身处于互联网时代,每当打开浏览器连接https://www.baidu.com/的时候,读者可能都不会思考网络正在做什么;面对形形色色的网页,读者也不会去思考网页是如何呈现在大家面前的。俗话说得好,“知己知彼,方能百战不殆”。本章将通过介绍网络连接来解释爬虫的原理,并使用Chrome浏览器认识网页构造并查询网页信息。
本章涉及的主要知识点如下。
·网络连接:介绍网络连接的基本过程。
·爬虫原理:介绍爬虫的基本原理和过程。
·Chrome浏览器:介绍Chrome浏览器的安装,以及使用Chrome浏览器认识网页构造和查询网页信息。
点此免费领取:CSDN大礼包:《python爬虫教程&全套学习资料》免费分享
2.1 爬虫原理
现实生活中使用浏览器访问网页时,网络到底做了什么?本节将简单地介绍网络连接原理,并以此介绍爬虫原理。
2.1.1 网络连接
网络连接像是在自助饮料售货机上购买饮料一样:购买者只需选择所需饮料,投入硬币(或纸币),自助饮料售货机就会弹出相应的商品。如图2.1所示,计算机(购买者)带着请求头和消息体(硬币和所需饮料)向服务器(自助饮料售货机)发起一次Request请求(购买),相应的服务器(自助饮料售货机)会返回本计算机相应的HTML文件作为Response(相应的商品)。
注意:这里是一个GET请求。
