SVM算法与之前介绍的逻辑回归三方有点类似。。
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
具体原理:
- 在n维空间中找到一个分类超平面,将空间上的点分类。如下图是线性分类的例子。
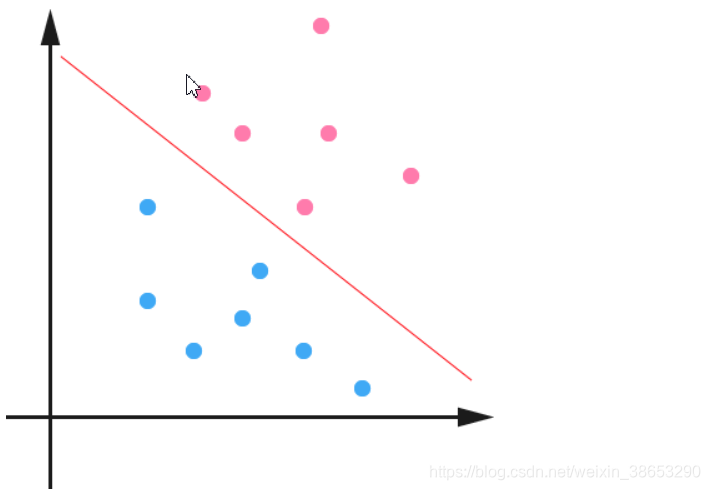
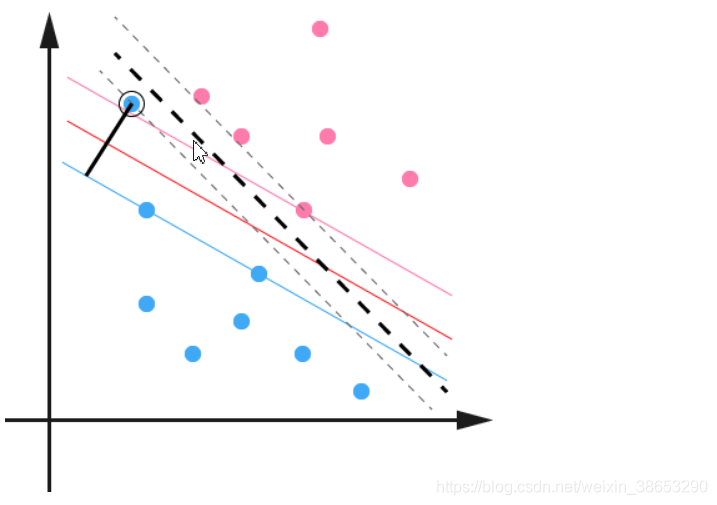
- 一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。SVM就是要最大化这个间隔值。而在虚线上的点便叫做支持向量Supprot Verctor。
实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如下图);
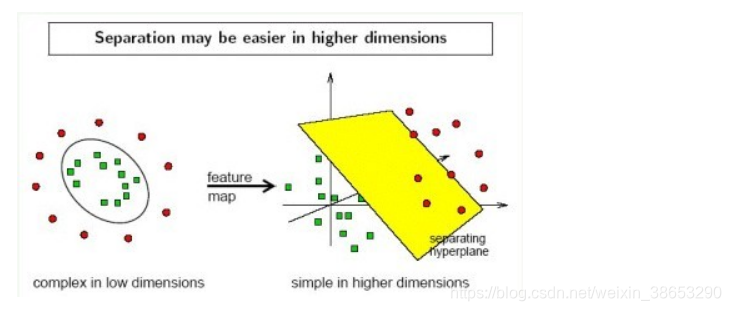
3. 线性不可分映射到高维空间,可能会导致维度大小高到可怕的(19维乃至无穷维的例子),导致计算复杂。核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
4.使用松弛变量处理数据噪音
案例如下:
import org.apache.spark.mllib.classification.SVMWithSGD
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.feature.StandardScaler
import org.apache.spark.mllib.regression.LabeledPoint
object SVM {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("spark").setMaster("local[3]")
val sc = new SparkContext(conf)
val inputData = MLUtils.loadLibSVMFile(sc, "healthyColl.txt")
val vectors = inputData.map(_.features)
val scalerModel = new StandardScaler(withMean=true, withStd=true).fit(vectors)
val normalizeInputData = inputData.map{point =>
val label = point.label
val features = scalerModel.transform(point.features.toDense)
new LabeledPoint(label,features)
}
val splits = normalizeInputData.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
val svm = new SVMWithSGD()
svm.setIntercept(true)
val model = svm.run(trainingData)
val rightRate = testData.map{p=>
val label = p.label
val predict = model.predict(p.features)
val result = label==predict match {case true => 1 ; case false => 0}
result
}.mean()
println("正确率:\t"+rightRate)
println("w:\t"+model.weights)
}
}
训练集:
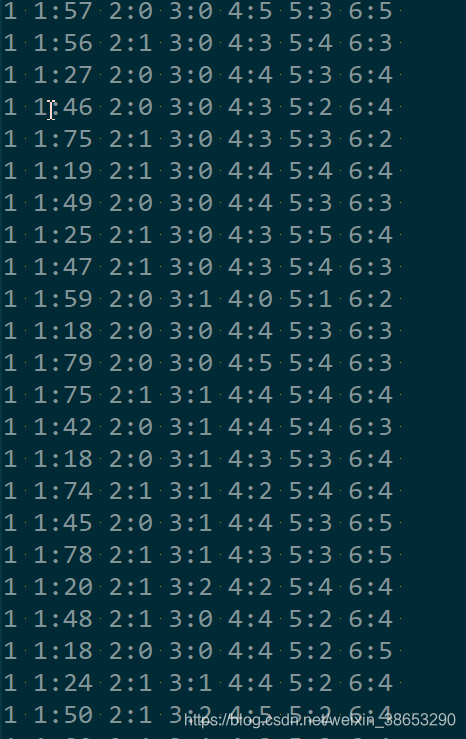
结果:
