所有的算法都建立在模型的基础之上,模型没有建立好,再好的算法哪怕是神经网络也是白搭。
感知机
神经网络初期最重要的工具,但是感知机有一个严重的缺点,直接导致上个世纪90年代人工智能领域处于停滞的状态,直到支撑向量机诞生。支撑向量机几乎突破了所有的感知机的局限性。而主要的分类方法有3种:基于概率的分类器NB、朴素贝叶斯、SVM
模型的表示
神经元结构
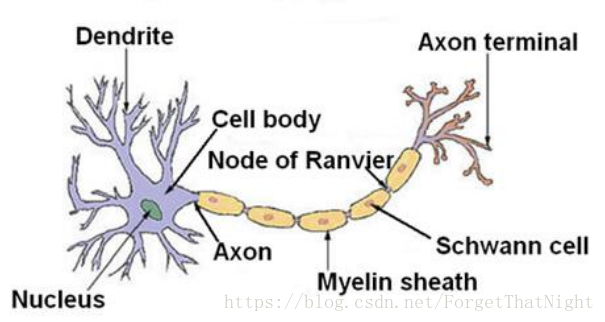
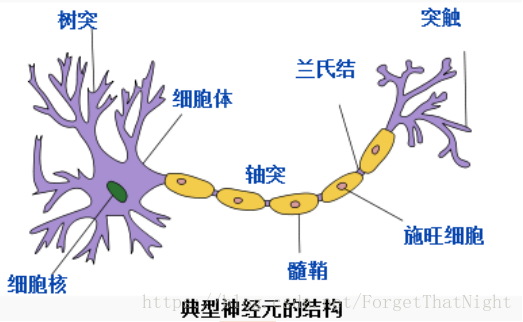
对神经元抽象结果,树突接收信号,比如性别分类,那么树突接收的是身高、声音等。声音的权重W会特别高,而身高这个特征并不是很强烈的刻画程度,给较低的权重W
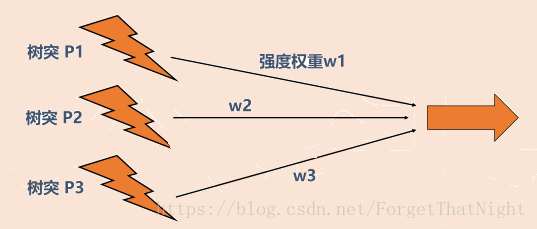
通过权重W得到汇总到细胞核的结果
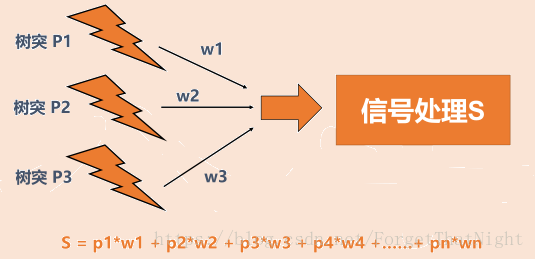
信号并不是直接传递,而需要先经过信号变换。比如信号压缩,然后交给传递函数,传递函数很重要。现在很多的人工智能算法区别就在传递函数,而左边的那块区别不大。有的用sigmod函数很轻松就能处理,非线性变化函数等。
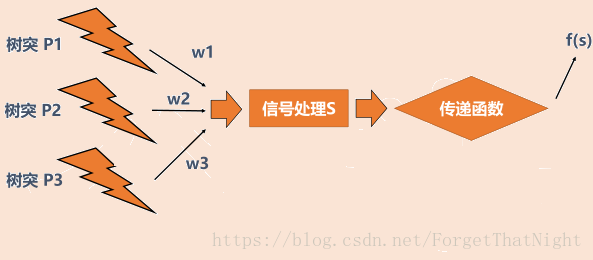
左边是所有信号汇总和的值,在加上一个内部强度值b,如果汇总的值大于b,则可以传递出去,否则,不能传递出去,然后得到最终的信号S
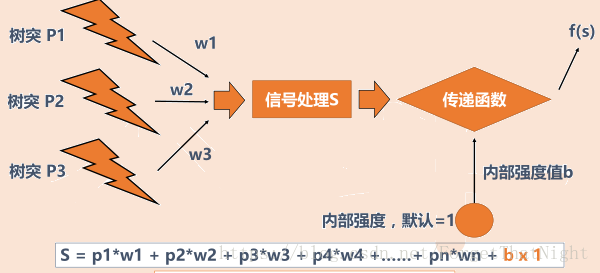
感知机
- 感知机是最最简单的神经网络
- 一个简单的例子:如何分辨香蕉和苹果?
– 用树突p1代表输入颜色刺激状态
– 用树突p2代表输入形状刺激状态
| 品种 | 颜色 | 形状 |
|---|---|---|
| 苹果 | 1(红色) | 1(圆形) |
| 香蕉 | -1(黄色) | -1(弯形) |
- p1(颜色)=1或-1 P2(形状)=1或-1
- 预设:w1=w2=1 b=0
- 代入之前的S公式后,发现:
– 对苹果的鉴别:s=1x1+1x1+0=2 > 0
– 对香蕉的鉴别:s=(-1)x1+(-1)x1+0=-2 < 0
完成识别! - 感知机的学习规则一种训练方法,目的是修改神经网络的权值和偏置
– w(new)=w(old)+ep
– b(new)=b(old)+e
– e表示误差,e=t-a,t为期望输出,a为实际输出 - 回到刚才的例子,预设w1=1,w2=-1,b=0
– 苹果的形状和颜色输入属性均为1,得到:s=p1*w1+p2*w2+b=1-1+0=0
– 期望结果是1,实际得到0,错误!!!这个时候希望机器自己去学习
– 计算误差e=t-a=1-0=1 —学习得到的误差—期望输出1-实际输出0 - 将误差e=1代入权重更新公式:w1、w2、b从(1,-1,0)更新为(2,0,1)
– w1(new) = w1(old) + e*p1 = 1+1x1=2
– w2(new) = w2(old) + e*p2 = -1+1x1=0
– b(new) = b(old) + e = 0+1 =1 - 将新的权重(2,0,1)代入感知机
– s=p1*w1+p2*w2+b=1x2+1x0+1=3 > 0 - 纠正误差后,苹果判定正确!–得到的模型就是这3个数(2,0,1),带入公式完成分割
缺点:
– 仅在线性可分的情况下有效,面对XOR问题(相同的值XOR为0,不相同的值XOR为1),机器学习学不出来得到参数的,不会收敛
• 0 xor 0 = 0
• 0 xor 1 = 1
• 1 xor 0 = 1
• 1 xor 1 = 0感知机
– 最简单的线性分类器
– 最简单的神经网络
• 神经细胞的抽象
– f(x,w,b)=sign(wx+b)
– x:样本
– w,b:参数
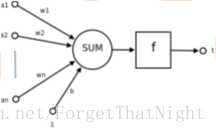
感知机目标函数
标签yi是一个有限集合,如果是二分类那么就是-1或者+1,而有些错分的情况越少越好,但是怎么让最小化错误率?通过公式来解决,I()为指示函数,条件成立则输出0,一旦预测值和真实值不相等则条件不成立,则输出一个1,如果存在一个1则一定存在错分的样本,值越大错误越多

换个函数,去掉sign,如果分错了即预测值和真实值不相等,那么预测值*真实值(一个为负数一个为正数)<0,然后当做我们的loss函数

期望找到一个w,b,即我们要训练的模型。当预测值和真实值不相等时,分别对w,b求导。通过特征xi和学习率循环更新w和b,结合前面更新b和w的公式

整体算法
– 1、随机设定w,b的值
– 2、用当前的(w,b)轮流对所有训练点分类,如果分错,更改(w,b)的值,继续
– 3、重复步骤2,直到线将所有点正确分类
问题:
– 算法收敛么?
– 如果收敛,收敛结果为?- 训练集线性可分:存在某个w,b以及正数a,下面公式是的对所有训练样本都满足:
- 如果线性可分:那么感知机算法一定可以在有限步内收敛到零训练错误线性分类器
- 如果线性不可分(比如亦或问题):那么不收敛
无穷多解,找不到最优解

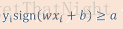
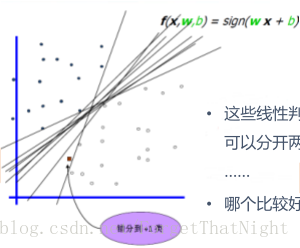
感知机不足
• 线性限制
• 1969年,证明感知机不能处理异或问题
– 导致人工智能领域的停止和低潮
支持向量机(support vector machine,SVM)
• 线性可分:硬间隔SVM
• 线性不可分:软间隔SVM
• 非线性:Kernel SVM

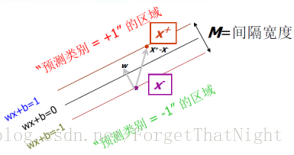
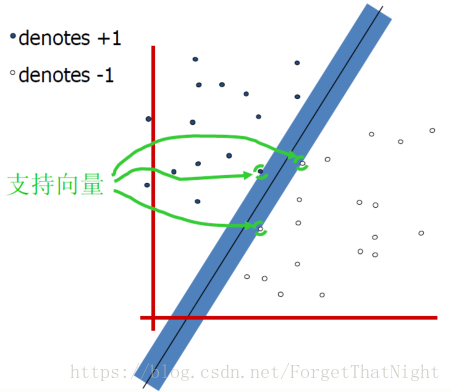
间隔: 分界面到最近样本点的距离(2倍)
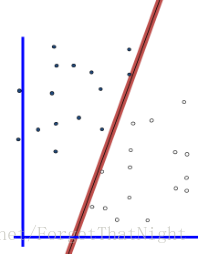
- 最大间隔分类器:在无穷多个支撑平面中选择间隔最大的分类器
– 使间隔宽度最大的线性分类器
– 这是svm最简单的情形
– 支撑向量:支撑面上边界的几个向量,决定了得到的哪个线,而其他的向量完全无关,而支撑向量有w,b共同决定
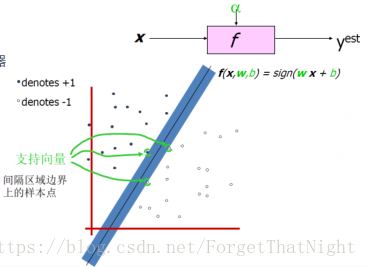
计算间隔
- 线性可分:
– 对所有正样本wx+b>0 所有正样本在线上边
– 对所有负样本wx+b<0 所有负样本在线下边
– 同时增大w和b,不影响线性判别面的位置
– 调整w和b的大小,使得: - 对正样本wx+b>=+1
- 对负样本wx+b<=-1
– 于是,对支持向量:
间隔M等于W的模分之2,期望是M最大,即求W的模最小
- support vector machine 目标
– Vapnik 1995提出
– 是空间分割模型,非概率模型
– 在所有可正确分类训练数据的超平面中,寻找满足最大间隔的面 - 目标1:正确区分所有训练样本–所有正样本满足不等式1,所有负样本满足不等式2,则2个不等式可以简化为一个不等式3
- 目标2:最大化间隔M
等价于最小化w的模,也等价于w的内积
- 转化为一个关于w,b的二次规划问题:没有约束的优化过程用求导解决,有约束的优化求极值问题用拉格朗日来解决
- 原问题:
- 对每个约束引入拉格朗日乘子ai ≥ 0 得到:(让约束变到我们的优化问题里面去)
- 最优解对w,b求导为0,则有:
- 带入L,则得到对偶问题:(得到一个没有w,b的一个方程,而是一个关于拉格朗日乘子ai的问题,更方便计算)
- 最优解有如下形式:b = y - wx
- w是所有训练数据xi的线性组合。性质:如果组合系数不为零(ai ≠ 0),那么对应的xi是支持向量,否则不是支持向量,a=0
- 分类函数f(x)=wx+b则有如下形式:
- 注意上式依赖于测试数据x和支持向量xi的内积(而无需知道x和xi的具体值,只需要知道内积值)
– Kernel SVM将用到这个性质
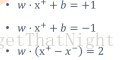
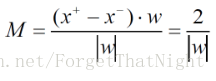
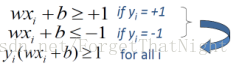

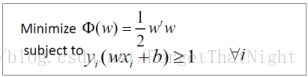
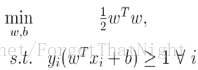
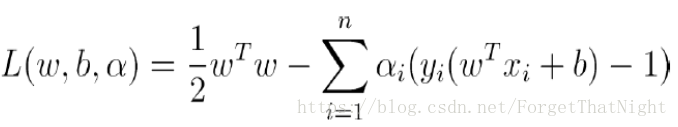
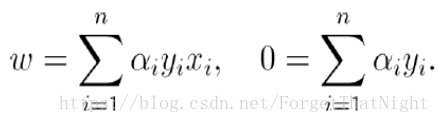
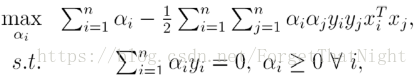
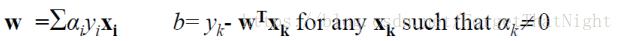
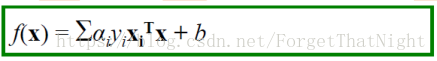
support vector machine优势
模型只取决于支持向量
如果样本量不大,10w-20W左右,直接用SVM,通常效果不错,也可以作为baseline,当做分类算法及格的标准线
support vector machine 与线性不可分的情况
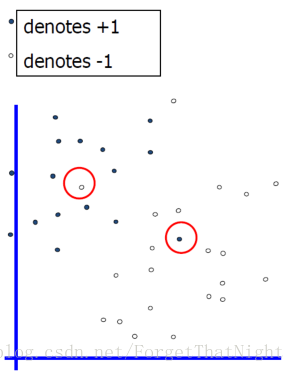
- 硬间隔:要求所有训练数据必须被线性分类器正确地区分在间隔外的相应区域内
- 软间隔-样本不是完全可以先行分割,分错个别样本的情况
– yi ( wxi + b) ≥ 1
– 不存在训练误差 - 如果训练数据不是线性可分的(不存在任何线性分类器可以将其正确分类),或者数据存在噪声怎么办?
–以代价为前提下的样本移动,要求:让所有错分样本的移动距离尽量少—>衡量距离的方式放到优化目标里面 - 引入松弛变量ξi ,使得错分样本得到惩罚(错分样本本身不符合该条件,强行加ξi让其满足条件)
– 最小化松弛项,同时最大化间隔
ξi:惩罚的代价,比如驾照的分数
C:每一个代价对应的分数,比如驾照每一分对应的罚款金额
– 错分样本对应的ξi ≥ 1,所以: ∑ξi ≥ 错分样本个数
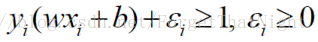

硬间隔vs软间隔
- 硬间隔
- 软间隔-样本不是完全可以先行分割,分错个别样本的情况


线性support vector machine总结
• 分类面是一个线性超平面
• 最重要的训练样本是那些支持向量,这些支持向量决定了分类面
• SVM问题是一个二次规划问题,可以使用多种方法得到最优解
• SVM对偶问题中,训练数据只出现在内积计算中

非线性SVM
• 对于线性可分数据,线性SVM表现很好:
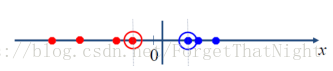
• 对于训练数据本身存在复杂的非线性关系,很难用线性模型较好地分类:

• SVM的解决方法:映射到高纬的特征空间中
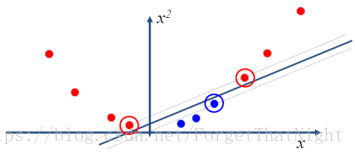
• 2维映射到3维:原始空间中任意形状的两个区域,总是可以在某些高纬特征空间中映射成为线性可分的两个区域
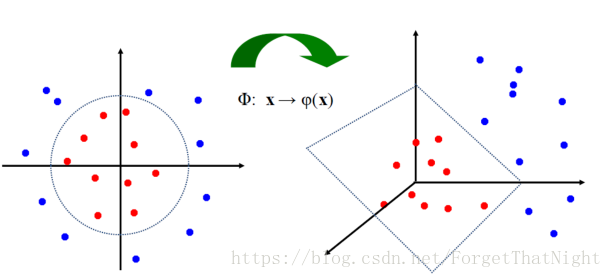
核函数–用来解决非线性问题,有助于得到高维空间的内积
• SVM分类器的训练和预测都仅依赖于样本对的内积值K(xi,xj) = xiTxj
• 如果样本映射到高维空间:x → φ(x) ,那么内积则变成:K(xi,xj) = φ(x)iTφ(x)j
• 核函数对应的某个特征空间的内积。
• 例子(用2次多项式的核函数来映射):
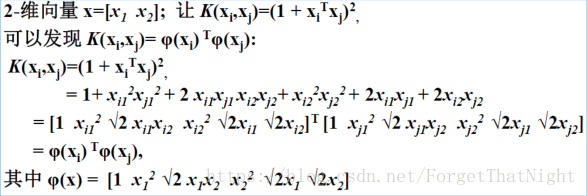
核函数例子:即映射x → φ(x)的示例
• 线性:K(xi,xj) = xiTxj
• P次多项式:K(xi,xj) =(1+ xiTxj)P
• 高斯核(RBF核)(其特征空间是无限维空间,此核可以用来逼近任意复杂的分类面):
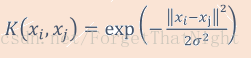
• Sigmoid:K(xi,xj) =tanh(β0 xiTxj + β1)
使用核函数的SVM
• 对偶问题:
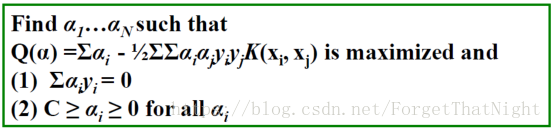
• SVM分类器为:
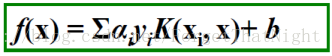
• 优化过程和最优解形式完全相同,只是把线性内积换成核函数
• SVM在映射后的高维特征空间中构建超平面进行分类
• 不需要知道到特征空间的映射关系,只需要知道核函数(对应高维空间的内积)
多值分类
- One-vs-ALL SVM不能解决多分类,可以先转化为2分类
– 为每一个类,建立一个二值分类器。该类别为正例,其他所有类别为负例
– 训练数据不平衡 - ALL-vs-ALL
– 为类别集合中任意两个类建立一个二值分类器
– 训练快,预测复杂度高