对于学习爬虫技术,读者只需知道最基本的网络连接原理即可。计算机一次Request请求和服务器端的Response回应,即实现了网络连接。计算机Request请求带着的请求头和消息体是什么以及网络更底层的东西,不是本文所介绍的范围。

图2.1 网络连接原理
2.1.2 爬虫原理
了解网络连接的基本原理后,爬虫原理就很好理解了。网络连接需要计算机一次Request请求和服务器端的Response回应。爬虫也是需要做两件事:
(1)模拟计算机对服务器发起Request请求。
(2)接收服务器端的Response内容并解析、提取所需的信息。
但互联网网页错综复杂,一次的请求和回应不能够批量获取网页的数据,这时就需要设计爬虫的流程。本书中主要用到两种爬虫所需的流程,即多页面和跨页面爬虫流程。
1.多页面爬虫流程
多页面网页结构如图2.2所示。
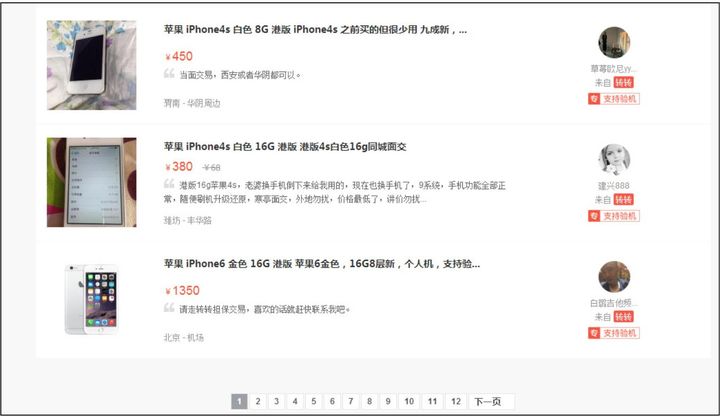
图2.2 多页面网页结构
有的网页存在多页的情况,每页的网页结构都相同或类似,这种类型的网页爬虫流程为:
(1)手动翻页并观察各网页的URL构成特点,构造出所有页面的URL存入列表中。
(2)根据URL列表依次循环取出URL。
(3)定义爬虫函数。
(4)循环调用爬虫函数,存储数据。
(5)循环完毕,结束爬虫程序,如图2.3所示。
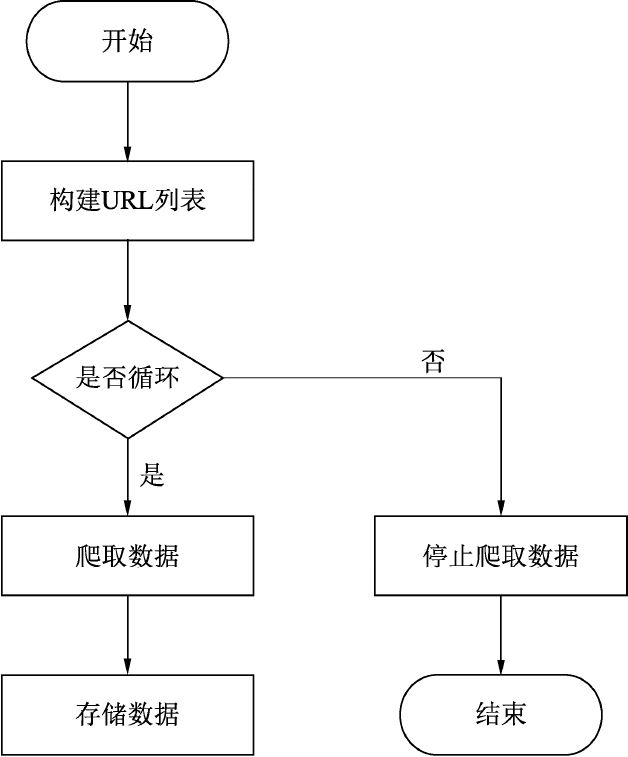
图2.3 多页面网页爬虫流程
2.跨页面爬虫流程
