版权声明:未经允许,禁止转载 https://blog.csdn.net/weixin_43216017/article/details/87474045
决策树算法是非常常用的分类算法,其分类的思路非常清晰,简单易懂。并且它也是一个很基础的算法,集成学习和随机森林算法是以其为基础的。
算法简介
对于决策树算法,其输入是带有标签的数据,输出是一颗决策树。其非叶节点代表的是逻辑判断;叶节点代表的是分类的子集。
决策树算法原理是通过训练数据形成if-then的判断结构。从树的根节点到叶节点的每一条路径构成一个判断规则。我们需要选择合适的特征作为判断节点,可以快速的分类,减少决策树的深度。最理想的情况是,通过特征的选择把不同类别的数据集贴上对应类标签,树的叶子节点代表一个集合,集合中数据类别差异越小,其数据纯度越高。
在决策树中,目前比较常用的有ID3算法,C4.5算法和Cart算法。不同算法的区别在于选择特征作为判断节点时的数据纯度函数(标准)不同。本文主要介绍决策树中的ID3算法。
C4.5算法:https://blog.csdn.net/weixin_43216017/article/details/87609780
CART算法:https://blog.csdn.net/weixin_43216017/article/details/87617727
决策树的剪枝:https://blog.csdn.net/weixin_43216017/article/details/87534496
信息增益
ID3算法使用的数据特征函数(标准)为信息增益。
首先,我们介绍一下熵的概念,熵表示的是不确定度,熵越大,不确定度就越大。假设在数据D中有
k个类别,其中第
i个类别数据在总数据中占有率为
pi,则熵的计算公式为:
info(D)=−i=1∑kpilog2(pi)
当我们使用某一特征A对数据分类后,其不确定度会减小(因为数据数据有所划分)。此时的熵也会减小,假设特征A有m个类别,其计算公式为:
infoA(D)=−j=1∑m∣D∣∣Dj∣×info(Dj)
那么分类前后熵减小的差值就是信息增益。
Gain(A)=info(D)−infoA(D)
我们一一计算所有变量的信息增益,选择信息增益最大的那个变量作为此分类节点。
数据简介
为了详细介绍如何用ID3算法生成一颗树,我们设定一组贷款数据如下:

我们将通过年龄、是否有工作、是否有房子和信贷情况四个自变量来区分贷款的审批结果。
计算过程
第一层
总体信息熵:
info(D)=−159log2(159)−156log2(156)=0.9710
计算年龄A1的信息熵:
info(D∣A1=老年)=−54log2(54)−51log2(51)=0.7219
info(D∣A1=中年)=−53log2(53)−52log2(52)=0.9710
info(D∣A1=青年)=−52log2(52)−53log2(53)=0.9710
info(D∣A1)=31×0.7219+31×0.9710+31×0.9710=0.8880
则A1的信息增益为:
Gain(A1)=0.9710−0.8880=0.083
按照此方法,
Gain(A2)=0.324 ;
Gain(A3)=0.420 ;
Gain(A4)=0.363
由此可见,我们将使用变量A3:是否有房子来作为第一分类特征。
第二层
A3 = “是"时数据如下:
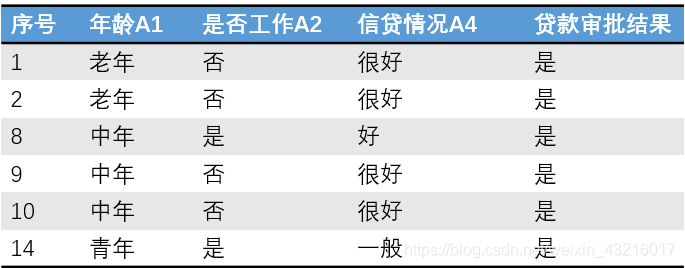
发现他们的贷款审批结果都是"是”,其熵等于0,可以作为叶节点。
A3 = "否"时数据如下:
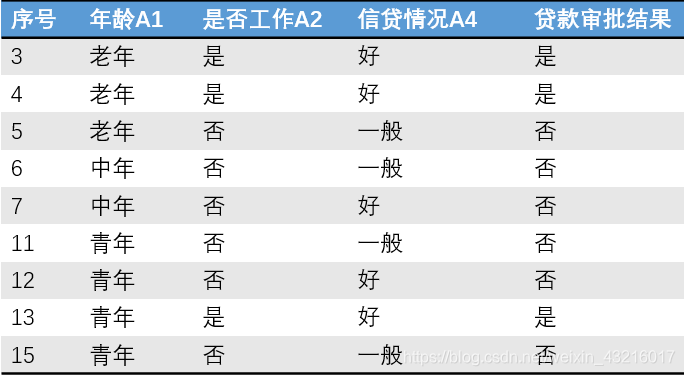
此时的总体信息熵:
info(DA3)=0.9183
Gain(A1)=0.2516 ;
Gain(A2)=0.9183 ;
至此不需要在计算
Gain(A4)了,因为A2已经将数据完全划分开了。
在本数据集中,A1和A4对于数据的划分没有作用。
所得树图:

在树图中,(1/2/8/9/10/14)(3/4/13)(5/6/7/11/12/15)是三个叶节点,代表了三个分类好的子集;其他非叶节点表示的是逻辑判断。
一般而言,我们都需要对树进行剪枝。因为我们划分枝叶的根据是熵增,只要有熵增就需要分枝,这样会很有可能造成过拟合的情况。我们将在下一篇中介绍树的剪枝。
ID3的缺点
ID3算法的缺点在于:用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性。
所以,我们使用信息增益比来代替信息增益,以削弱这种情况。此算法也即是C4.5算法。