本篇博客主要介绍在PyTorch框架下,基于LSTM实现手写数字的识别。
在介绍LSTM长短时记忆网路之前,我先介绍一下RNN(recurrent neural network)循环神经网络.
RNN是一种用来处理序列数据的神经网络,序列数据包括我们说话的语音、一段文字等等。它的出现是为了让网络自己有记忆能力,每个网络模块把信息传给下一个模块,它的网络结构如下:
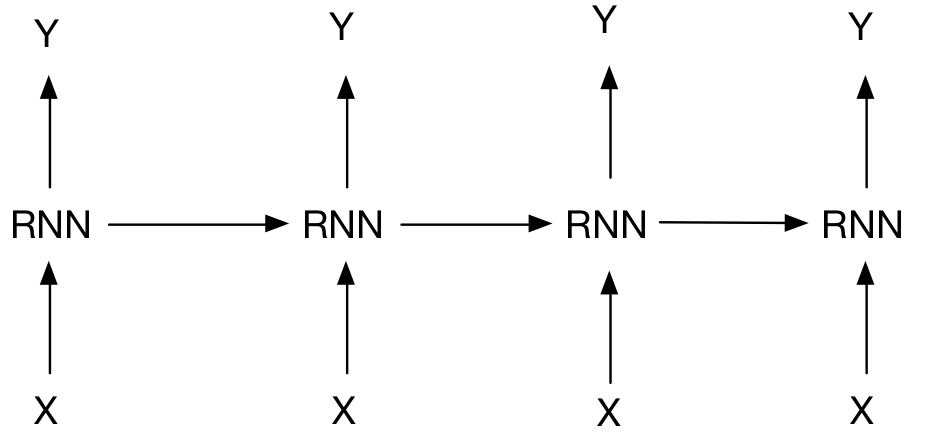
对于输入的一段序列数据(X1,X2,X3,X4……)给出预测的结果(Y1,Y2,Y3,Y4……),如果是一个文本情感分类问题,那么将前几个Y值抹去,剩下最后一个Y,即是一段文字的预测的情感分类结果。
当进行梯度下降法更新参数时,RNN会出现梯度消失或者梯度下降的问题。当每层的权值W小于1,那么误差传到最开始,结果接近于0,梯度消失;当每层的权值W大于1,那么误差传到第一层,结果会变得无穷大,梯度爆炸。
为了避免这个问题,我们引出了LSTM长短时记忆网络,该网络主要用来延缓记忆衰退。
LSTM的网络结构如下:
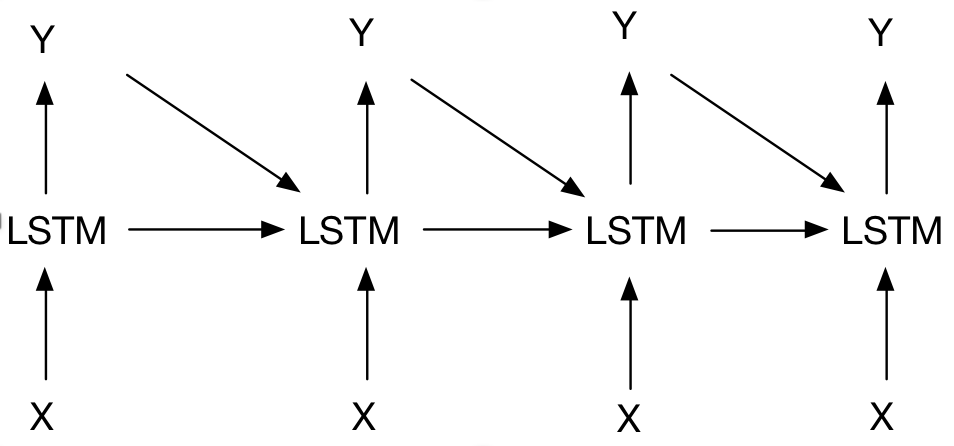
它将前一个时刻的输出Y也传给了下一个时刻,并且中间单元加了一个判断信息是否有用的功能,这样的话,就可以将让网络自己选择要记忆有用的信息,遗忘无用的信息。主要通过三个门来实现---输入门、遗忘门和输出门。
在识别MNIST手写数字时,我们可以把28*28像素的一幅图片,按行输入,每一行对应一个时刻,这样有28个X输入,有1个Y输出,将每行的像素值类比成一个序列数据。
以下代码测试了在测试数据的准确率,以及取前10个测试数据的结果。
import torch
from torch import nn
from torch.autograd import Variable
import torchvision.datasets as dsets
import torch.utils.data as Data
import matplotlib.pyplot as plt
import torchvision
torch.manual_seed(1)
EPOCH = 1
BATCH_SIZE = 64
TIME_STEP = 28
INPUT_SIZE = 28
LR = 0.01
DOWNLOAD_MNIST = False
train_data = dsets.MNIST(
root = './mnist',
train = True,
transform = torchvision.transforms.ToTensor(),
download = DOWNLOAD_MNIST,
)
test_data = torchvision.datasets.MNIST(root='./mnist',train=False)
train_loader = Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)
test_x = Variable(torch.unsqueeze(test_data.test_data,dim=1),volatile=True).type(torch.FloatTensor)/255
test_y = test_data.test_labels
class RNN(nn.Module):
def __init__(self):
super(RNN,self).__init__()
self.rnn = nn.LSTM(
input_size=28,
hidden_size=64,
num_layers=1,
batch_first=True,
)
self.out = nn.Linear(64,10)
def forward(self,x):
r_out, (h_n, h_c) = self.rnn(x, None)
out = self.out(r_out[:,-1,:])
return out
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(),lr=LR)
loss_func = nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step,(x,y) in enumerate(train_loader):
b_x = Variable(x.view(-1,28,28))
b_y = Variable(y)
output = rnn(b_x)
loss = loss_func(output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step%50 == 0:
test_output = rnn(test_x.view(-1,28,28))
pred_y = torch.max(test_output,1)[1].data.numpy().squeeze()
accuracy = sum(pred_y == test_y)/float(test_y.size(0))
print('Epoch: ',epoch, '| train loss:%.4f' %loss.data[0],'| test accuracy:%.2f' %accuracy)
test_output = rnn(test_x[:10].view(-1,28,28))
pred_y = torch.max(test_output,1)[1].data.numpy().squeeze()
print(pred_y,'prediction number')
print(test_y[:10].numpy(),'real number')
运行结果:
