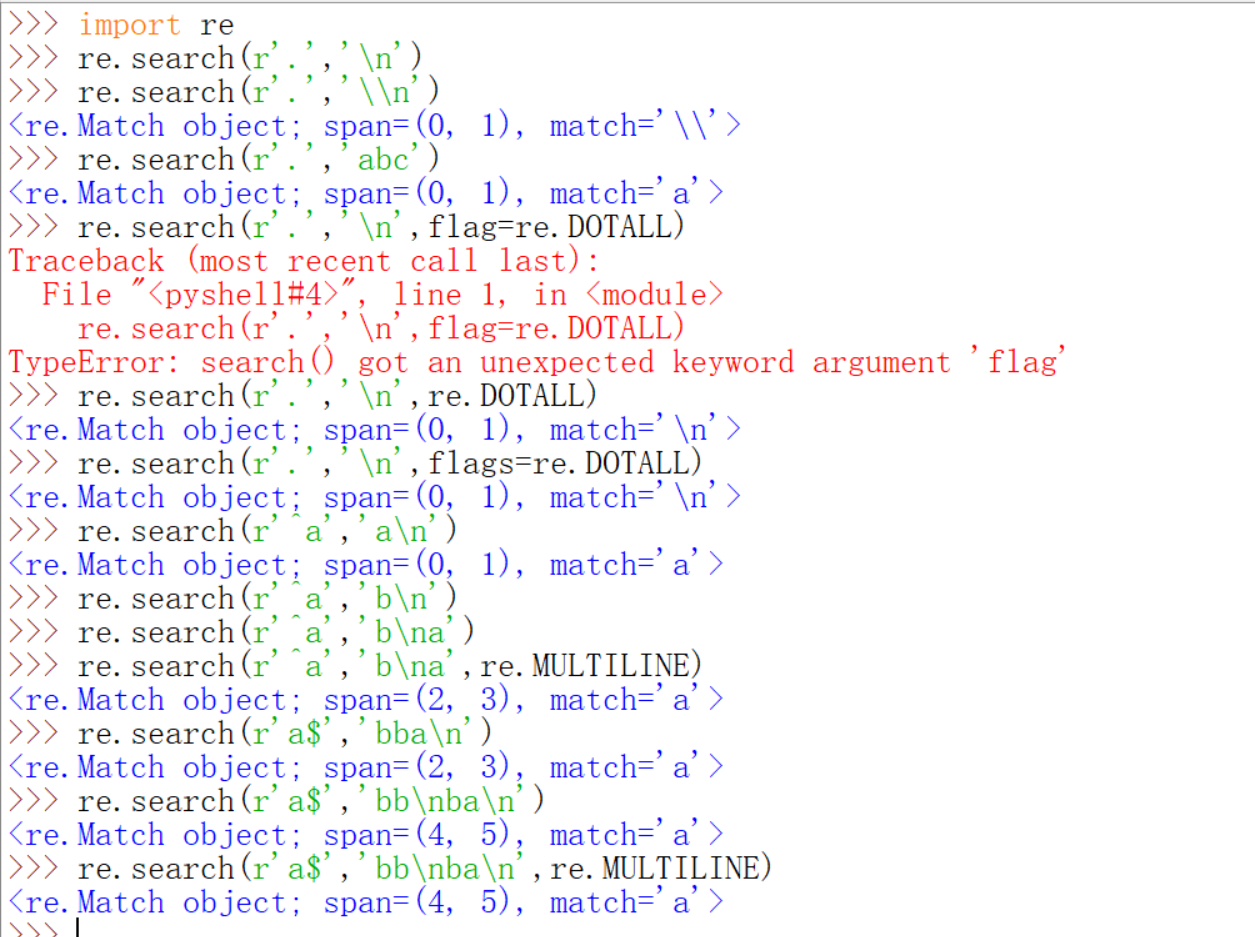
我这里再提醒一下,|的问题,下面举了一个例子,如果你想匹配aaa或者aab,不加括号和加括号的不同。下面还有\用法3的例子,\的用法3还是很有意思的,上一讲已经提到过()代表的是子组,一般不需要你自己去编序号的,都是利用的从1开始的自动编写序号。从左到右,子组序号递增,看不懂的下面都有例子的,用group()可以获取到子组的信息,group(序号)则会返回特定的子组,groups会把子组作为元组的元素返回。re.findall返回的是列表,如果正则表达式的pattern里没有小括号,则把整个匹配到的结果返回。

如果pattern里没有子组的时候,re.search.group返回的是整个结果。\1代表的就是第一个子组,依次类推。下面的例子里r'(a)(b)\1'就相当于r'(a)(b)(a)',因为第一个子组是(a),其他的也都可以理解了,如果调用不存在的子组会报错。
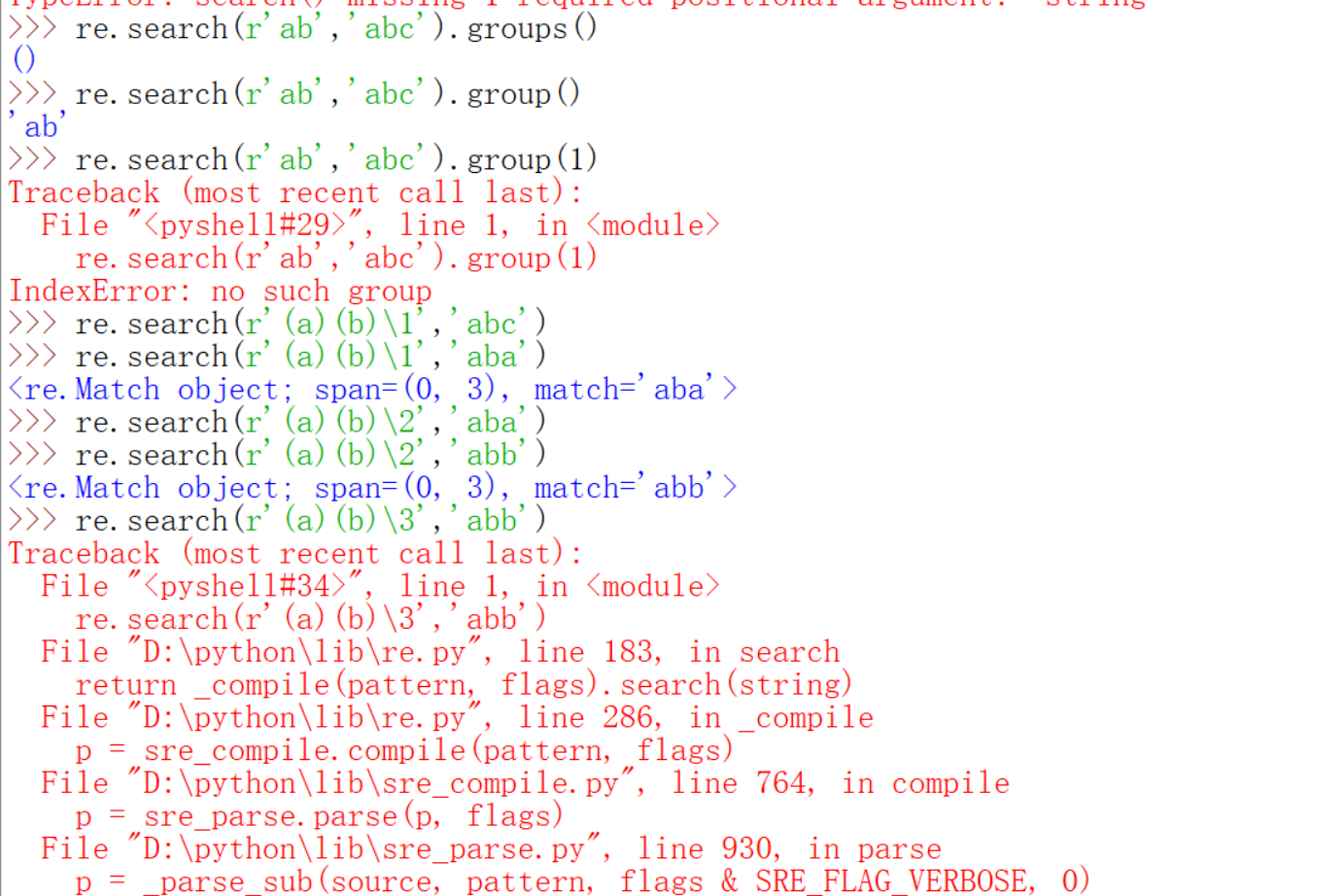
错误原因是子组引用错误,另外,子组必须出现了才可以用\序号引用,下面的例子r'(a)\2(b)'的错误就是因为还没有出现第二个小括号(子组)就用\2引用了。

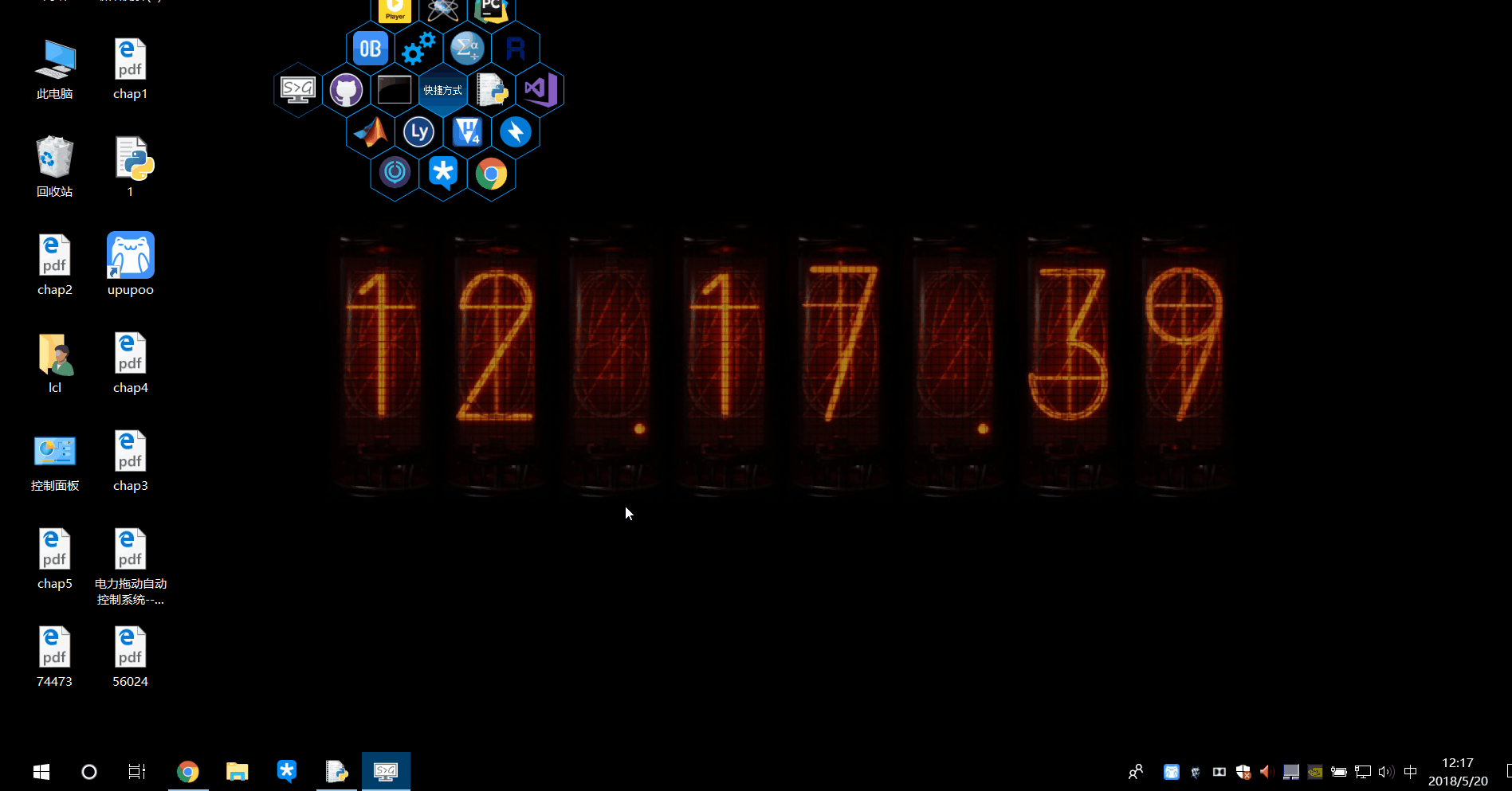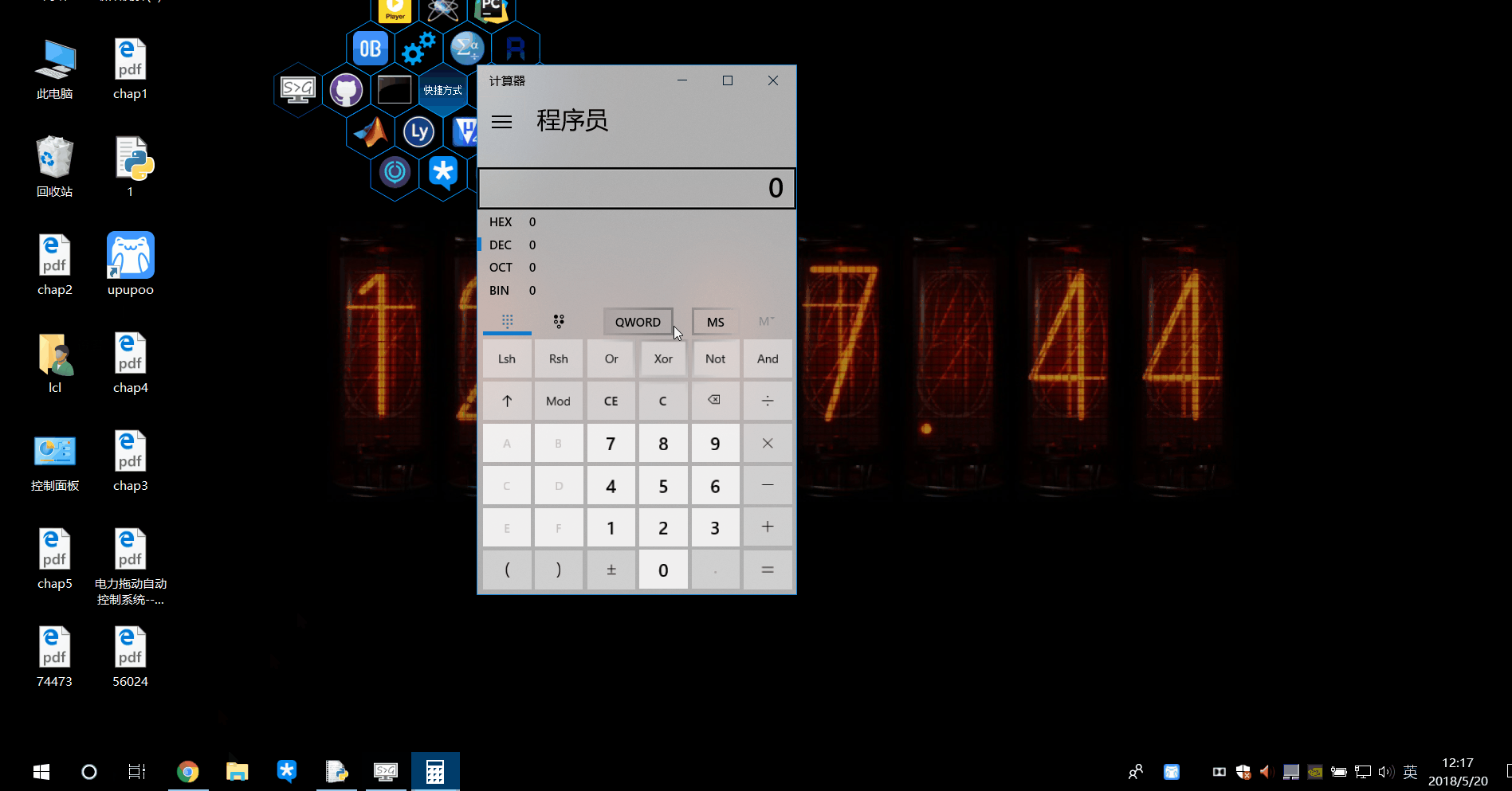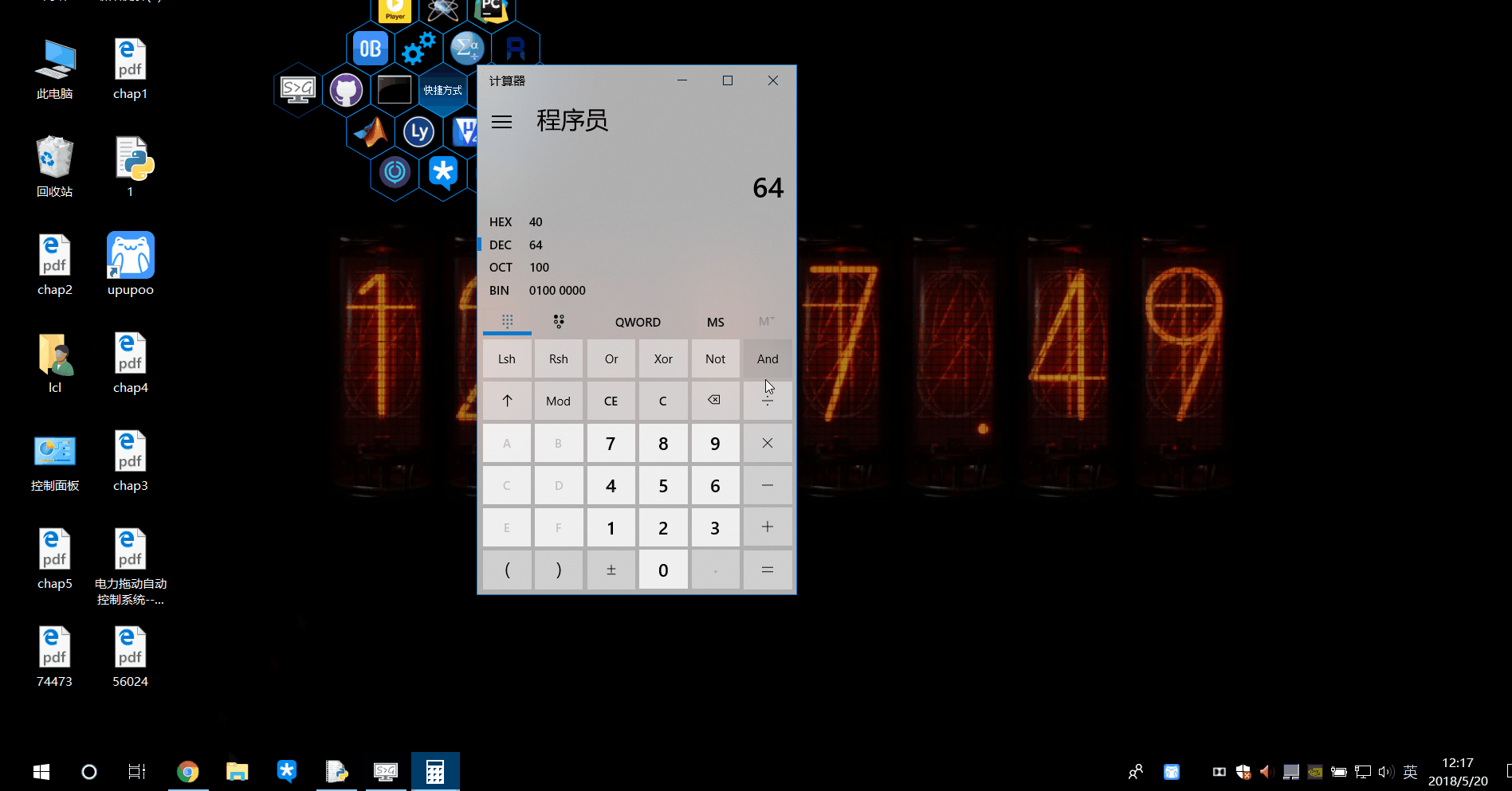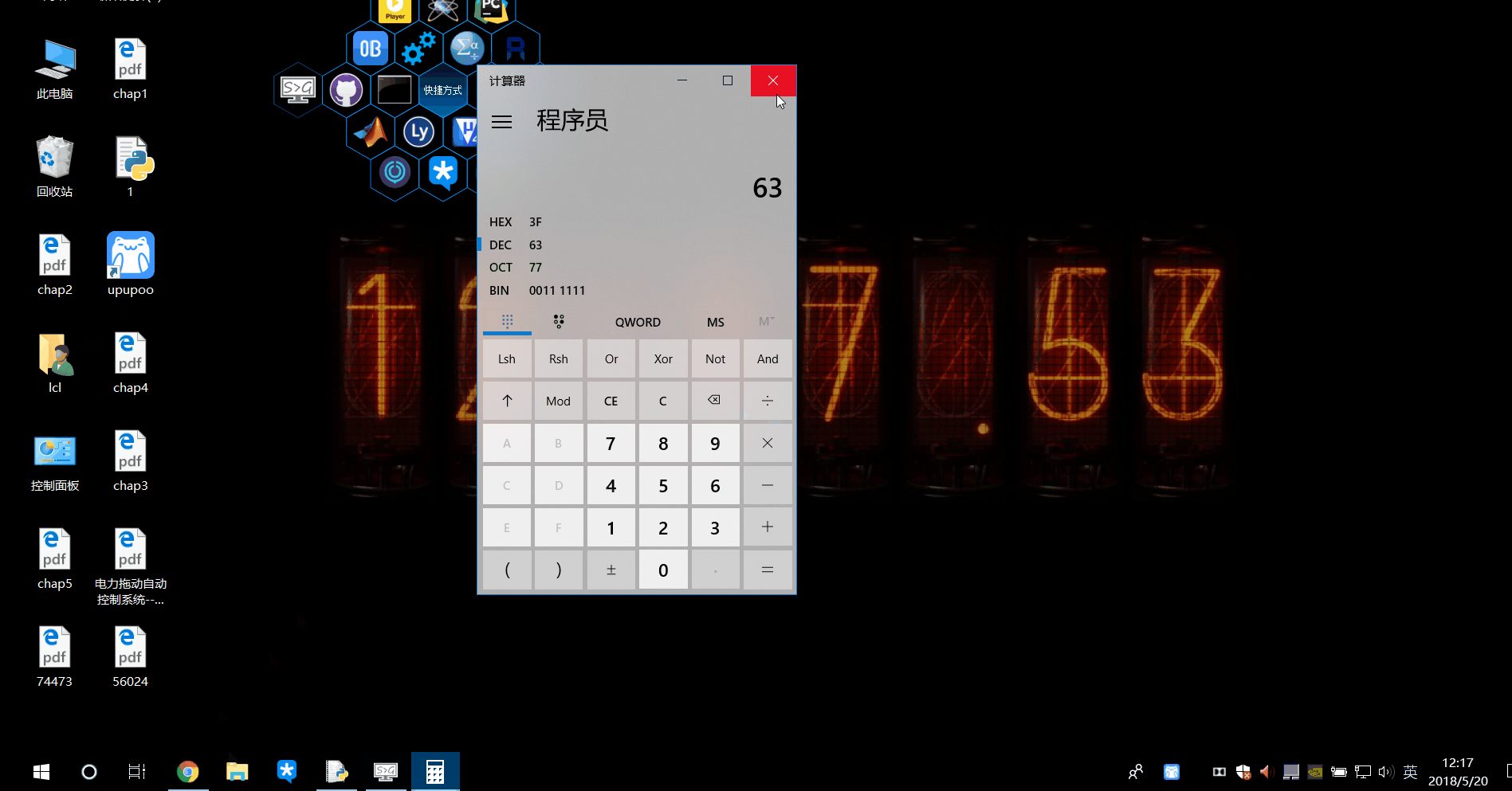
但是\序号表示子组的方式,后面的序号只能在1-99之间,这是因为\还有一种情况,如果后面的第一个数字是0,那么\0XX代表的是整个八进制对应的ascii码字符,后面的数字如果超过了100,我们不写0100而是省略0,直接写100。举个例子,@的ASCII码是64d,d代表十进制,八进制就是100那么\100就代表了这个@。?的是十进制是63,八进制是77,如果直接\77会报错,而\077不会。

还有[]的用法,以前没有讲过的是-在[]里如果是在开头,表示的知识匹配-,而不具有表示范围。.+?*$字符均作为普通字符匹配,不具有元字符的意义,而^只有在第一个字符才是除了的意思。下面都会有例子。关于非贪婪模式或者说懒惰模式前面也有介绍,前面说到必须是以?结尾的,其实是不对的。



看到+?确实是一种懒惰模式,这上面里面唯一不能理解的就是re.search('\d+?b','223b')的结果,因为如果按照懒惰的设想,应该返回的是'3b',那么看来这中懒惰模式还是要尽量包含左边的字符,或者说,下一个匹配规则的边界是由上一个决定的,如果像这种第一个就是\d+?的话,就尽量包含左边的字符,而对右边的字符采取懒惰态度,贪婪模式的匹配原理是相当于从右边开始匹配,一直到最左边,而懒惰模式是从最左边开始向右找,尽可能少的包含字符。下面就再来用代码看看。另外上面匹配\的代码打错了,补充在下面,报错的理由应该是如下。

并且要想匹配的话应该是如下做法,在下一张图里面,另外$有没有re.MULTILINE的设置结果是不一样,上面只是没有想到合适的例子,也在下一一张代码图里体现。
零宽断言

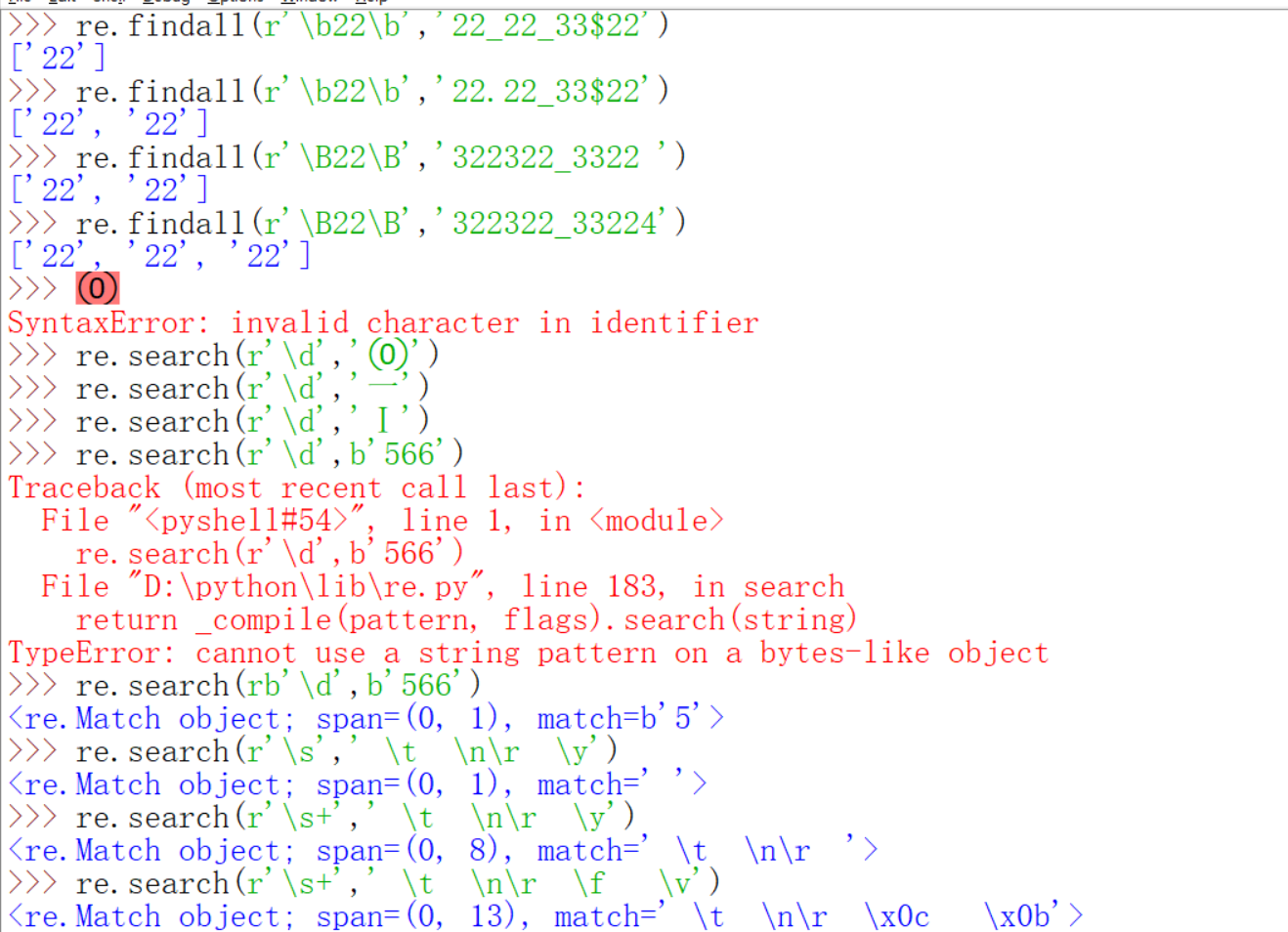
零宽断言这个词第21讲就出现过,不过害怕你们被这个词语吓到,就没有进行讲解。现在经过一番实践过后,相信你们应该可以理解下面的内容了。什么是零宽断言呢?就是、像^,$,\A,\Z,\B,\b这样的只是用于定位,而不占用匹配字符的转移字符。^,$已经将结果过了,下面对\A,\Z,\B,\b进行讲解。上面表格里写道\A也是匹配字符串开始位置,\Z匹配字符串结束位置。那么有什么区别呢?它们的唯一区别在下面也有体现,就是\A和\Z不受re.MULTILINE的影响,仍然只匹配字符串的开始结束位置。\b是匹配单词边界,注意这里面单词的定义,字母,数字,下划线都被看做是单词内部,而其它字符作为单词边界。\B则正好相反,\B的边界就是字母数字和下划线。

第一个re.findall为什么只返回了两个22呢?因为_并不是\b的边界,所以中间的22美有返回,而.和()还有开头和结束都算。第三个re.findall呢?\B的边界正好是\b反过来,也就是说\B的i边界还不包括开头和结束,所以说只返回了两个22,最后的22由于在最后没有返回。第四个re.findall开头的22也没有返回。下面又验证了上面所说的。关于\d,\w我们前面都用过(除了0-9我暂时不知道什么叫做其他数字字符),其他模式也不怎么常用,注意的就是\w可以匹配unicode字符,包括各国语言,数字和下划线。\t是tab键,叫做制表符,\n\r是windows里的回车,\f是换页符,\v是垂直制表符,另外呢\b是退格,但是当\b出现在正则表达式的pattern里,也就是我们写的r''里的时候,也就是re.search的第一个参数里,它的意思就是字母边界,只有当\b出现在字符串里,也就是re.search的第二个参数位置里时,意义才是退格。下面就只简单举几个例子。还有就是bytes模式时,pattern也要是bytes类型的,所谓pattern模式就是re.search的第一个参数。

上面的我好理解的和没有问题的我就不演示了,只演示几个有问题的。
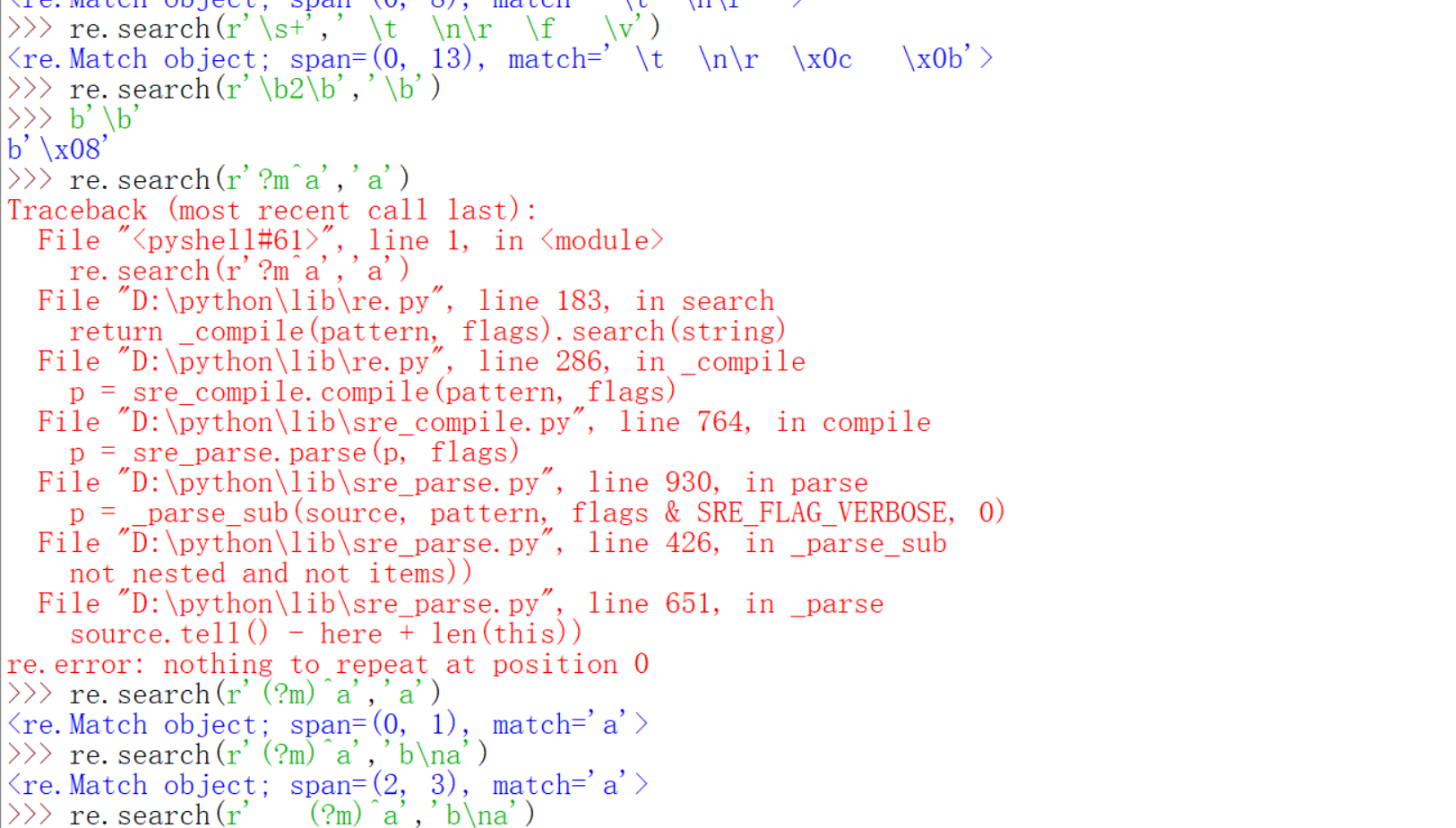
(?m)表示flags的时候前面不可以有空白符。

