爬虫仅为相互学习,勿做他用!!!
爬虫部分
爬取数据
爬虫目标数据
- 各期刊论文的标题、作者、摘要、发表时间等信息
如下:
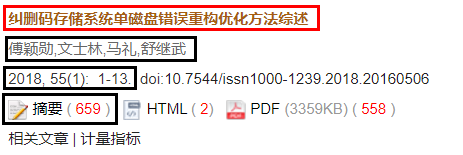
爬虫目标网站
目标网站:计算机研究与发展
其中,设我们需要爬取的数据为该网站 2018 年开始 到至今(2020.1)的所有期刊论文信息,下面看自2018年1月(即2018 第一期)开始的各期论文站点信息:
| 期号 | 网页地址 |
|---|---|
| 2018.1 | http://crad.ict.ac.cn/CN/volumn/volumn_1300.shtml |
| 2018.2 | http://crad.ict.ac.cn/CN/volumn/volumn_1301.shtml |
| 2018.3 | http://crad.ict.ac.cn/CN/volumn/volumn_1302.shtml |
| … | … |
| 2020.1 | http://crad.ict.ac.cn/CN/volumn/volumn_1327.shtml |
很容易我们就可以看出来,自2018.1开始,期刊地址中的字符串片段"volumn_1300"尾的数字随月份增加而增加,且一月对一期(共12*12+1 = 25期)。
故而,爬虫目标网址规律:http://crad.ict.ac.cn/CN/volumn/volumn_ + str(递增数字) + .shtml
获取各期刊网址函数如下:
def getUrls():
all_items = 12*2+1
urls = []
partstr = "http://crad.ict.ac.cn/CN/volumn/volumn_"
for i in range(all_items+1):
strone = partstr + str(1300+i) + ".shtml"
urls.append(strone)
for url in urls:
yield url
爬虫网站页面元素分析
我们需要的是各期刊论文的标题、作者、摘要、发表时间信息,观察网站:如下
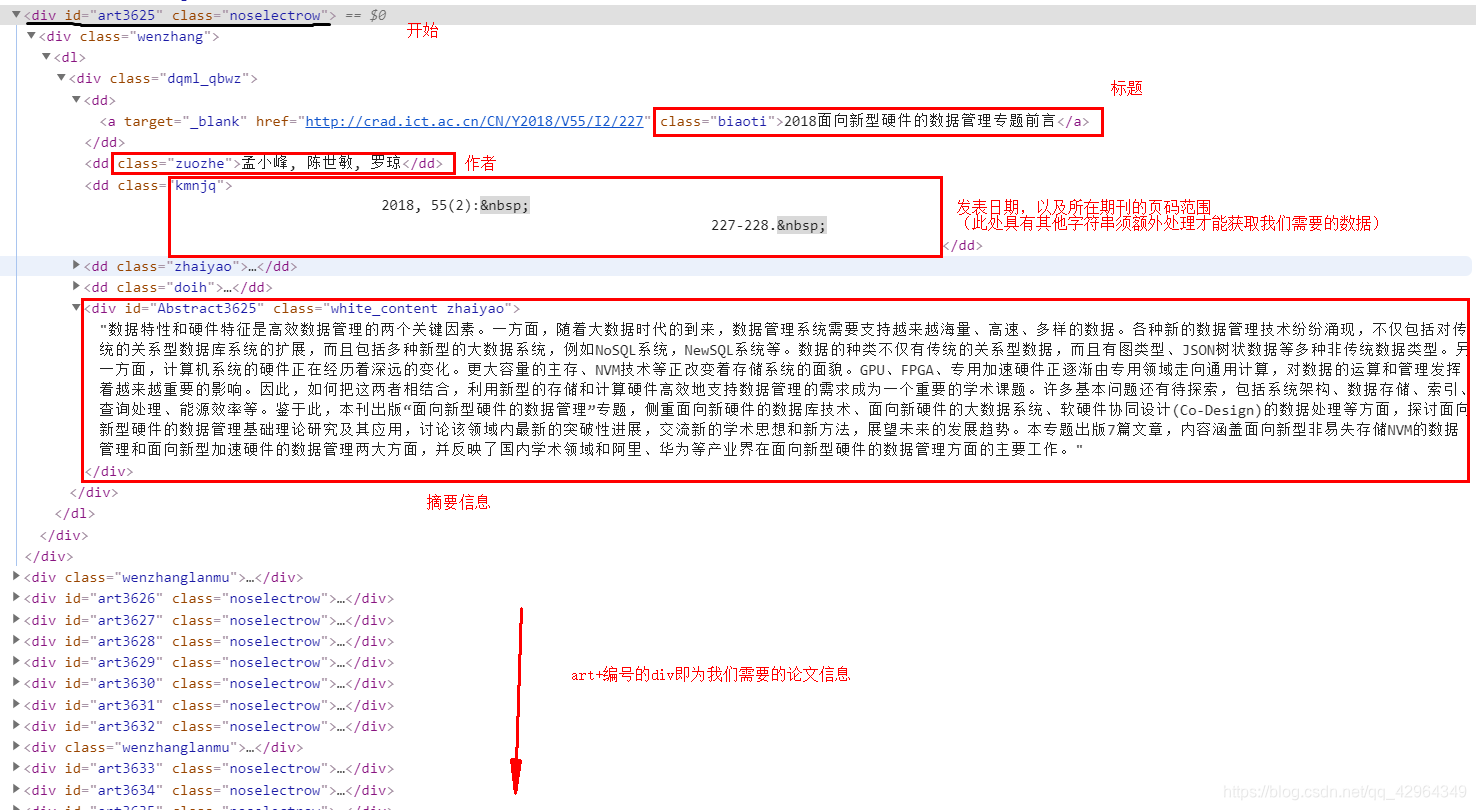
显然,我们可以利用 **re(正则表达式)**和 BeautifulSoup库 轻松获取我们需要的数据:
def parsePage(infoList, html):
soup = BeautifulSoup(html,"html.parser")
item = soup(name='a',attrs={"class":"biaoti"})
biaoti = re.findall(r'target="_blank">(.*?)</a',str(item),re.S)
item = soup(name='dd',attrs={"class":"zuozhe"})
zuozhe = re.findall(r'class="zuozhe">(.*?)</dd',str(item),re.S)
item = soup(name='dd',attrs={"class":"kmnjq"})
fanwei = re.findall(r'class="kmnjq">(.*?)<',str(item),re.S)
fanwei = re.sub('[\r\n\t\xa0]','',''.join(fanwei))
fanwei = re.sub('doi:','',''.join(fanwei))
fanwei = fanwei.split('.')
item = soup(name='div',attrs={"class":"white_content zhaiyao"})
zhaiyao = re.findall(r'">(.*?)</div',str(item),re.S)
for i in range(len(biaoti)):
global count #一个全局变量,用于统计总爬取数据条数
infoList.append((count,biaoti[i],zuozhe[i],fanwei[i],zhaiyao[i]))
count += 1
上述函数中,我们通过正则表达式和 BeautifulSoup库 获取数据,并将数据存入 infoList 列表中。
其中,额外需要注意的就是关于发表日期以及所在期刊页码信息的处理:
1.如图:

以上即为未经处理直接通过正则表达式从 soup 中截取出来的字符串!!

2.处理:
- 去除通过正则表达式从 soup 中截取出来的字符串中重复的
\r\n\t\xa0 - 去除无关字符串
doi
至此,我们需要的数据也已经全部存入 infoList 列表中了!!如下图:

存储数据(MySQL)
前置工作
首先,要在 python 中使用 MySQL,需要导入 python 的 pymysql库:
pymysql库 的下载:
pip install pymysql
pymysql库 的导入:
import pymysql
好了,接下来就可以在代码中连接数据库并进行插入操作啦!!!
数据库的设计
根据 infoList 列表存储的数据:序号 标题 作者 发表时间(期刊,页码) 摘要
设计 paperinfo表 来存储论文信息,如下:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for paperinfo
-- ----------------------------
DROP TABLE IF EXISTS `paperinfo`;
CREATE TABLE `paperinfo` (
`序号` int(0) NOT NULL,
`标题` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`作者` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`年,月,页码` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`摘要` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`序号`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
paperinfo表 的主键为 序号 。。
注意存储摘要使用的数据类型!!!
连接数据库
通过 connect() 函数连接数据库,函数内的参数包括 本机地址(host)、端口号(port)、数据库用户信息(包括用户名 user,密码 password)、连接的数据库 database、编码格式 charset 。
cursorclass=pymysql.cursors.DictCursor 是创建默认游标的意思,可以在连接的时候指定默认游标,也可以在需要使用时再创建 cursor = connection.cursor()。
#打开数据库连接
# localhost等效于127.0.0.1
#注意:这里之前已经创建了数据库adnm,database指定了连接的数据库
def getConnection():
connection = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="123456",
database="adnm",
charset="utf8",
cursorclass=pymysql.cursors.DictCursor
)
return connection
存储数据
将 infoList 列表插入 paperinfo 表中:
def insertData(infoList):
try:
connection = getConnection()
with connection.cursor() as cursor:
sql = "insert into paperinfo values(%s,%s,%s,%s,%s)"
cursor.executemany(sql,tuple(infoList))
connection.commit()
finally:
connection.close()
注意:
- 为有效避免因为错误导致的后果,使用
try...catch语句执行数据库的插入操作。 - 使用with读取使用游标可以省略游标的关闭(自动关闭)
- 对于sql语句,int(0),varchar(255),text 都通过占位符 %s 进行占位预处理操作
- cursor.executemany() 可以同时插入多组数据,如只需插入一组,则使用cursor.execute()
- connection.commit() 执行插入(对于插入、更新、删除等操作,需要使用connection.commit()来提交到数据库执行;而查询、创建数据库和数据表的操作不需要此语句。)
- 最后,关闭数据库连接 connection.close()
看看结果:

嘿嘿,是不是还可以呢!!感兴趣的小伙伴可以动手试试哦!!
另外,若有问题欢迎各位小伙伴互相交流。。。。
附上源码:资源
