#CrawUnivRanjingA.py
import requests
from bs4 import BeautifulSoup
import bs4
import pymysql
db=pymysql.connect(host="localhost",user="root",password="admin",db="test",port=3306)
print('数据库连接成功')
cursor=db.cursor()
# cursor.execute()
# sql = """CREATE TABLE Daxue (
# 排名 int(3) NOT NULL,
# 学校名称 CHAR(10),
# 总分 float (2),
# 省市 varchar(10))"""
def getHTMLtEXT(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
a=0
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string,tds[2].string])
paiming=tds[0].text.strip()
xuexiaomingcheng=tds[1].text.strip()
zongfeng=tds[3].text.strip()
shengshi=tds[2].text.strip()
if a<20:
insert_into = ("INSERT INTO Daxue(排名,学校名称,总分,省市)""VALUES(%s,%s,%s,%s)")
data_into=(paiming,xuexiaomingcheng,zongfeng,shengshi)
cursor.execute(insert_into,data_into)
db.commit()
a+=1
def PrintUnivlist(ulist,NUM):
tplt="{0:<10}\t{1:{4}<10}\t{2:<10}\t{3:<10}"
print(tplt.format("排名","学校名称","总分","省市",chr(12288)))
for i in range(NUM):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))
def main():
uinfo=[]
url="http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html"
html=getHTMLtEXT(url)
fillUnivList(uinfo,html)
PrintUnivlist(uinfo,20)
main()
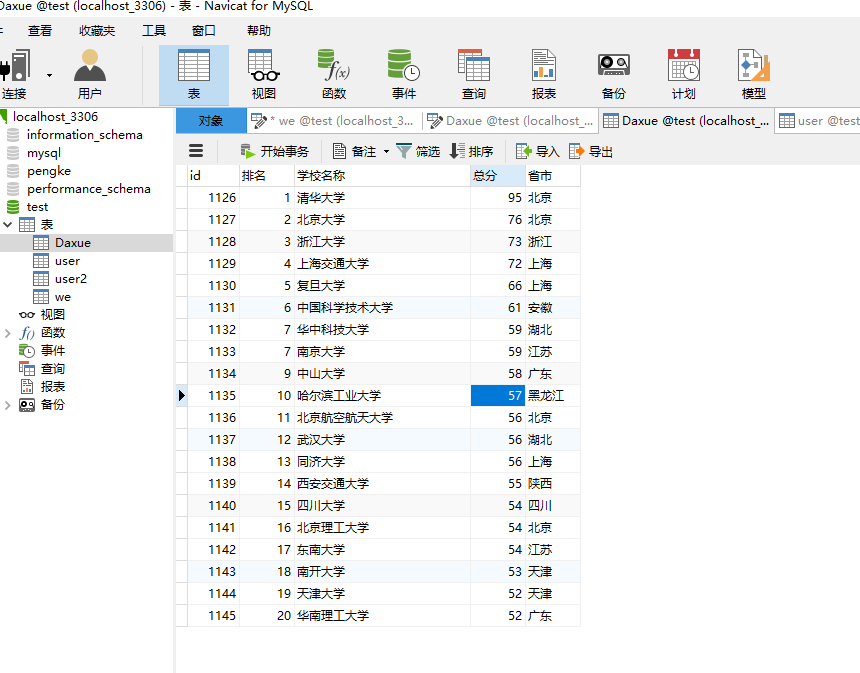
存入数据库后: