在常见的卷积神经网络的最后往往会出现一两层全连接层,全连接一般会把卷积输出的二维特征图(feature map)转化成(N*1)一维的一个向量,这是怎么来的呢?目的何在呢?
举个例子:
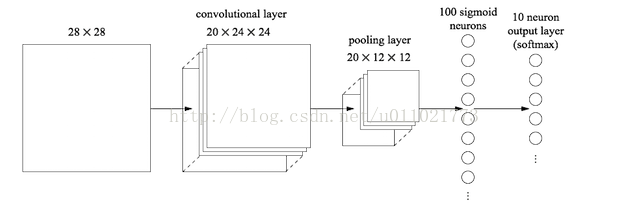
最后的两列小圆球就是两个全连接层,在最后一层卷积结束后,又进行了一次池化操作,输出了20个12*12的图像(20指最后一层的厚度),然后通过了一个全连接层变成了1*100的向量(第一个全连接层神经元的个数是100)。
该操作其实就是用100个20*12*12(20指的是吃化层的厚度)的卷积核卷积出来的,对于输入的每一张特征图,都使用一个和图像大小一样的核卷积进行点积运算,这样整幅图就变成了一个数了,如果厚度是20就是那20个核卷积完了之后相加求和。这样就能把一张图高度浓缩成一个数了。
全连接的目的是什么呢?因为传统的端到到的卷积神经网络的输出都是分类(一般都是一个概率值),也就是几个类别的概率甚至就是一个数--类别号,那么全连接层就是高度提纯的特征了,方便交给最后的分类器或者回归。
但是全连接的参数实在是太多了,你想这张图里就有20*12*12*100个参数,前面随便一层卷积,假设卷积核是7*7的,厚度是64,那也才7*7*64,所以现在的趋势是尽量避免全连接,目前主流的一个方法是全局平均值。也就是最后那一层的feature map(最后一层卷积的输出结果),直接求平均值。有多少种分类就训练多少层,这十个数字就是对应的概率或者叫置信度。