Spark2.1版本目前只实现了linear SVM(即线性支持向量机),非线性SVM及核技巧目前还没有实现。因此本篇主要介绍的是Spark中的线性SVM及参数求解。SVM的理论及推导可以参考支持向量机通俗导论(理解SVM的三层境界)
由于Spark实现的是线性SVM,在此,我将简单介绍一下线性分类器与线性可分、线性SVM、线性不可分下的线性SVM等基本概念与原理,最后再结合Spark介绍以下线性SVM的实现。
一、线性分类器与线性可分:
如果在n维空间中能找到一个分类超平面,将空间上的样本点正确分类,则称样本点线性可分,找到的这个分类超平面称为线性分类器。在1维空间中分类超平面即为点,在2维空间中分类超平面即为直线,在3维空间中分类超平面即为平面...在n维空间中称为分类超平面。
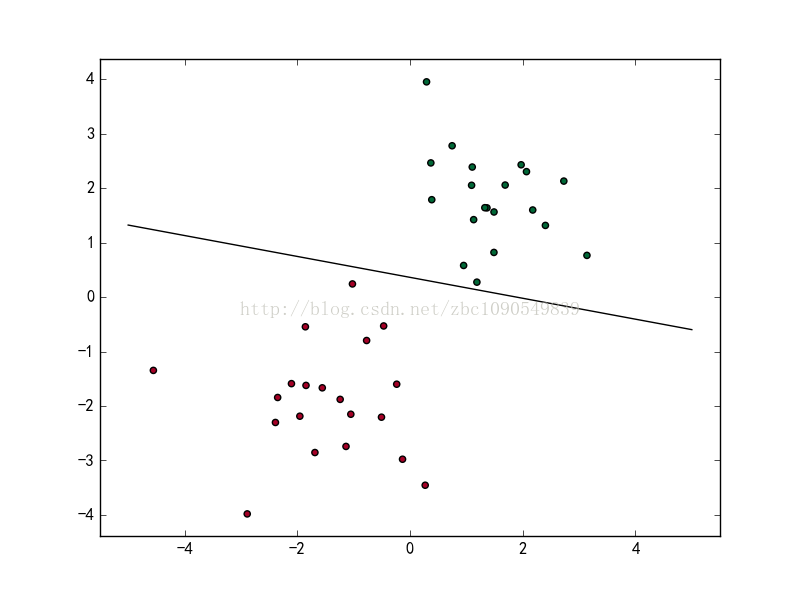
如上图所示,在2维空间中找到了一条直线,将红色的点集和绿色的点集分开。图中的直线即为一个线性分类器,这个线性分类器的分类函数可以表示为:
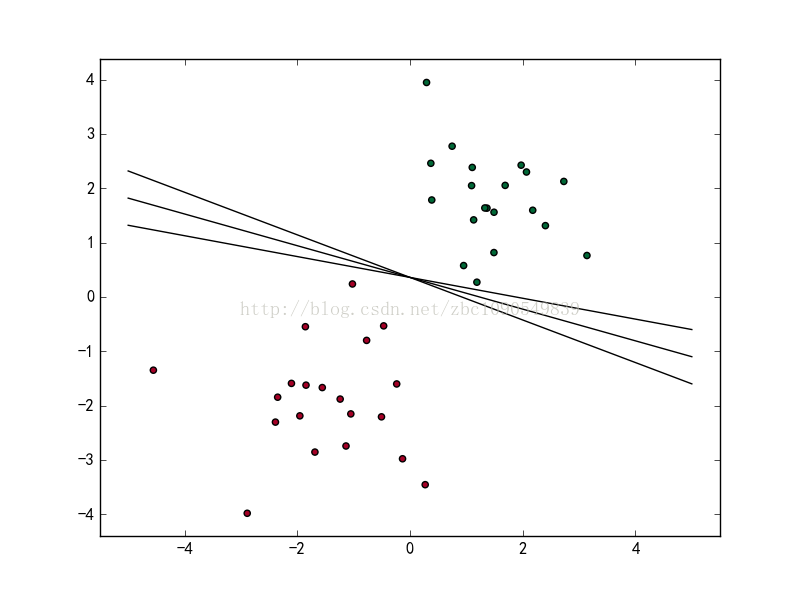
当f(x) 等于0的时候,x便是位于超平面(此处为直线)上的点,而f(x)大于0的点对应 y=1 的数据点(此处为绿色的点),f(x)小于0的点对应y=-1的点(此处为红色的点),对这条直线做轻微的平移或者旋转,得到的直线仍然可以将上述样本集正确分类:
二、线性SVM:
有这么多条直线能够将样本集正确分类,那么怎么样才能找到一个最优的划分直线呢?直观来看,一个样本点在被正确划分时,其离划分直线的距离越远,该样本点被分类正确的置信度就越高,即越有理由相信这次分类的结果。
那么问题就转化成:找到这样一条直线,在能够正确分类样本集的同时,其离正例样本点的距离和离负例样本点的距离都尽量大,即分类间隔最大化。
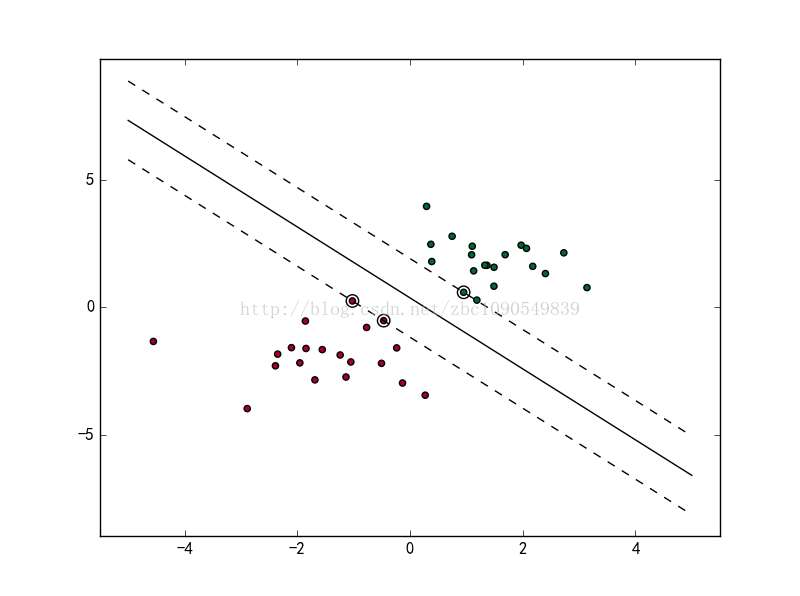
这样构造出来的线性分类器即为线性SVM。图中直线即为线性SVM的决策边界,两侧的虚线就是support vector所在的面,虚线之间的间隙就是我们要最大化的分类间的间隙。
要最大化分类间隔,可转化为以下最优化问题(函数间隔到几何间隔的推导可以参考支持向量机通俗导论):
(1)
如图,在二维空间内,不可能找到一条直线,将上述两类样本点完全正确分类。既然不能够完全正确分类,那么换个思路,如果能够找到一条直线,能够将大部分样本点正确分类就OK了,剩下的被误分类的,只要使其误分类的代价越小就可以了。于是,在上面优化公式的基础上,增加一个对误分类样本的惩罚项:
其中
由于加入了惩罚项,优化的条件就不用得到保证了。因此可以转化为下述的优化问题:
对机器学习熟悉的读者可能很快注意到,上式的最小化优化目标相当于一个损失函数,而前半部分即为hinge损失函数,后半部分即为我们熟悉的L2正则化项。于是线性SVM的求解便转化为我们熟悉的损失函数的无约束的最优化问题了。
我们经常看到的SVM求解往往是将式(1)根绝拉格朗日对偶性,通过求解对偶问题来得到原始问题的最优解,这其实是最大化分类间隔的直接推导结果。
从误分类而带来的代价来看,对于“+”类(y=1)的数据 ,我们希望 ,对于“-”类(y=-1)的数据 ,我们希望。总之,我们希望。那么,如果实际上 符号为负,或者虽然符号为正但离0不够远,具体来说是 ,我们就认为这个分类错误(或“不够正确”)带来了大小为 的损失。于是目标函数(损失函数)就是 :
SVM的训练变成了这个目标函数下的无约束优化问题。
后面的L2正则化项不仅是为了降低模型的结构风险(认为模型越复杂,结构风险越大),同时也表达了SVM最大化分类间隔的思路(即最小化正则化项,就是最大化margin)。
下面来具体看看线性SVM的Spark实现
一、SVMModel
SVMModel是Spark定义的线性SVM模型,继承自GeneralizedLinearModel和ClassificationModel等。其覆写了父类的predictPoint方法.
predictPoint方法是SVMModel最底层的预测函数,SVMModel其他的预测函数都是对其的封装。
override protected def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double) = {
val margin = weightMatrix.asBreeze.dot(dataMatrix.asBreeze) + intercept //wx+b
//threshold默认值为0,可由用户自定义
threshold match {
case Some(t) => if (margin > t) 1.0 else 0.0//SVM的类标记必须是{0,1}
case None => margin
}
}二、SVMWithSGD
SVMWithSGD是Spark实现SVM的参数求解的类。我们跟着代码来看看SVMWithSGD内部的一些变量:
@Since("0.8.0")
class SVMWithSGD private (
private var stepSize: Double,//迭代步长
private var numIterations: Int,//总的迭代次数
private var regParam: Double,//正则化系数
private var miniBatchFraction: Double)//每次迭代的样本规模
extends GeneralizedLinearAlgorithm[SVMModel] with Serializable {
private val gradient = new HingeGradient()
//间距损失函数
private val updater = new SquaredL2Updater()
//L2正则化下的参数迭代器
@Since("0.8.0")
override val optimizer = new GradientDescent(gradient, updater)
.setStepSize(stepSize)
.setNumIterations(numIterations)
.setRegParam(regParam)
.setMiniBatchFraction(miniBatchFraction)
//后面的代码略过
}参数的更新过程可以参考 spark.mllib源码阅读-优化算法3-Optimizer。
重点来看一下这个函数的求导过程:
class HingeGradient extends Gradient {
override def compute(data: Vector, label: Double, weights: Vector): (Vector, Double) = {
val dotProduct = dot(data, weights)
//Spark SVM要求样本的类标记是{0, 1},在这里将其转为转换成{-1,1}
val labelScaled = 2 * label - 1.0 //
//labelScaled * dotProduct < 1.0 被认为是存在分类错误风险的点
//labelScaled * dotProduct >=1时正确分类
//当labelScaled * dotProduct <1 时分类错误,计算损失函数及其偏导数
//1-ywx对w的偏导数为 -yx
if (1.0 > labelScaled * dotProduct) {
val gradient = data.copy
scal(-labelScaled, gradient)//gradient = -labelScaled * gradient = -y*x
(gradient, 1.0 - labelScaled * dotProduct)
} else {
(Vectors.sparse(weights.size, Array.empty, Array.empty), 0.0)
}
}SVM的数学模型和原始的求解过程都比较复杂,但是换一个角度看问题,将其转化为误分类样本下的hinge损失函数来等价原始问题的软间隔项,同时用L2正则化项来等价原始问题的最大化间隔项。SVM的理解和参数的求解就变得容易多了。