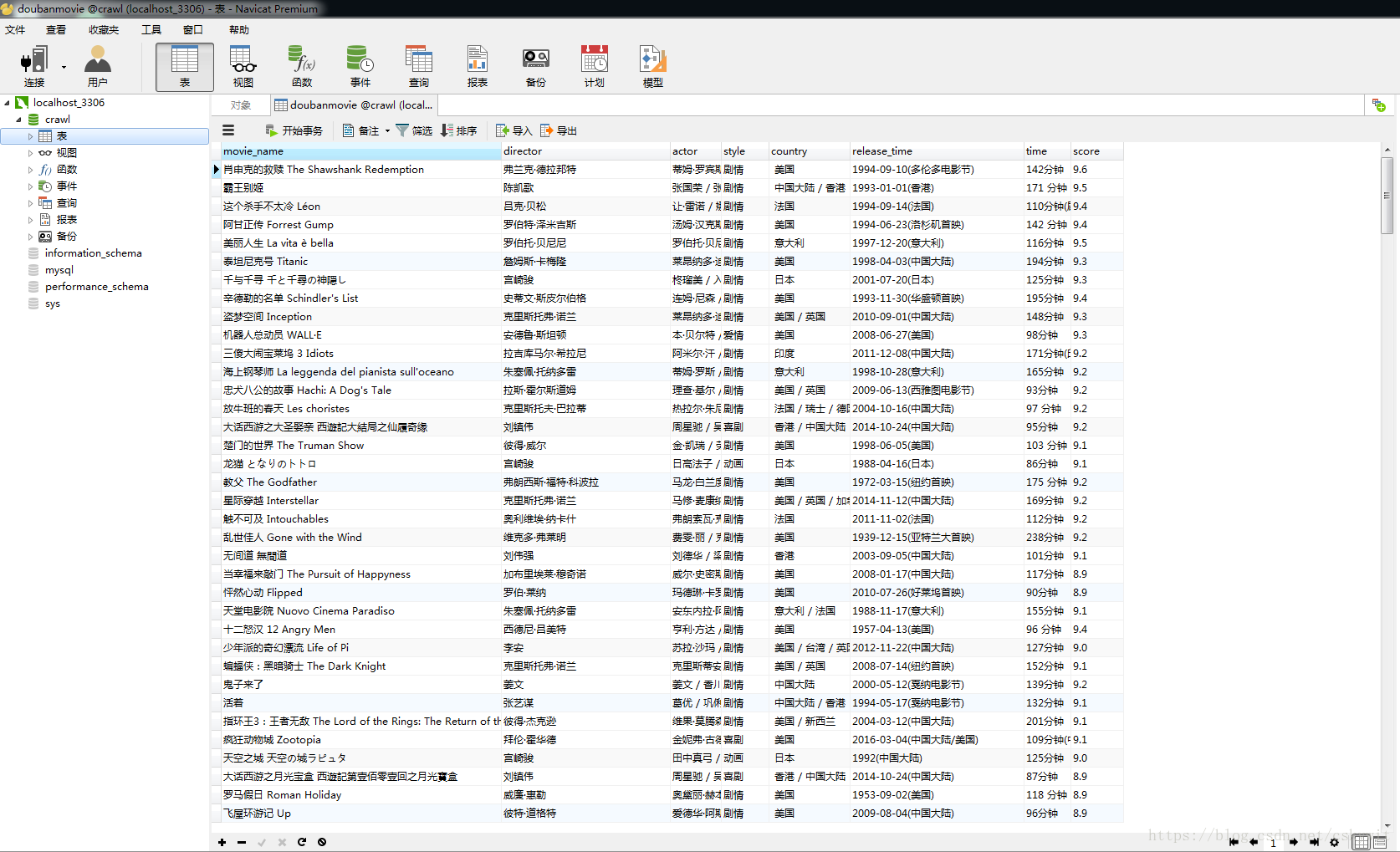
本次实验主要测试使用PyMySQL库写数据进MySQL,爬取数据使用XPATH和正则表达式,在很多场合可以用XPATH提取数据,但有些数据项在网页中没有明显特征,用正则表达式反而反而更轻松获取数据。直接上代码:
from lxml import etree
import requests
import re
import pymysql
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'
}
conn = pymysql.connect(host='localhost',user='root',passwd='123456',db='crawl',port=3306,charset='utf8')
cursor = conn.cursor()
def get_movie_url(url):
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
movie_hrefs = selector.xpath('//div[@class="hd"]/a/@href')
for movie_href in movie_hrefs:
get_movie_info(movie_href)
def get_movie_info(url):
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
try:
movie_name = selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0]
director = selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
actors = selector.xpath('//span[@class="actor"]/span[2]')[0]
actor = actors.xpath('string(.)')
style = re.findall('<span property="v:genre">(.*?)</span>',html.text,re.S)[0]
country = re.findall('制片国家/地区:</span>(.*?)<br/>', html.text, re.S)[0]
release_time = re.findall('上映日期:</span>.*?>(.*?)</span>',html.text,re.S)[0]
time = re.findall('片长:</span>.*?>(.*?)</span>',html.text,re.S)[0]
score = selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
cursor.execute(
"insert into doubanmovie (movie_name,director,actor,style,country,release_time,time,score) values (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(movie_name),str(director),str(actor),str(style),str(country),str(release_time),str(time),str(score))
)
except IndexError:
pass
if __name__ =='__main__':
urls = ['https://movie.douban.com/top250?start={}&filter='.format(str(i)) for i in range(0,250,25)]
for url in urls:
get_movie_url(url)
time.sleep(2)
conn.commit()
conn.close()结果已经存入mySQL数据库: