最近过年啦,祝大家新年快乐,万事如意。
由于前几天回到家后比较忙,就没时间更新。然后昨天终于闲了下来,就写了个爬取Bilibili新番的爬虫。
这次主要也还是用beautifulsoup,selenium来爬取信息,当然在存储数据的时候还会用到一些mysql的知识,这个在下一篇博客再讲吧。
那么接下来开始这次的记录。
先看我们这次要抓取的内容。
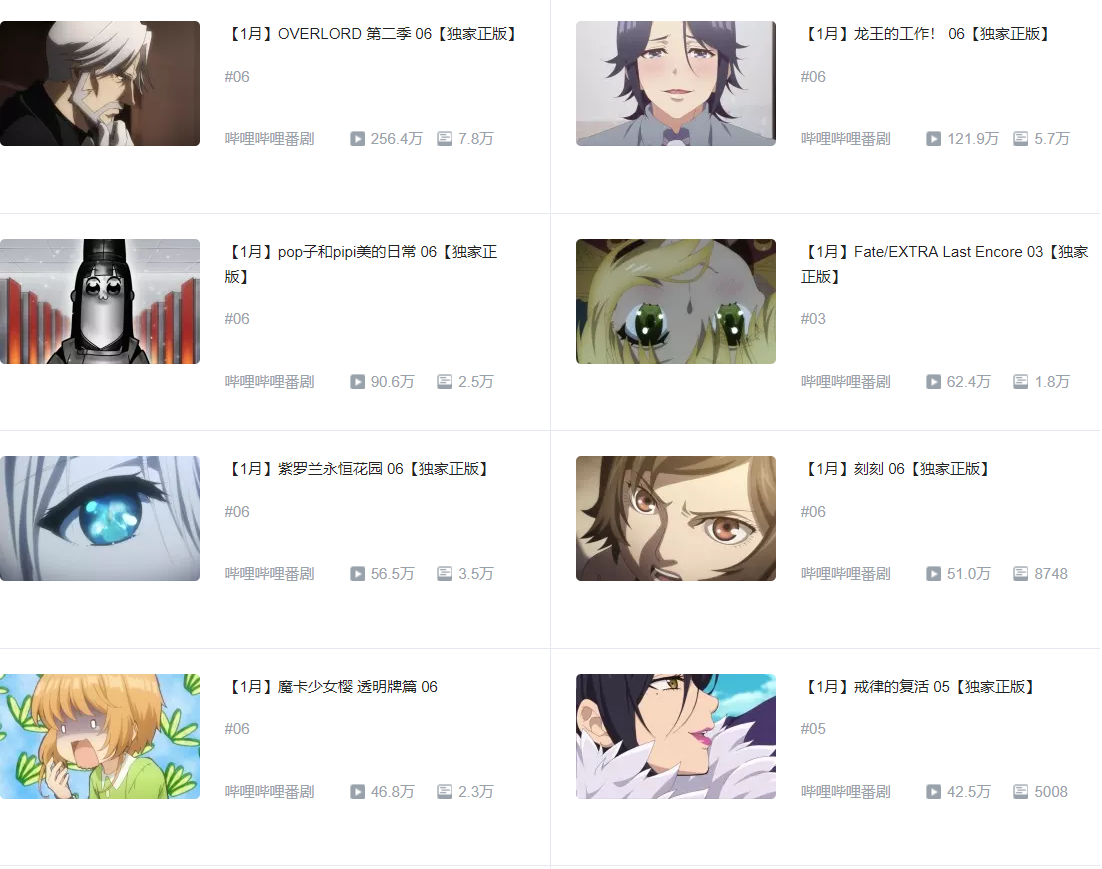
我们要抓取的是这个部分的新番名,还有观看人数,以及弹幕的数量,接下来我们看一下它们分别在HTML页面的哪个地方。
按一下F12
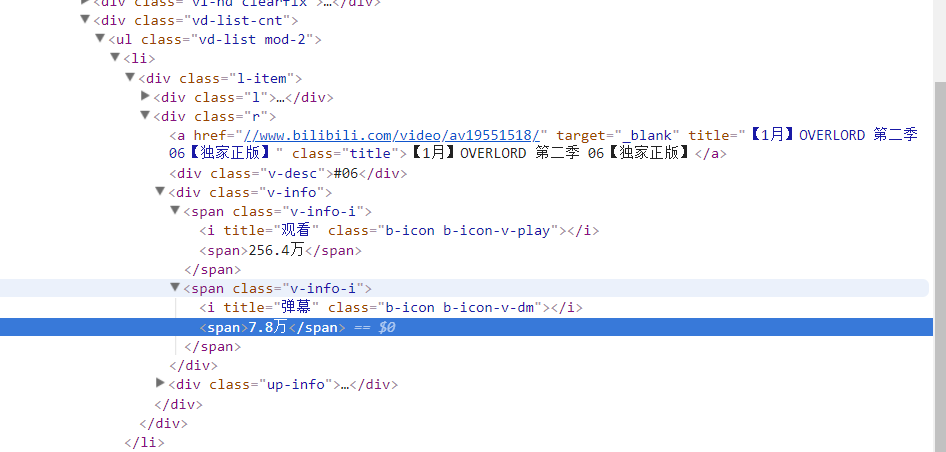
我们可以发现其实每个新番都在class为r的div里面,而观看人数和弹幕都在class为v-info-i里面,需要注意的是这两个是一样的,我昨天在爬取的时候在这里遇到了一点小麻烦,只能说学艺不精,待会再讲。
接下来看这几行代码:
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#videolist_box > div.vd-list-cnt > ul > li:nth-child(1) > div > div.r'))
)我们通过定位得到这个元素,接下来只要用beautifulsoup就可以得到新番名字了,关键是接下来这一步。
自己代码还是写的太少了,所以在得到观看人数和弹幕这两个数据的时候卡了一会才想出来怎么解决。
让我们先看代码:
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')
items = soup.find_all('div',class_ = 'r') #用find_all()函数找到该页面所有的新番
for item in items:
item1 = item.find_all('span',class_ = 'v-info-i') #这一步是我得到观看人数和弹幕的关键,找到第i个新番的所有v-info-i
Anime_name = item.find('a',class_ = 'title').text #得到新番名
Viewing_name = item1[0].text #得到观看人数
Barrage = item1[1].text #得到弹幕数量在我们得到页面的源代码后,我们通过beautifulsoup来解析网页
我们贴上这一段的完整代码:
def get_response(self):
driver = self.driver
wait = self.wait
try:
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#videolist_box > div.vd-list-cnt'))
)
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#videolist_box > div.vd-list-cnt > ul > li:nth-child(1) > div > div.r'))
)
except TimeoutException:
raise TimeoutException
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')
items = soup.find_all('div',class_ = 'r')
for item in items:
item1 = item.find_all('span',class_ = 'v-info-i')
Anime_name = item.find('a',class_ = 'title').text[:-6]
Viewing_name = item1[0].text
Barrage = item1[1].text
bilibili.insert(Anime_name,Viewing_name,Barrage) #进行插入操作,将数据插入数据库接下来是翻页:
我们看一下该页面:


最后是源代码:
# -*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.common.exceptions import TimeoutException from bs4 import BeautifulSoup import pymysql class Bilibili: def __init__(self): self.driver = webdriver.Chrome() self.wait = WebDriverWait(self.driver,10) self.url = 'https://www.bilibili.com/v/anime/serial/#/all/click/0/1/2018-02-08,2018-02-15' self.db = pymysql.connect('localhost', 'root', '123456', 'bilibili', charset='utf8') # 连接数据库,如果不加charset,可能会导致乱码出现 def create_Table(self): #建表 db = self.db cursor = db.cursor() table = "CREATE TABLE bilibili(Anime_name VARCHAR(255) NOT NULL,Viewing_number VARCHAR(255) NOT NULL,Barrage VARCHAR(255) NOT NULL)" cursor.execute(table) db.commit() def insert(self,Anime_name,Viewing_number,Barrage): #插入方法 db = self.db cursor = db.cursor() insert = "insert into bilibili(Anime_Name,Viewing_number,Barrage) values(%s,%s,%s);" cursor.execute(insert,(Anime_name,Viewing_number,Barrage)) db.commit() def open_page(self): #打开网页 url = self.url self.driver.get(url) def get_response(self): #寻找数据 driver = self.driver wait = self.wait try: wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#videolist_box > div.vd-list-cnt')) ) wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'#videolist_box > div.vd-list-cnt > ul > li:nth-child(1) > div > div.r')) ) except TimeoutException: raise TimeoutException page = driver.page_source soup = BeautifulSoup(page,'html.parser') items = soup.find_all('div',class_ = 'r') for item in items: item1 = item.find_all('span',class_ = 'v-info-i') Anime_name = item.find('a',class_ = 'title').text Viewing_name = item1[0].text Barrage = item1[1].text bilibili.insert(Anime_name,Viewing_name,Barrage) def next_page(self): #翻页 try: button = self.wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR,'#videolist_box > div.vd-list-cnt > div.pager.pagination > ul > li.page-item.next > button')) ) except TimeoutException: raise TimeoutException button.click() def main(self): driver = self.driver bilibili.open_page() for i in range(1,4): bilibili.get_response(i) bilibili.next_page() driver.quit() if __name__ == '__main__': bilibili = Bilibili() bilibili.create_Table() bilibili.main()
最后是效果图:

谢谢各位观看。