版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/82778934
交流QQ: 824203453
- Spark概述
- 什么是Spark(官网:http://spark.apache.org)
spark中文官网:http://spark.apachecn.org
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。
-
- Spark和Hadoop的比较
mapreduce 读 – 处理 - 写磁盘 - 读 - 处理 - 写
spark 读 -- 处理 -- 处理 --- (需要的时候)写磁盘 --- - 写

Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,(spark与hadoop的差异)具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)

其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错。
最后,Spark更加通用。mapreduce只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。
支持的运算平台,支持的开发语言更多。
spark 4 种开发语言:
scala,java,python,R
总结:
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。

Spark支持Java、Python和Scala和R的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
一站式解决方案 离线处理 实时处理(streaming) sql
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
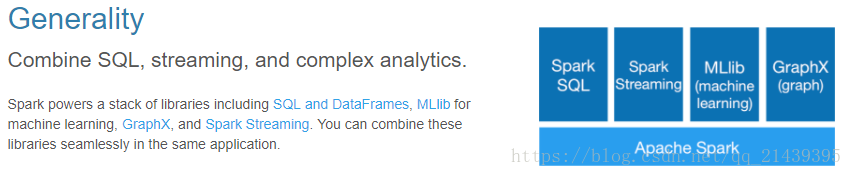
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。

- spark 的部署模式:
- local 本地模式,只要机器上有spark的安装包, 仅仅是用于测试
不写master -- master local 一个线程 local[2] local[*] 模拟使用多个线程
- Standalone spark自带的集群模式 --master spark://hdp-01:7077
- yarn 把spark任务,运行在yarn --master yarn
- mesos 把spark任务,运行在mesos资源调度平台上 --master mesos
- Spark集群安装
准备4台Linux服务器,最低要求2台
hdp-01 192.168.8.11
hdp-02 192.168.8.12
hdp-03 192.168.8.13
hdp-04 192.168.8.14
在hpd-01上安装master 主节点
在hdp-02 hdp-03 hdp-04 上安装worker 从节点
(注意: master和worker可以安装在同一台机器中)
-
- 集群环境准备
1,确保集群中各节点的防火墙是关闭的。
| 查看防火墙状态 # service iptables status 关闭防火墙 # service iptables stop 永久关闭防火墙 # chkconfig iptables off |
2,确保主节点到各从节点的免密登录配置好了
(注意:从节点之间的免密登录无需配置)
从Master节点到worker节点的免密登录
| 在master机器上执行: # ssh-keygen # for i in 2 3 4; do ssh-copy-id hdp-0$i; done |
3,在各节点上安装jdk,确保jdk1.8+ 已安装
注意:安装spark时,无需安装scala

-
- 上传并解压安装包
上传spark-安装包到Linux上
解压安装包到指定位置
# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C apps/
Spark安装包目录结构:
| bin 可执行脚本 conf 配置文件 data 示例程序使用数据 examples 示例程序 jars 依赖jar包 LICENSE licenses NOTICE python pythonAPI R R语言API README.md RELEASE sbin 集群管理命令 |
-
- 部署standalone集群
进入到Spark安装目录
# cd /root/apps/spark-2.2.0-bin-hadoop2.7
进入conf目录并重命名并修改spark-env.sh.template文件
# cd conf/
# mv spark-env.sh.template spark-env.sh
# vim spark-env.sh
在该配置文件中添加如下配置
| export JAVA_HOME=自己机器的jdk安装目录 export SPARK_MASTER_HOST=自己机器中Master所在的主机名 export SPARK_MASTER_PORT=7077 |
保存退出
重命名并修改slaves.template文件
# mv slaves.template slaves
# vim slaves
思考?为什么要修改slaves配置文件
在该文件中删除localhost,并添加子节点所在的位置(Worker节点)
| hdp-02 hdp-03 hdp-04 |
保存退出
-
- 安装包分发
将配置好的Spark安装文件夹 拷贝到其他节点上
单独拷贝:
# scp -r /root/apps/spark-2.2.0-bin-hadoop2.7/ hdp-02:/root/apps/
批量拷贝:
| # cd /root/apps # for i in {2..4};do scp -r spark-2.2.0-bin-hadoop2.7 hdp-0$i:$PWD ;done |
Spark集群配置完毕,目前是1个Master,3个Worker,在Master(hdp-01)上启动Spark集群
-
- 启停操作
- 单独启停
- 启停操作
单独启动master和单独启动worker:
在master所在节点启动master
[root@hdp-01 sbin]# ./start-master.sh
在worker节点单独启动一个worker。必须指定master的URL
[root@hdp-02 sbin]# ./start-slave.sh spark://hdp-01:7077
单独启动master,启动众workers(在Master所在节点上执行):
# start-master.sh
# start-slaves.sh
这里获取的是slaves配置文件中的主机名
单独停止:
# stop-slaves.sh
# stop-master.sh
-
-
- 批量脚本启停
-
# start-all.sh
停止:
# stop-all.sh
为了能方便使用,配置一下环境变量:
export SPARK_HOME=/root/apps/spark-2.2.0-bin-hadoop2.7

配置环境变量的注意事项:
hadoop/sbin的目录和spark/sbin可能会有命令冲突:
start-all.sh stop-all.sh
解决方案:
- 把其中一个框架的sbin从环境变量中去掉;
- 改名 hadoop/sbin/start-all.sh ---> start-all-hdp.sh
启动后执行jps命令,主节点上有Master进程,其他子节点上有Worker进程,
登录Spark管理界面查看集群状态(主节点):http://hdp-01:8080/
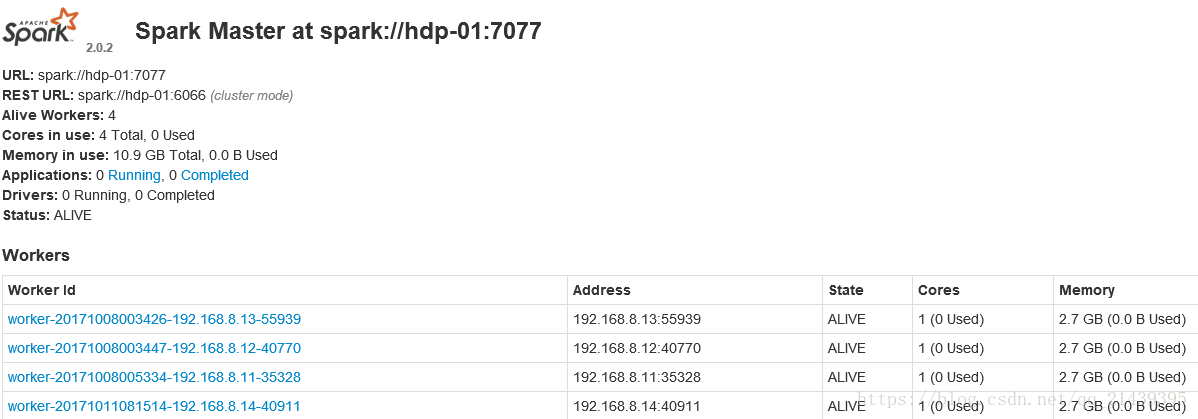
到此为止,Spark集群安装完毕。
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/82778934
交流QQ: 824203453