(?:exp)exp时要匹配的字符或者说模式的作用只是不给exp分组而已。(?P<name>)
中的name不要加引号,但是调用的时候要加。(?P=name)和\加1-99的数字很像。
下面几个看看理解一下,可能再很复杂的场合用得到,那时候会过来找就行。还不是很懂得话,去http://bbs.fishc.com/thread-57317-1-1.html这里看看。

关于零宽断言呢?我这里再给一个小例子说明扩展得作用很大。


这点东西以后可能会用到得。那么就稍微来解释一下,.*[.](?!bat$).*$的意思,.*就不用说了[.]是为了消除.的特殊功能,当然你\.也可以。然后就是这个零宽断言,?!是前向否定,后面加一个$是因为我们只想排除.bat的,而不能把例如.batch的也给排除了,由于是否定,如果小括号这个地方匹配成功,则整体就失败,如果这个地方匹配不成功,就继续匹配后面的.*$。还是来实际感受一下比较好。

编译正则表达式

编译完成之后就得到一个特定的正则模式对象,然后我们可以实现匹配。

先初步看一下这几种方法,match和finditer对我们来说时新方法。

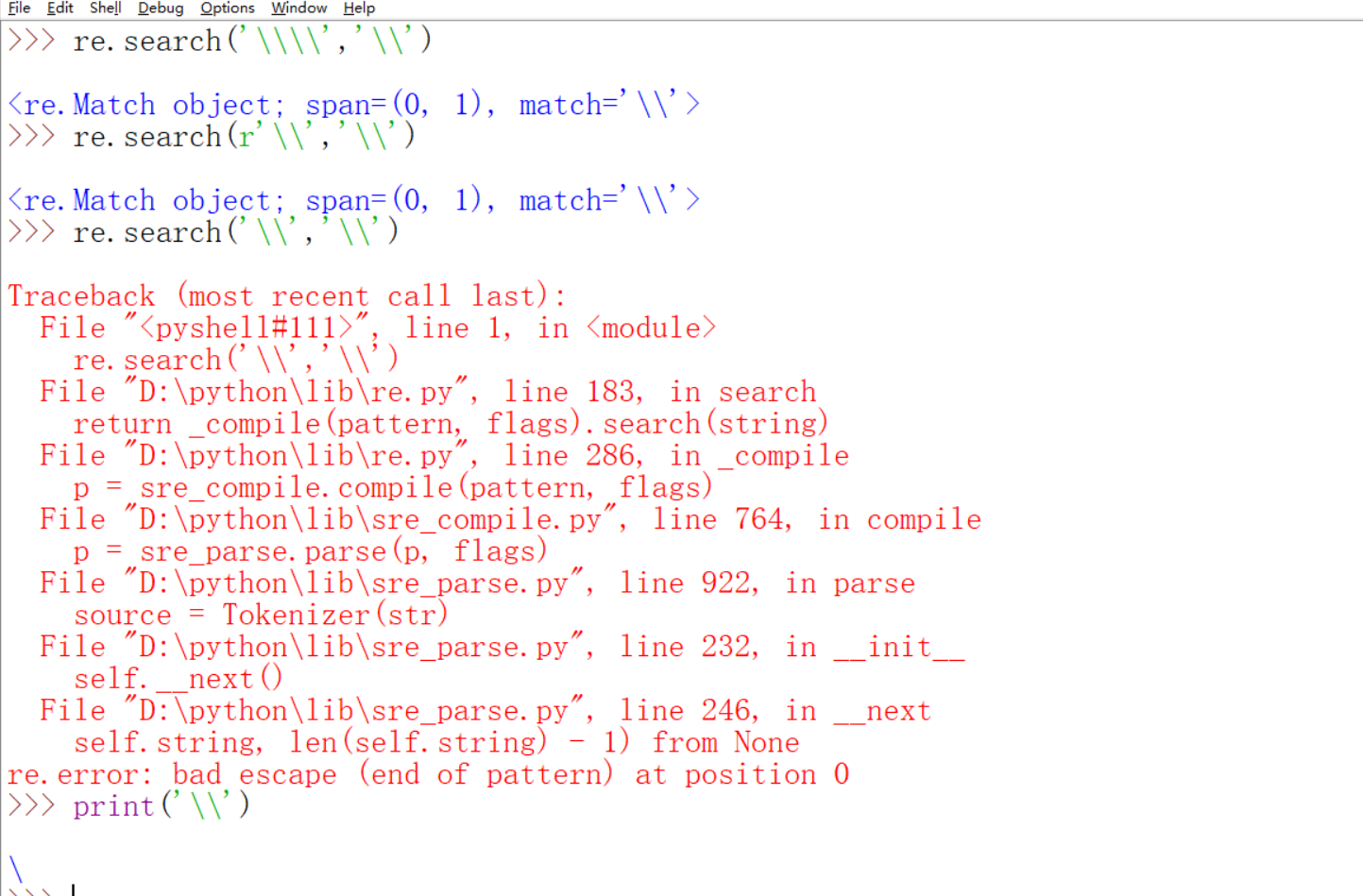
在详细介绍match和finditer之前,我们先再来详细体会一下为什么pattern前面都要加r。这主要还是\可以反义的功能带来的锅,我们早就知道python里表示一个反斜杠需要前面再加一个反斜杠进行转义即\\代表一个\。在正则表达式里面呢?它同样有反义功能,例如\.表示匹配一个点。所以你可以想到如果像匹配一个python字符串里的\需要正则表达式里的4个反斜杠对吧。

下面就来说一说match和search的区别。前面也已经写到match只能检查在正则表达式的起始位置匹配,search就不一样,所以match如果有返回值,那么起始位置一定是0,search则不一定,它是遍历整个字符串,然后返回第一次匹配到的结果。findall和finditer呢?上面已经看到finditer返回的是一个迭代器。findall返回的是一个列表。
如果列表很大,迭代器更具优势,你可以想象列表太大,电脑很卡的场面吧2333。

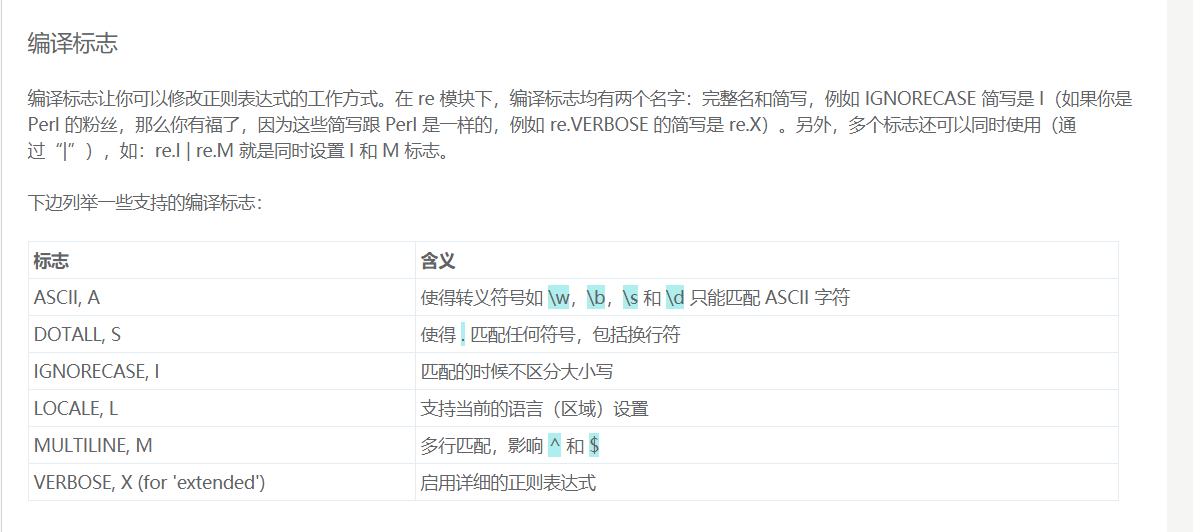
下面介绍的其实很早就介绍过,称为编译标志,也就是flags。有两种写法,后面是简写。例如ASCII简写为A,
讲几个前面用的少的。


还有一些小知识点。直接用re.search也就是模块级别的方法和先用a=re.compile得到一个模式对象,在用a.search还有有不同点的。不同点在哪里呢?我们直接去看官方文档。(match,findall,finditer是一样的)

重点看参数就可以了。pos是代表匹配的起始位置.endpos是结束位置,这是模块级别的search方法所没有的。另外呢?除了re.search返回的对象除了有group方法之外,还有start,end,span等方法,还有呢?子组其实是可以嵌套的,而且groups可以传入多个参数。ps:group,start,end,span这些方法只有search和match才有。

用正则表达式来修改字符串
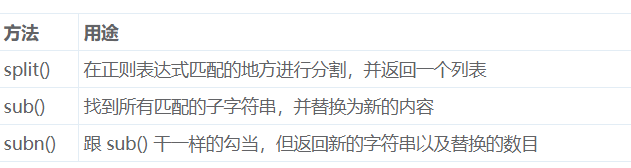
前面讲正则表达式都是讲的如何查找和搜索,并没有讲如何去修改字符串,还记得字符串修改的一些方法吗?不记得的可以戳http://bbs.fishc.com/thread-38992-1-1.html。下面介绍的是用正则表达式来修改。参考了http://bbs.fishc.com/thread-57362-1-1.html。有以下三种方法

split看起来和字符串的基本一样,maxsplit是最大分割次数。上面显然说的是对象级别的方法,那么有没有模块级别的呢?也就是re.split呢?我们去看看。


有没有rsplit呢?没有,也就是说从右边开始分割是正则表达式直接做不到的,虽然你可以先把字符串倒过来再split,但是这不是直接的方法。下面就实际操作一下。需要说明的是如果你对分割符也感兴趣(因为有些分隔符是你用类似\w这种通配符来定的),你可以把它括起来作为子组返回。sub是返回一个字符串,这个字符串从最左边开始,所有 RE 匹配的地方都替换成 replacement。如果没有找到任何匹配,那么返回原字符串。可选参数 count 指定最多替换的次数,必须是一个非负值。默认值是 0,意思是替换所有找到的匹配。subn返回的是一个元组,第0个元素是返回的字符串,第一个元素是替换的次数。

值得指出的是如果重复次数有0的时候就会有如下现象。还会有替换的。*是0次或者更多,而+是一次或者更多,所以*的时候不会替换,而+则不会。

还可能会有逆向引用。

\1就是一个反响引用。不过这里需要注意的是\1是会变得,我猜测sub应该是search迭代而来的,第一次迭代\1是First,第二次\1是Second,就这么理解吧,如果想彻底搞清楚就得去看源码,不过还是有点麻烦的。还可以使用 Python 的扩展语法 (?P<name>...) 指定命名组,引用命名组的语法是 \g<name>。\g<name> 会将名字为 name 的组匹配的字符串替换进去。另外,\g<数字> 是通过组的序号进行引用。\g<2> 其实就相当于 \2,但我们更提倡使用 \g<2>,因为这样可以避免歧义。例如,\g<2>0 的含义是引用序号为 2 的组,然后后边匹配一个字符 '0',而你写成 \20 就会被认为是引用序号为 20 的组了。

这里还有一个小知识点,你自己命名的组还保留了python默认的数字子组号。也许你会担心如果你自己想命名一个数字组号呢?不用担心,那样会报错的。有时候你可能不满足简单的字符串替换,你可能需要在替换的过程中动点“手脚”......没关系,一样可以满足你!replacement 参数还可以是一个函数,该函数将会在正则表达式模式每次不重复匹配的时候被调用。在每次调用时,函数会收到一个匹配对象的参数,因此你就可以利用这个对象去计算出新的字符串并返回它。下边的例子中,替换函数将十进制数替换为十六进制数:

match.group返回的是一个string,所以要用int函数。当使用模块级的 re.sub() 函数时,正则表达式模式作为第一个参数。该模式可以是一个字符串或一个编译好的对象。如果你需要指定正则表达式标志,那么你必须使用后者;或者使用模式内嵌修正器,例如 sub("(?i)b+", "x", "bbbb BBBB") 返回 'x x',?i是re.I是不区分大小写的意思。
一些总结
使用字符串方法
有时使用 re 模块是个错误!如果你匹配一个固定的字符串或者单个字符类,并且你没有使用 re 的任何标志(像 IGNORECASE 标志),那么就没有必要使用正则表达式了。字符串有一些方法是对固定字符串进行操作的,并且它们通常比较快。因为它们都是独立优化的 C 语言小循环,目的是在简单的情况下代替功能更加强大、更具通用性的正则表达式引擎。举个例子,例如你想把字符串中所有的 dead 替换成 word,你会想到使用正则表达式的 re.sub() 方法来实现,但这么简单的替换,还是考虑直接使用字符串的 replace() 方法吧。但有一点你需要注意,就是 replace() 会在单词里边进行替换,像 swordfish 会变成 sdeedfish,这显然不是你想要的!replace() 没办法识别单词的边界,因此你才来考虑使用正则表达式。只需要将 RE 的模式写成 \bword\b 即可胜任此任务。另一个常见的情况是从一个字符串中删除单个字符或者用另一个字符替代它。你也许会想到用 re.sub('\n', ' ', S) 这样的正则表达式来实现,但其实字符的 translate() 方法完全能够胜任这个任务,并且比任何正则表达式操作起来更快些。
简而言之,在使用 re 模块之前,先考虑一下你的问题是否可以用更快速、简单的字符串自带方法来解决。有时候你可能会有这样的想法,可以用.*来克服match的缺点。
贪婪 VS 非贪婪
当重复一个正则表达式时,如果使用 a*,那么结果是尽可能多地去匹配。当你尝试匹配一对对称的定界符,例如 HTML 标志中的尖括号,默认的贪婪模式会使得你很困扰。来看下面的例子:

RE 匹配在 <html> 的 < 后,.* 消耗掉字符串的剩余部分。由于正则表达式默认是贪婪的原因,RE 必须从字符串的尾部一个字符一个字符地回溯,直到找到匹配的 >。大家看到,按照这种方法,最后找到匹配内容竟是 <html> 的 < 开始,到 </title> 的 > 结束。显然这不是你想要的结果。在这种情况下,解决方案是使用非贪婪的限定符 *?、+?、?? 或 {m,n}?,尽可能地匹配小的文本。在上边的例子中,> 在第一个 < 被匹配后立刻尝试匹配,如果失败,匹配引擎前进一步,尝试下一个字符,直到第一次匹配 >,这样就得到了我们想要的结果。注意,使用正则表达式分析 HTML 和 XML 是很痛苦的。当你编写一个正则表达式去处理所有可能的情况时,你会发现 HTML 和 XML 总会打破你的“规则”,这让你很头疼......像这样的话,建议使用 HTML 和 XML 解析器来处理更合适。
关于异常处理
异常处理在我们爬虫的前面不是很看重,一直没有提及,在这里爬虫结束的地方来稍微提一下。编程嘛,很难会‘一蹴而就’,难免会有一些错误,比如我们前面用代理ip的时候经常报错对吧。经常遇见的异常有URLError,这是在urlopen处理不了响应的时候会出现,一般自己的网络情况不好或者url不存在的时候就会触发,返回的对象有一个reason属性。我们来看一下,首先这些异常都在urllib.error这个模块里面。我们来试一下。看到返回的HTTP状态码是11001是getaddrinfo failed也就是没有域名导致的。还有一个是HTTPError它是URLError的一个子类,每一个HTTP都会返回一个HTTP状态码,详见http://bbs.fishc.com/thread-103840-1-1.html还有https://www.cnblogs.com/pyoyw/p/5838530.html,不过里面没有提到11001。有时候状态码会指出服务器无法完成的请求类型,一般情况下 Python 会帮你处理一部分这类响应(例如,响应的是一个“重定向”,要求客户端从别的地址来获取文档,那么 urllib 会自动为你处理这个响应。);但是呢,有一些无法处理的,就会抛出 HTTPError 异常。这些异常包括典型的:404(页面无法找到),403(请求禁止)和 401(验证请求)。因为 Python 默认会自动帮你处理重定向方面的内容(状态码 300 ~ 399 范围),状态码 100 ~ 299 的范围是表示成功,所以你需要关注的是 400 ~ 599 这个范围的状态码(因为它们代表响应出了问题)。其中,出现 4xx 的状态码,说明问题来自客户端,就是你自己哪里做错了;出现 5xx 的状态码,那就表示与你无关了,是来自服务器的问题。HTTP返回的对象可以有code属性,并且是一个页面,还可以用geturl和read方法的。
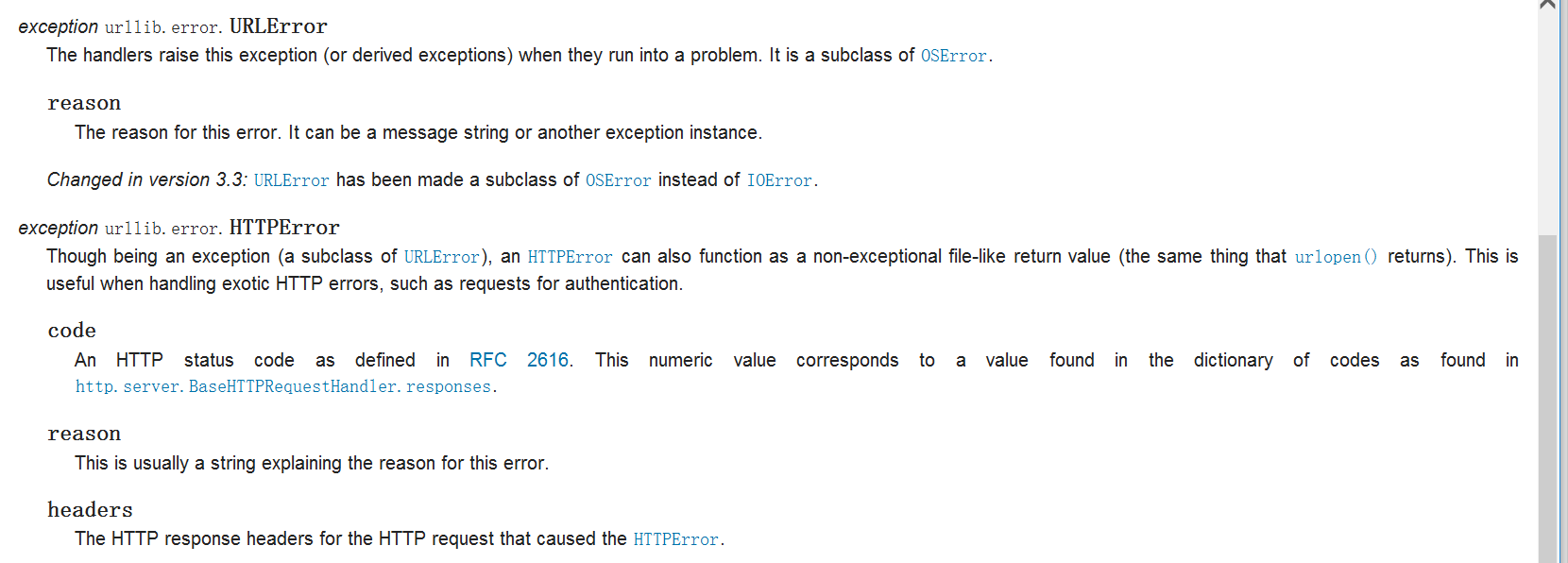
不过HTTPError的触发范围很有限,目前只看到了是forbidden403的时候是返回HTTPError。


这里需要稍微补充一点前面没有说过的是这个b的命名空间只有在except里面。看到globals()里面是没有b的。

那么下面就提供一种常见的异常处理方法。

这里要注意的一点是HTTPError要写在URLError的前面,不然的话都要被URLError拦截了,根本不会执行HTTPError里面的语句。
Requests的安装与使用

使用请参考https://www.cnblogs.com/printN/p/6920055.html。这个模块可以代替urllib.request模块,它的用法更简单,举个例子,,转化为json方面,requests里有内置函数,更方便一点,这个用法呢请大家自己去学习,和urllib.request基本一样,而且函数还更简单,就不再赘述了,这是选学的,因为python自带的urllib.request完全可以完成一样的功能,只是打的代码多少不同。根据个人喜好选择吧。