今天学习了这两种算法,都是用来求最小路径的算法,但是迪杰斯特拉算法只能从某个特定点到所有点的最短路径,而佛洛依德算法可以查出任意点到任意点的最小路径。
迪杰斯特拉:
package dijkstra;
import java.util.Scanner;
import java.util.Stack;
/*
* 算法思路:通过从特定起点查找,一直查找到所有点到这个点的最小路径。
* 算法特点:因为要预防两点间的距离可能不是直接距离最短,所以处理要有些特别
* 算法处理思路:首先通过一个大的循环嵌套循环count(点)-1次,这么做是为了查找除了自身的所有点到起点的权值。
* 再通过一个for循环查找此时可达路径离起点最近的点。把查出来点的设为已查找过。
* 接下来再通过这个最短权值的点进行for循环操作,这个for循环作用是如果经过新增v顶点到达的定点比当前已知路径都短,我们更新
* 这个路径权值,并设置到这个点的前驱节点是v,让我们查询时能查出路径
*每个点都会走一次
* */
public class Dijkstra {
public static void main(String[] args) {
DijkstraArithmetic dijkstraArithmetic=new DijkstraArithmetic();
dijkstraArithmetic.dijkstra();
dijkstraArithmetic.find();
}
}
class DijkstraArithmetic{
//第一步:先准备一个图:
final int max = 65535;
int[][] graph = new int[][]{
{0, 1, 5, max, max, max, max, max, max},
{1, 0, 3, 7, 5, max, max, max, max},
{5, 3, 0, max, 1, 7, max, max, max},
{max, 7, max, 0, 2, max, 3, max, max},
{max, 5, 1, 2, 0, 3, 6, 9, max},
{max, max, 7, max, 3, 0, max, 5, max},
{max, max, max, 3, 6, max, 0, 2, 7},
{max, max, max, max, 9, 5, 2, 0, 4},
{max, max, max, max, max, max, 7, 4, 0}};
int[] D = new int[9]; //建立一个存储起点vo到各点的权值的数组
int[] P = new int[9];//建立一个起点到这个点的最短路径的前驱结点
int[] fin = new int[9];//建立一个确认每个点是否已经被算出最短路径,以便确认它不需要被再计算,被计算过就被记为1,为就按记为0
public void dijkstra() {
/**
* 算法第一步:初始化工作
*/
int i, j, k=0;
//初始化这三个数组,
for (i = 0; i < 9; i++) {
D[i] = graph[0][i];//初始化权值
P[i] = 0;//初始化前驱节点,试试自己的猜想(不行,如果这样的话,后面的!=0判断会出错误,而且能联通的都不为零)
fin[i] = 0;
}
fin[0] = 1;//不用计算起点
/*
* 第二步,通过现可达点查找最小的权值
* */
for (i = 1; i < 9; i++) {//遍历所有点的个数(除了v0)
int min = 65535;
for (j = 1; j < 9; j++) {//寻找v0最近的顶点
if (fin[j] != 1 && D[j] < min) {//确认要加入的点没有被加入过,并且某点可达且找出最小值
min = D[j];//把目前查到的最小值赋给min
k = j;//记录最小值的下标
}
}
fin[k] = 1;
for (j = 0; j < 9; j++) {//新更新了点,所以有了新的可达路径,更新这些新路径
if (fin[j] != 1 && D[j]>min +graph[k][j]){//更新那些和vo没链接但是和新的点有连接的点或者经过新的点有更近路径的点
D[j]=min+graph[k][j];//更新D[]数组的最小距离
P[j]=k;//设置修正权值的点的前驱结点
}
}
}
}
public void find(){//输出最近距离节点
int i;
System.out.println("请输入你想要到达的结点");
Scanner sc=new Scanner(System.in);
int pointnum=sc.nextInt();
i=pointnum;
// while(P[i]!=0){//循环输出每个点的前驱
// System.out.print(P[i]+"<-");
// i=P[i];
// }
// System.out.println("0");//输出最后一个是零点
//输出时存的是某个节点的前驱结点
//用栈输出
StackMySelf stackMySelf=new StackMySelf(15);
while(P[i]!=0){
System.out.println(P[i]);
stackMySelf.push(P[i]);//让每个元素入栈
i=P[i];
}
stackMySelf.push(0);//把起点放进去
while(!stackMySelf.empty()){
System.out.print(stackMySelf.pop());
if(!stackMySelf.empty()){
System.out.print("->");//最后一个点后面不会输出->
}
}
}
}
class StackMySelf {//自定义一个栈
private Object[] data =null;// 先自定义数组来当作栈的容器
