# 多线程爬取腾讯招聘职位信息并存入数据库
# mydb.py
import pymysql
class Mydb:
def __init__(self):
try:
self.conn = pymysql.connect('127.0.0.1','root','123456','han',charset='utf8')
self.cursor = self.conn.cursor()
except Exception as e:
print(e)
def execute(self,sql,data):
try:
row = self.cursor.execute(sql,data)
self.conn.commit()
return row # 返回影响行数
except Exception as e:
print('执行增删改失败')
print(e)
self.conn.rollback()
if __name__ == '__main__':
mydb = Mydb()
sql = 'insert into py07_58friend(`name`,`age`,`height`,`edu`,`img`) VALUES(%s,%s,%s,%s,%s)'
data = ("大美",16,170,'博士','')
row = mydb.execute(sql,data)
print(row)
# paqu.py
import threading
import requests
from bs4 import BeautifulSoup
import time
from mydb import Mydb
from queue import Queue
class MyThread(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
def __init__(self,task_q, mydb, lock):
self.task_q = task_q
self.mydb = mydb
self.lock = lock
super(MyThread, self).__init__()
# 如果线程启动则调用run方法
def run(self):
while not self.task_q.empty():
# 获取任务
fullurl = self.task_q.get()
print(fullurl)
response = requests.get(fullurl, headers=self.headers)
html = response.text
html = BeautifulSoup(html, 'lxml')
tr_list = html.select('tr')[1:-2]
for tr in tr_list:
position_name = tr.select('td a')[0].text
position_cls = tr.select('td')[1].text
position_num = tr.select('td')[2].text
position_loc = tr.select('td')[3].text
position_time = tr.select('td')[4].text
sql = 'insert into py07_location(p_name,p_type,p_num,p_loc,p_date) values(%s,%s,%s,%s,%s)'
data = (position_name, position_cls, position_num, position_loc, position_time)
# lock.acquire()
# self.mydb.execute(sql, data)
# lock.release()
with self.lock:
self.mydb.execute(sql,data)
# print(position_name, position_cls, position_num, position_loc, position_time)
if __name__ == '__main__':
mydb = Mydb()
lock = threading.Lock()
print(time.ctime())
task_q = Queue()
base_url = 'https://hr.tencent.com/position.php?start={}'
for i in range(0, 3000 + 1, 10):
fullurl = base_url.format(i)
task_q.put(fullurl)
thread_list = []
for i in range(20):
t = MyThread(task_q, mydb, lock)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print(time.ctime())
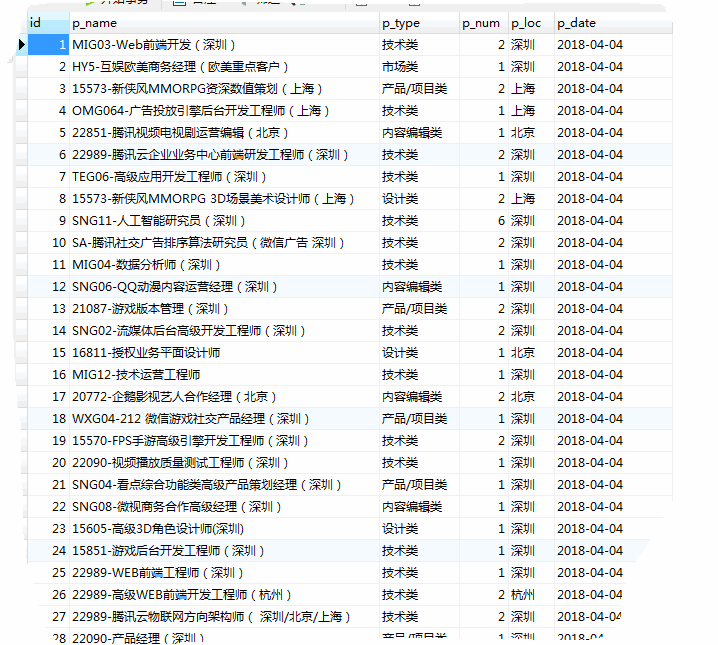
# 爬取结果如下:
兄弟连学python
Python学习交流、资源共享群:563626388 QQ