有监督学习是指我们给算法一个数据集,并且给定正确的答案。
这么说可能不太好理解,举个例子。如下图所示为房子面积及对应的出售价格的一个数据集,以红叉表示。(图表来自吴恩达教授讲解的机器学习视频截图)。
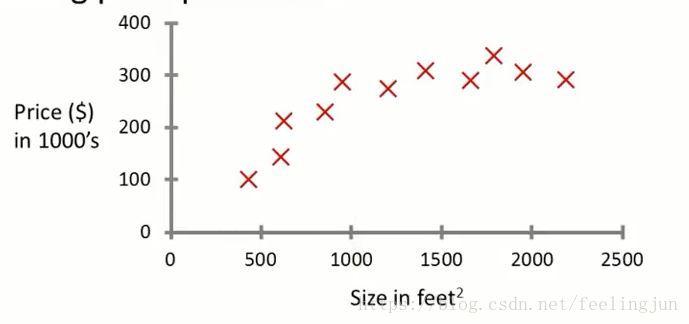
现在有一套房子的面积是750平,请问该套房子出售多少合适?
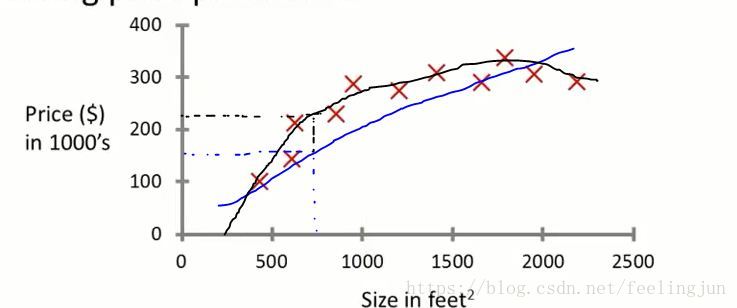
如果我们根据这些数据计算出图中的蓝色线,这样估计该房子大约值160K;而如果我们根据这些数据拟合出黑色曲线,用该曲线计算的话,该套房子的价格大约在220K左右。怎么才能给出一个最准确的结果就是机器学习的需要计算的。这就是有监督学习的过程。更准确来说,这就是回归问题。
在有监督学习中,还有一个常常提到的概念,那就是分类。例如,在文字识别中,假设这里有一个数据集包含A到Z的英文字母的数据集,我们现在有一个字母,需要判定它是这26个字母中的哪一个时,这就是分类问题(只不过是一个多分类而已,每个字母一个类)。分类肯定是有依据的,这就需要用到特征这一概念,例如,我们可以用到字母的梯度特征,角点特征,笔画特征等等。根据特征,让机器去对输入的字母进行判定,分类中概率最大的就是最终的输出结果。
无监督学习和有监督学习在数据上有很大的差别,在有监督学习的数据中,我们知道数据的属性(如房子的面积对应的价格)、标签(如每个字母一个类,一个类对应一个标签)。而在无监督学习过程中,所有的数据都是一样的,没有区别。但是,无监督学习算法可能会根据数据的结构判定该数据包含不同的聚类(可以理解为将数据聚集为不同类),这就是一个新概念——聚类。