列表页和详细页分别如图2.4和图2.5所示。
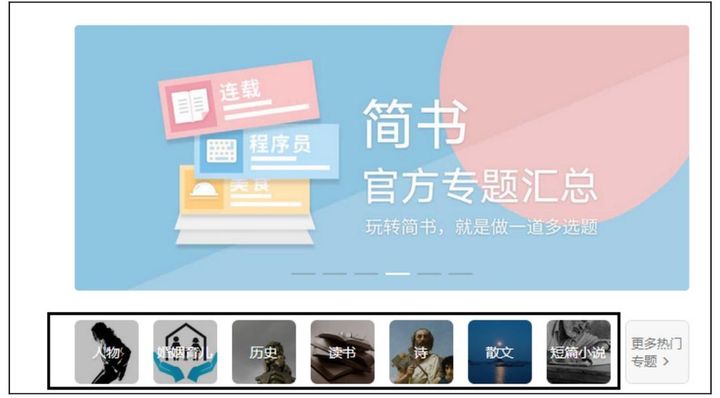
图2.4 列表页
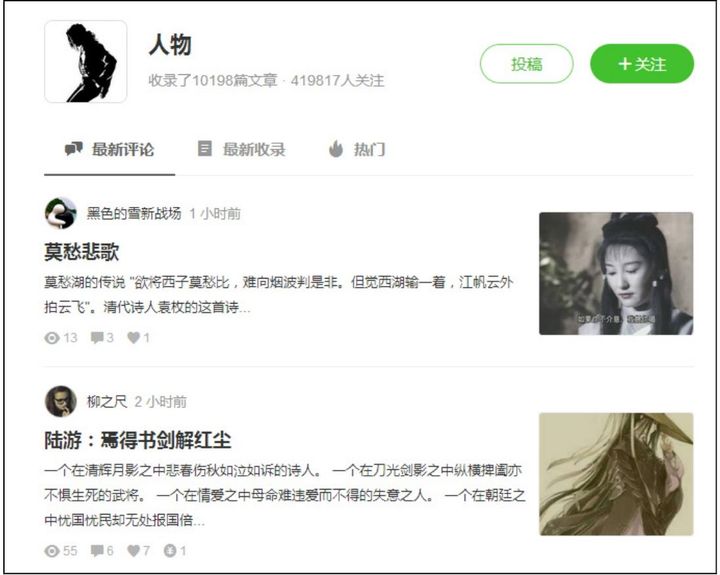
图2.5 详细页
这种跨页面的爬虫程序流程为:
(1)定义爬取函数爬取列表页的所有专题的URL。
(2)将专题URL存入列表中(种子URL)。
(3)定义爬取详细页数据函数。
(4)进入专题详细页面爬取详细页数据。
(5)存储数据,循环完毕,结束爬虫程序,如图2.6所示。
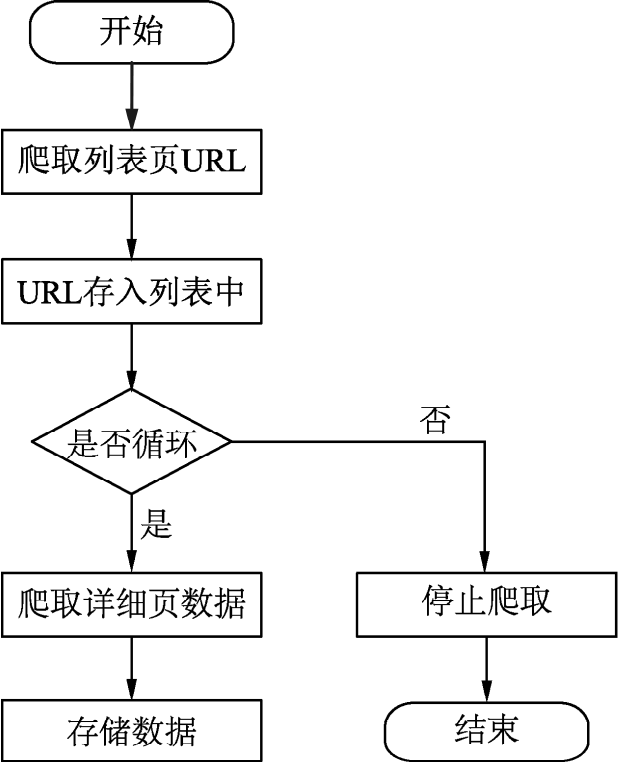
图2.6 跨页面网页爬虫流程
2.2 网页构造
本节将介绍如何安装和使用Chrome浏览器,并通过Chrome浏览器的使用简单介绍网页的构成。
2.2.1 Chrome浏览器的安装
Chrome浏览器的安装与普通软件安装一样,不需要进行任何配置。在搜索引擎中输入Chrome,单击下载安装即可。安装完成打开后,会出现如图2.7所示的错误。
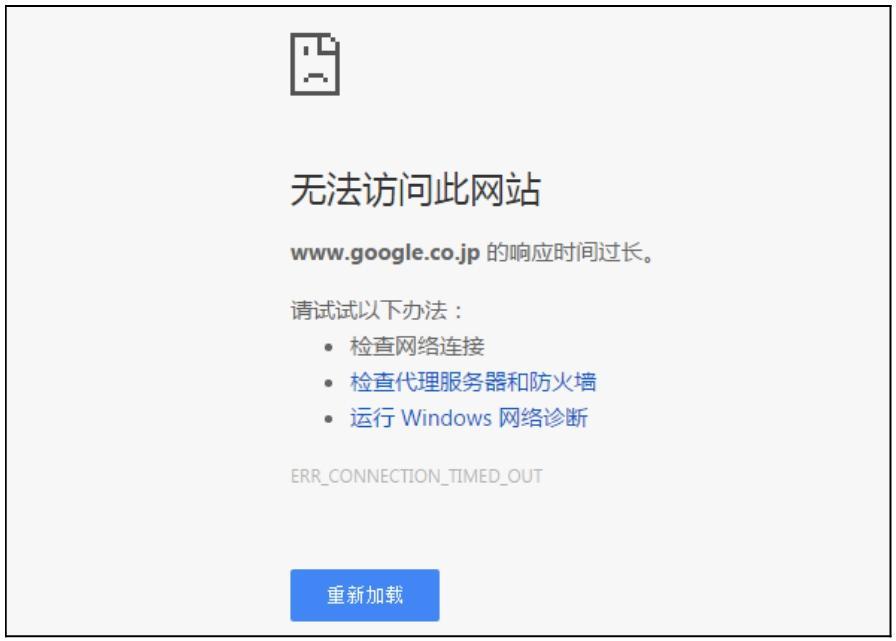
图2.7 Chrome浏览器报错
这是因为Chrome浏览器默认的搜索引擎为Google搜索引擎,国内的网络是无法打开的。解决办法如下。
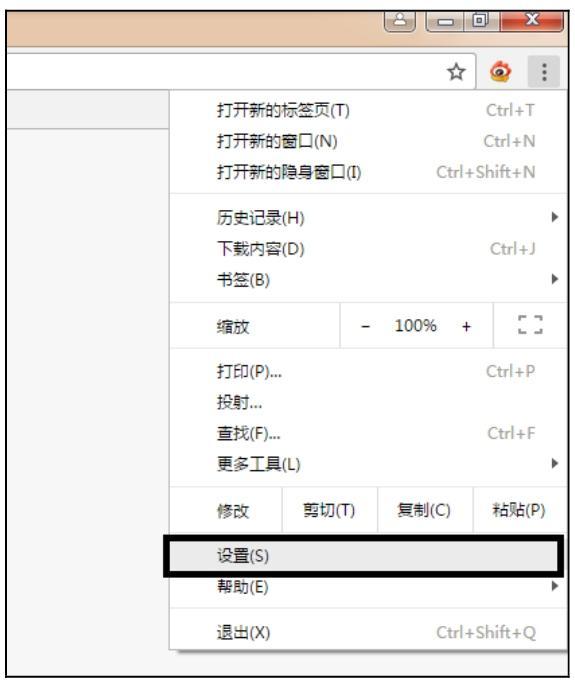
图2.8 Chrome浏览器网页设置1
(1)打开Chrome浏览器,选择“设置”选项。
(2)在“启动时”栏目中,选择“打开特定网页或一组网页”单选按钮。
(3)单击“设置网页”链接,输入常用的搜索引擎或网页,单击“确定”按钮。
(4)退出Chrome浏览器,再打开之后便是设置过后的网页。操作过程如图2.8至图2.10所示。
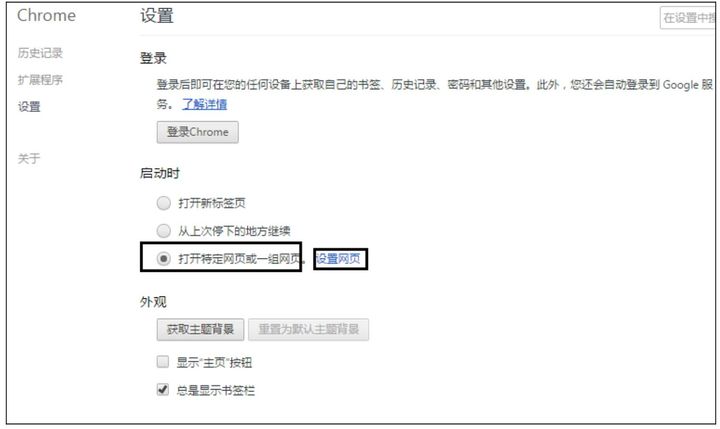
图2.9 Chrome浏览器网页设置2

图2.10 Chrome浏览器网页设置3
注意:这里笔者设置的为百度搜索网页。
2.2.2 网页构造
现在打开任意一个网页(http://bj.xiaozhu.com/),然后右击空白处,在弹出的快捷菜单中选择“检查”命令,可以看到网页的代码,如图2.11所示。
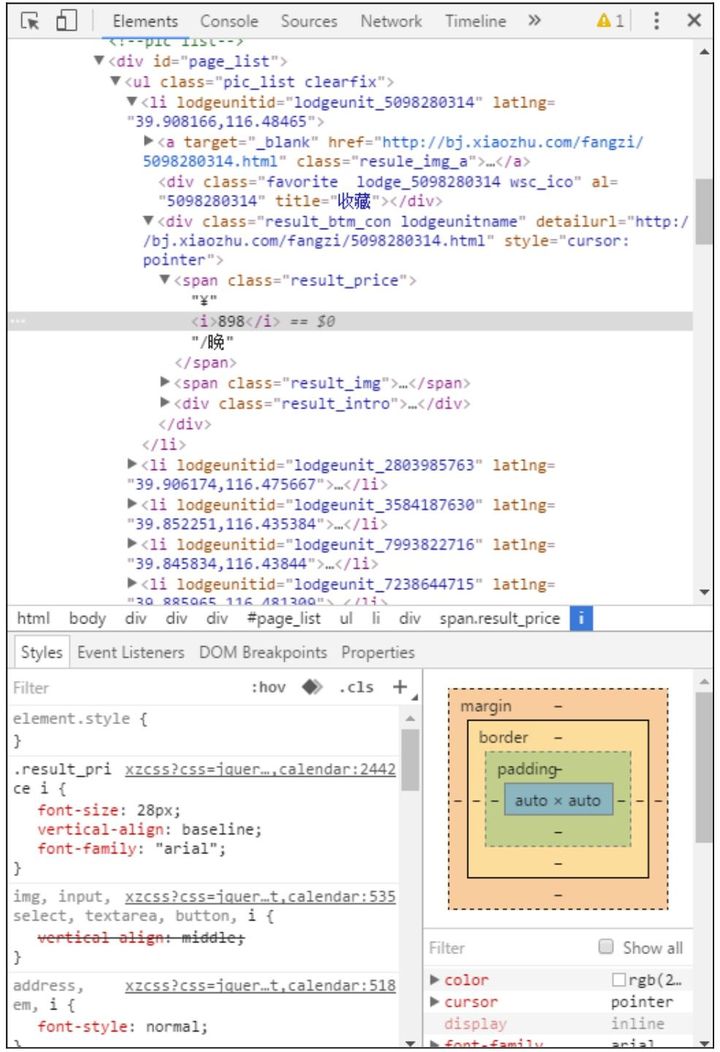
图2.11 网页构造
现在来分析图2.11,图中上半部分为HTML文件,下半部分为CSS样式,用标签的就是JavaScript代码。用户浏览的网页就是浏览器渲染后的结果,浏览器就像翻译官,把HTML、CSS和JavaScript代码进行翻译后得到用户使用的网页界面。如果把网页比喻成房子的话,那么HTML为房子的框架和格局(几室几厅),CSS就是房子的样式(地板、房漆),JavaScript就是房子中的电器。