private int maxSize;//定义栈的最大存储空间
private int top=-1;//定义栈的栈顶指针
StackMySelf(){ //构造函数来确定栈的大小,默认是10
this(10);
}
StackMySelf(int init) {//构造函数来确定栈的大小
if (init >= 0) {//如果栈的容量大于等于1
maxSize = init;//确定最大长度
data = new Object[init];//实例化数组
top = -1;//确认栈顶指针
} else {
throw new RuntimeException("初始化大小不能小于0" + init);
}
}
public boolean empty(){//判空
return top==-1?true:false;
}
public Object pop() {//出栈
if (top == -1) { //先判断栈不为空
throw new RuntimeException("栈为空");
} else {
return data[top--];
}
}
public boolean push(Object e){//入栈
if (top == maxSize - 1) {
throw new RuntimeException("栈已满");
} else {
data[++top]=e;//赋值
return true;
}
}
public Object peek(){//查看栈顶元素但不移除
if (top == maxSize - 1) {
throw new RuntimeException("栈已满");
} else {
return data[top];
}
}
public int search(Object e){//返回对象在堆栈中的位置,以1为基数
int i=top;//保留top的原本值
while(top!=-1){//循环一直找到栈底
if(peek()!=e){
top--;
}else {
break;
}
}
int result=top+1;//以1开始,所以加个1
top=i;//恢复top的值
return result;
}
}
我在这里记下学习这个算法时一些遇到的问题:
如:
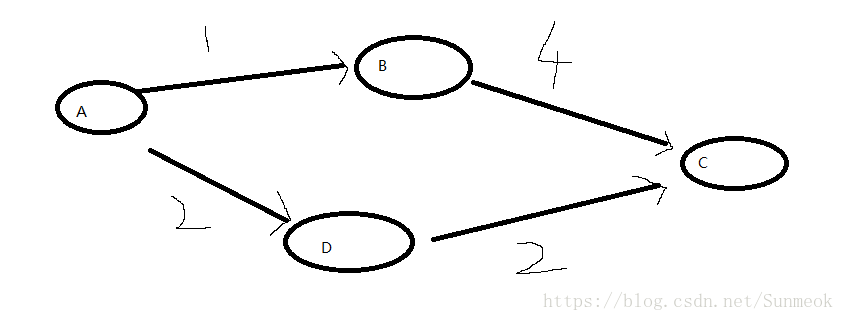
如果走到了B更新了B,然后修正到c的路径,可是a从d走才是最近的,这里想了很久,最后发现,他每次循环直走一个点,并设置一个点为走过路径,也就是说修正a到c的路径时,但是并没有把c加入走过路径,这时再通过D数组里的最小值会找到d,然后修正从d走a到c的路径。如果说a先到b直接到c这种情况只可能a到d的路径比a到b到c的路径大。
普里姆算法:
package Prim;
import com.sun.corba.se.impl.orbutil.graph.Graph;
import com.sun.org.apache.xerces.internal.util.SynchronizedSymbolTable;
public class Prim {
public static void main(String[] args){
int[][] graph=new int[][]{{0,6,1,5,65535,65535},
{6,0,5,65535,3,65535},
{1,5,0,5,6,4},
{5,0,5,0,65535,2},
{65535,3,6,65535,0,6},
{65535,65535,4,2,6,0}};
MinTree minTree=new MinTree();
minTree.createMinTree(graph);
}
}
class MinTree{
public void createMinTree(int[][] graph) {
int i, j,k=0 ,m;
int[] lowcost = new int[6];//建立一个存储已被包入当前生成树的所有可达路径的权值
int[] adjvex = new int[6];//用来记录可达路径权值的起始点,用于输出路径
//接下来初始化第一个点
lowcost[0] = 0;//我们要将所有访问过的节点包括设为0,以至于不会被访问到
adjvex[0] = 0;//我们设置第一个顶点为0节点
//将第一行的数据存入lowcost中
for (i = 0; i < 6; i++) {
lowcost[i] = graph[0][i];//初始化到所有点的权值,访问不到的是65535,以后会有新的点来更新这个数据
adjvex[i] = 0;//先设置所有点都是从vo发出的
}
/**
* 先选出当前可达点的权值最小的点,并加入生成树
* **/
for (i = 1; i < 6; i++) {//需要连接几个点就遍历几次
int min = 65535;//定义在这里防止min拿到了最小值,之后min无法改变
for (j = 1; j < 6; j++) {//遍历所有lowcost找到现在最小的权值
if (lowcost[j] != 0 && lowcost[j] < min) {
min = lowcost[j];//将最小权值点赋给lowcost,循环结束得到最小的
k=j;//将最小权值点的下标值存入k
}
}
System.out.println(adjvex[k]+"-"+k);//输出边
lowcost[k]=0;//将这个点包入生成树
/**
* 下面的步骤:
* 作用:因为加入了新的节点,所以更新到各个点的最小权值
**/
for (m=1;m<6;m++){//将新加入生成树的点的连接点的权值全部更新至lowcost
if(graph[k][m]!=0&&graph[k][m]<lowcost[m]){//查看这个新加入点的权值是否有小于lowcost存在的权值并存入
lowcost[m]=graph[k][m];//赋值
adjvex[m]=k;
}
}
}
}
}