学习爬虫呢?我们首先要知道什么叫做爬虫,爬虫其实又叫做网页蜘蛛。互联网就是一个大的蜘蛛网,而网页蜘蛛在网上爬来爬去的行为就是我们不断阅读网页的行为。
那么下面就有问题了啊,我们以前完全没有讲过python如何访问互联网啊。python怎么访问互联网呢?就是通过下面的模块。

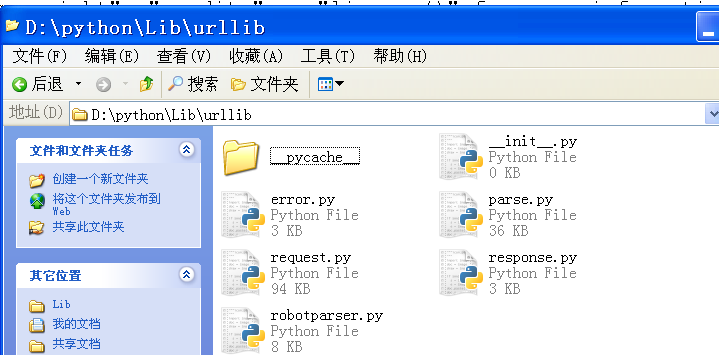
urllib是url和lib(库)组成。先看一下urllib是个什么东西

看到urllib是一个包,里面有五个模块。我们再实际去看一下
然后我们来说一说URL是什么。知己知彼才能更好的应用爬虫嘛,参考了百度百科。
URL



百度百科是把后面两部分作为一部分。


下面参考了https://jingyan.baidu.com/article/2c8c281df0afd00008252aa7.html,我认为说的很详细,就直接拿过来了,不想自己在重新组织语言了,人的惰性所致。

我们先了解一下什么叫服务器

我们上面说的都是WEB服务器,下面说的也是。其实服务器就是一台大型计算机嘛。



也就是说一个域名可以有不同的网站名,因为服务器可以不一样。



我来重复一遍,第一个是我们打进去的,第二个是电脑自动给我们加的,第三个是服务器自动加的根目录,前面我们在文件系统那里讲过根目录的概念。最后一个是根目录下默认的网页。
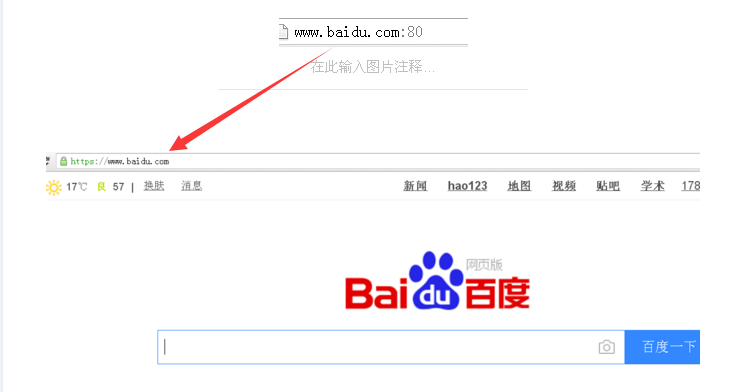
前面的协议名字不同的网站可能会不一样,现在一般都是https,这样的没有弹窗啊,广告什么的。上面我是写了80端口,下面换一个81号端口试试,你问我什么叫做端口(port)?这个我还是知道的,毕竟学过微机原理,首先,计算机与外设通讯的电路叫做接口,端口就是接口里面的寄存器,通常有控制,状态,数据端口。你的计算机上有各种接口,典型的有USB接口,显卡接口,键盘接口等。计算机给每个端口都有一个二进制或者说十六进制的地址,多少位和你的地址总线宽度有关系哈。这里面还有一个独立编址还是统一编址的问题,不过你只需要知道一个端口有唯一的地址就够了。我就知道这些,我们也就到这就够了。
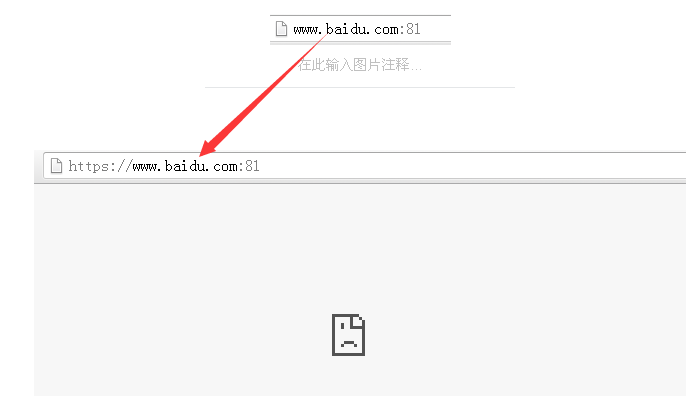
如果你知道了服务器就是一台大型计算机,那么绝对URL和相对URL你就理解了,和绝对路径相对路径类似嘛。

除了URL还有一个东西叫做URI,这些以后都会用到的,参考了https://www.zhihu.com/question/21950864

详细来说呢,我觉得知乎这位写得很形象,我就不献丑了。


URI就是一种一一对应对应关系的某种标识符,这个可以有很多种,区别一个人,我们可以用,身份证号,手机号,QQ号,邮箱(一个人可以有多个手机号,同样的,一个网站可以有多个URL的,不过那样就太分散了,但是绝对不会有两个不同的网站有一样的URL),住址,等等。URL是什么呢?就是其中的一种类似于住址的定位符,比如说你住在哪个寝室几号床啊,有人可能会说,我和我爸睡在一个屋子里的一张床上,那这个显然是抬杠,不过这个例子确实不是很严谨,但是还是可以帮助我们理解的。

稍微扩展一下知识

有了以上知识,到实际中操作一下吧。如何打开一个网页?urllib包里的request模块有urlopen函数
爬虫初试


这个阶段我们只用到了第一个参数URL。
试着来打开一个网页,比如流氓的百度


看来目前打开一个网页需要,把协议名和网站名都输进去,而且输端口号会报错,报错说是违反了协议,这个去到源文件应该是可以看到为什么报错的,这里我就不展示了,有兴趣自己可以根据报错内容,自己去相关的模块的源文件看一看。返回的是一个http.client模块的HTTPResponse对象。先简单了解一下http.client模块,参考了http://www.jb51.net/article/109852.htm。写的真的不错,我觉得这种可以直接拿来用的,我就不自己献丑写了。



看到这个443端口是不是上面的报错就豁然开朗了呢?唉,原来是端口不对造成的嘛,当然如果你想深究的话,没有这么简单,你需去ssl.py的握手handshake这一行去找原因。

还有

有兴趣的可以自己深入了解。其实理解起来很简单,就是不是默认端口访问不到呗。
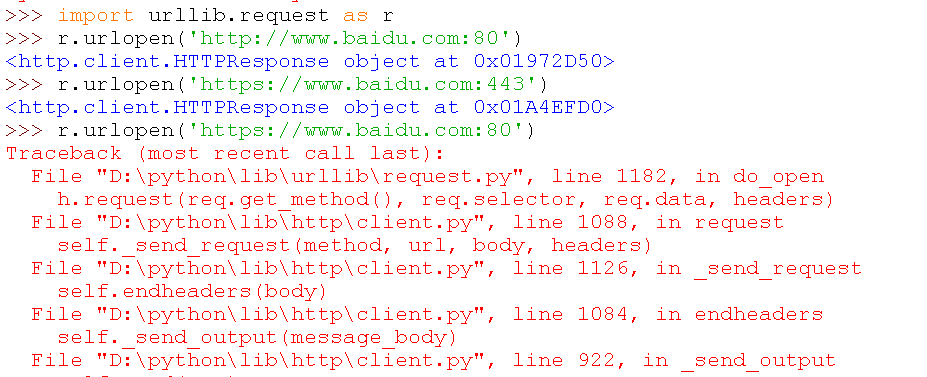
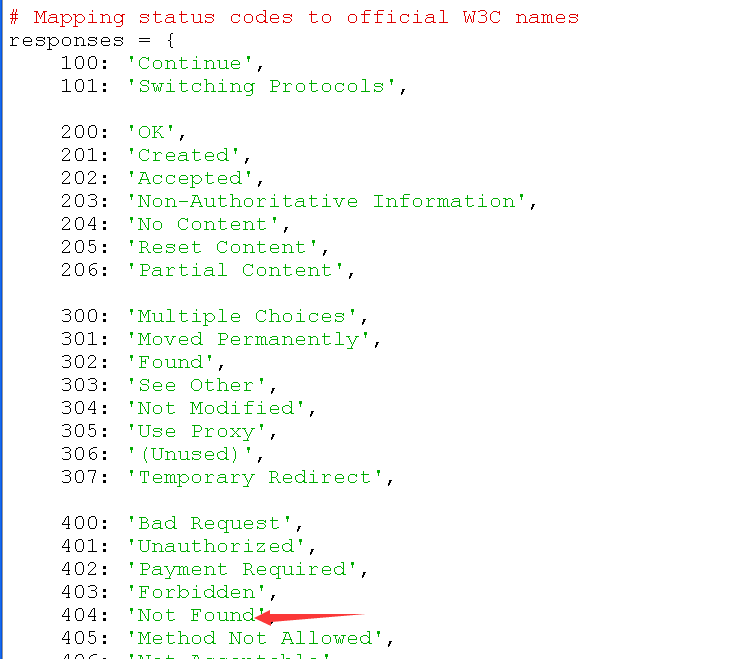
并且在responses里我们 可以看到熟悉的404。




我们就偏要来试试实例化这个HTTPResponse类。

这个错误原因要究其根源就要扯太多了,不是仅仅缺了sock参数这么简单,而且要读很多行代码,费时间而且大家也不一定能读懂,所以大家自己有经验有耐心的时候再去读更好,读高手的代码也是进步的一个很重要的方法哦。下面我就只截取了和HTTPResponse有关的内容,其它的你们可以自己打开那个网站看,如果你有兴趣的话。其实这些以后都会讲到,只是现在还没到时候。

注意红箭头的read我们下面马上会用得到。

这里就再科普几个知识吧。下面我都尽量选通俗的解释。先说一下什么叫做DNS



以下参考了https://blog.csdn.net/paranoidyang/article/details/54288370

DNS就是把域名转换为IP地址。
网关。

子网掩码,参考了https://www.zhihu.com/question/56895036


所以通过子网掩码我们可以推算出每个儿子内网的范围咯。回过来继续看。
对了这里还漏了一点内容,HTTPResponse返回的是一个二进制的对象,因为计算机只认识0,1在网络传输的过程中自然也必须只能传送二进制了。上面也说过read可以读取返回的HTTPResponse的内容,我们来试一试,读一个简单点的吧,就读取b站主页的前1000个字节吧,,不然会很长很长,

这读出来是二进制吗?你看到开头有个b,还有很多\x十六进制的数字。没错,这的确是二进制文件(虽然看着不全是二进制的数,还有一些拉丁字母和英文标点,下面会讲解为什么是这样的,实际上缺失的都是不能用ASCII码表示的字符)。这里就有必要详细了解编码的一些知识
编码[encode]和译码(解码)[decode]
参考了http://bbs.fishc.com/thread-66084-1-1.html和https://www.cnblogs.com/OldJack/p/6658779.html

还有http://python.jobbole.com/86670/和https://www.cnblogs.com/vipchenwei/p/6993788.html

unicode就是universal code的意思。GBK就比较中式,叫国标扩展,接触过机械的都见过GB/什么什么的,那就是国标的首字母。

下面是更清晰地说明UTF-8是如何存储Unicode码的https://blog.csdn.net/hezh1994/article/details/78899683。还有http://www.cnblogs.com/yyds/p/6171340.html

UTF的全称是Unicode transformation format。

更详细点

编码问题是很重要的问题。我就再总结一下编码,如果学过数字电子就更好理解了,比如说2用8421码来编就是10,用格雷码来编就是11,编码就是把我们认识的字符都转化为计算机认识的0和1。为了把英文字符一一对应为电脑认识的二进制,美国人发明了ASCII码,为了把中文字符一一对应为二进制,我们中国有现在一般是GBK码,同样日本,韩国等都有自己国家的语言对应到二进制的码,而且会出现同一个二进制在不同国家的编码体系里对应不同的字符,这也很好理解对吧。这样不便于大家交流,那么就需要有统一的一种编码方式了,然后Unicode就诞生了,它这种体系可以包容各个国家的语言,可以保证每个二进制数和字符的一一对应关系,不会出现比如说某个二进制既对应着中国的‘你‘,又对应着美国的'fuck'。但是Unicode的码存储起来是很耗费空间的,这时候就需要用到utf这种变字节存储方式来存,utf-8是我们比较常用的。那么译码就是反过程咯。我们可以在命令行里查看系统的默认编码,右键标题栏,点属性
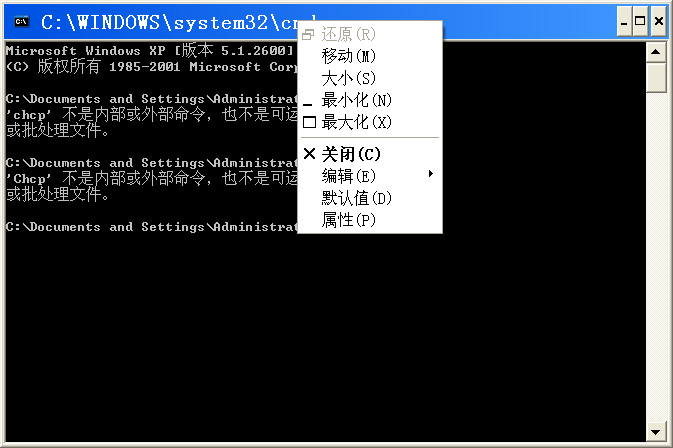
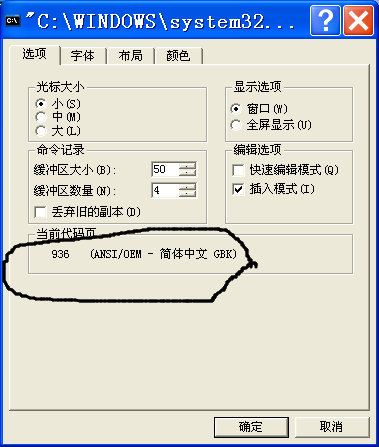
可以看到是GBK的。你也可以在命令行直接输入chcp就可以查看。如果是936那么就也是GBK编码。也可以查看python默认的编码方式是什么样的。

我们再来深入探索一下编码与解码的世界。参考了https://www.cnblogs.com/abclife/p/7445222.html和https://www.cnblogs.com/654321cc/p/7419124.html。

bin是把一个整数转换为二进制,用的是8421码,并且只能转换整数。我们一般用不到它,因为你在键盘上面敲进去的数字也全是字符,并不是数字。什么意思呢?还记得input吗?

只有经过了int才转化成整数了。这就是我们输入的都是字符的含义。以前我们曾经用过ord()说它返回的是ASCII码,其实是不对的,返回的是utf-8码,只是因为拉丁字母和一些特殊字符的ASCII码和UTF—8码是一样的或者说是兼容的而已。返回的是单个字符的utf-8码

当然实际存在计算机里都是二进制的,只是为了方便用户看,显示出来的是十进制的。与之对应的是chr

为什么chr(23)和chr(31)没有显示字符呢?因为ASCII码表里(我为什么用ASCII码表呢?因为utf-8和ASCII码是兼容的),23和31对应的字符都是控制字符,python并不能给你显示出来,所以返回了一个十六进制字符。

Bytes()前面也说到是一种二进制类型。




打印出来的 格式默认都是十进制。

字符串内部确实有encode()编码的内置函数可以按照给定编码形式把字符串进行编码,转换为二进制的形式,如果不给编码形式那么就按照python默认的utf-8来编码。bytes类的内置方法decode()可以按照给定解码方式解码,如果不给就按照python默认的utf-8解码。上面d为什么按照utf-8解码错误呢?因为回去看这个表
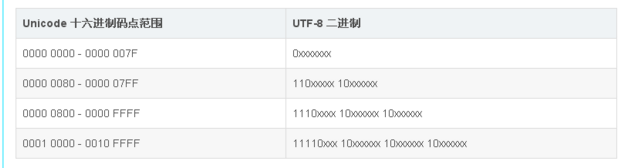
\xd6\xd0二进制就是11010110 11010000,这样的二进制是不符合utf-8的格式的。有的时候不会报错,但是会出现乱码。还有可能会出现下面的情况。


为什么有的返回的不是b十六进制而是直接b+原来的字符串呢?根据上面的尝试我猜想是ASCII码里有的打印字符在后来的所有编码格式里包括GBK,utf-8等等里面都是直接继承了ASCII码的。因为大家都一样嘛,所以就直接前面加个b表示这是二进制就返回了。到这里,你就知道前面b站主页返回的前1000个字节为什么有的是\x十六进制,有的直接就是拉丁字母和英文标点了。
下面看看bytes()的作用。

其实就是编码,而且后面还必须要加上编码的格式。并且上面验证了所有编码格式都继承了美国最早的ASCII码的所有拉丁字母和英文字符的对应关系。这样就理解了为什么上面获取的网站后返回的HTTPResponse类型为什么不全是\x的十六进制形式,可以看到拉丁字母和英文字符都是直接表示出来了,因为在python认可的所有编码体系里它们的二进制都一样,不需要给出来了。有时候我们打开的文件会出现乱码,是怎么回事呢?下面我们要学习一下python里的文件读取操作,
python之文件读取简单原理
参考了http://www.cnblogs.com/yyds/p/6186621.html和
http://www.cnblogs.com/yyds/p/6171340.html
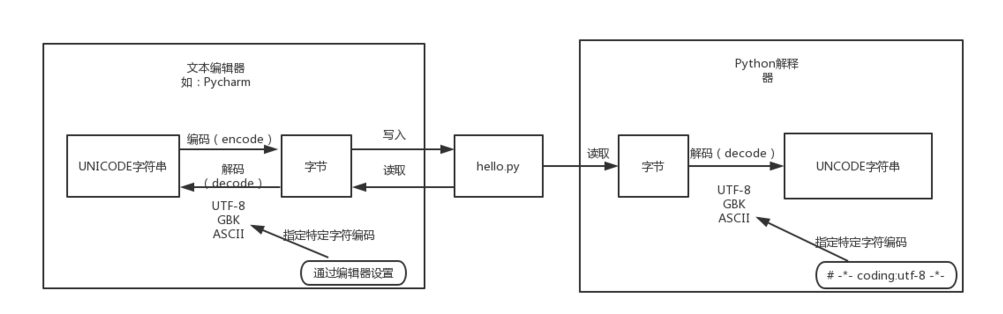
首先我们要明白一个概念,磁盘写入或读取数据时使用的字符编码是由编辑器指定的工程或文件的字符编码决定的,这与Python解释是无关的。Python3的解释器以"UTF-8"作为默认编码,但是这并不表示可以完全兼容中文问题。比如我们在Windows上进行开发时,Python工程及代码文件都使用的是默认的GBK编码,也就是说Python代码文件是被转换成GBK格式的字节码保存到磁盘中的。怎么体现这点呢?
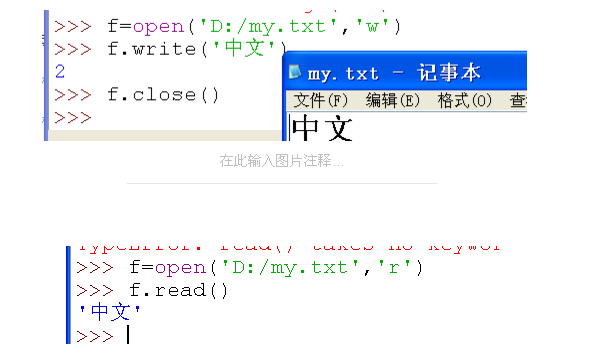
首先我们写了一个txt文件,这个文件是怎么被写进去的?还是必须先编码才行,由于我们没有指定编码方式,就用了默认的GBK,因为计算机只认识0和1,然后这个编码方式其实也传给了计算机,那么我们的计算机就会以GBK的格式去解码传过来的二进制数据,也就是编码解码方式是一样的,我们才能看到'中文‘。那么我们就试试用‘utf-8’去编码试一下咯。

我们还是看到了正常的'中文',这前面说过是因为编码方式也被传递给计算机了,计算机会按照python传过来的编码格式也就是utf-8来解码。但是当python在读取的时候,它是得不到这个我们原来传过去的编码方式的,它得到的就只有文本内容的一堆二进制,如何解码呢?不知道,我们如果不给它解码方式,它就按照默认的GBK来解码,结果就报错了。你们可以自己去对照GBK的表http://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php。然后我们来看

我们先来了解什么叫做流,参考了https://www.zhihu.com/question/38075755,https://blog.csdn.net/hansnowqiang/article/details/50130437和https://blog.csdn.net/u011000290/article/details/48940371。

当然上面只是说了我们为什么需要缓冲区的原因,还没有说什么是流。

我们不再延伸了,有兴趣可以自己去学有关流的更多操作。

API就是Application Programming Interface,应用程序编程接口,就是前人已经写好的实现复杂功能的函数,以供后人可以直接调用。

上面编码花了好打空间,我们回过来继续学爬虫,上面这些后面课程的基础,所以我在爬虫的第一讲先讲一部分知识,当然这还没有包含掌握爬虫需要掌握的所有知识。以后再慢慢渗透吧。前面爬取b站的时候,我们得到的是编码过的二进制,需要译码成我们可以看懂的形式。译码之前我们就需要知道百度是什么编码方式,怎么获得呢?其实很简单按F12就可以审查元素了。这个Elements里面是HTML代码,
Console里面是调试JavaScipt的,Sources是资源,后面的暂时后用不到。然后点开head,charset后面就是编码的格式。
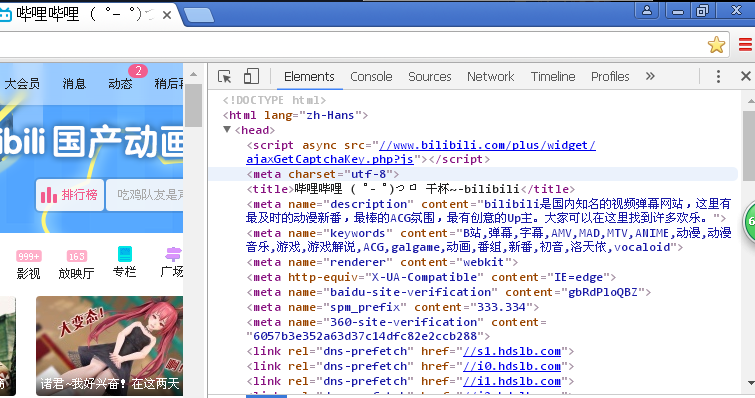
知道了编码形式我们来解码吧。

你可以去和上面对比,哪些是十六进制的地方绝对都是汉字。虽然还是看不懂HTML,但是这并不妨碍你找资源。这里在稍微说一个小知识
再写十六进制的时候,你需要按照字节来写\x号,什么意思呢?对比下面你就懂了
第一种写法b'\x8140'其实是\x81=129,ord('4')=52,ord('0')=48。第二种才是\x81=128,\x40=64。

下面就先来大展一番身手吧
练习
0.编写一段程序,检测指定URL的编码。
1.写一个程序,依次访问指定文件夹里的网页,并将内容保存在不同的文件中。
答案和讲解会在下一讲公布。