注意:本文只是简单介绍网页构造,前端语法不做解释。
2.2.3 查询网页信息
打开网页(http://bj.xiaozhu.com/),右击网页空白处,从弹出的快捷菜单中选择“查看网页源代码”命令,即可查看该网页的源代码,如图2.12所示。
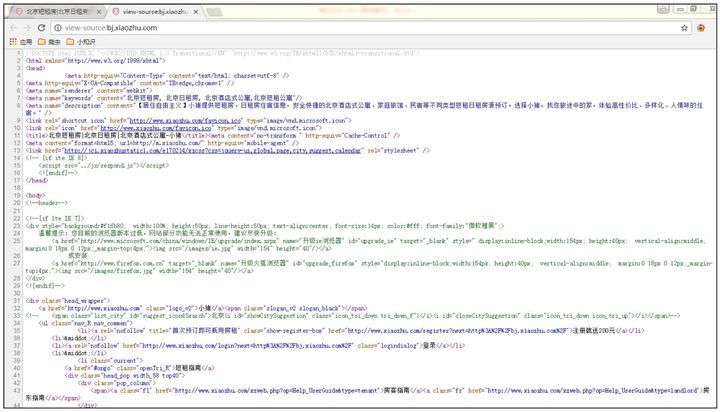
图2.12 查看网页源代码
通过在指定元素上右击,然后选择快捷菜单中的“检查”命令,即可查看该元素在网页源代码中的准确位置。例如,查看网页(http://bj.xiaozhu.com/)中第一个租房的房价信息,如图2.13所示。

图2.13 租房信息
把鼠标光标移至价格元素位置,右击,从弹出的快捷菜单中选择“检查”命令,即可查看该元素在网页源代码中的具体位置,如图2.14所示。
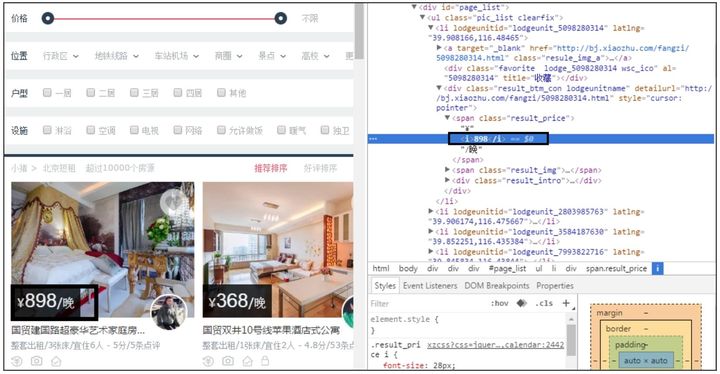
图2.14 “检查”元素
0经验0基础,怎样学技术赚钱?
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。
(python兼职资源+python全套学习资料)

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。

最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。