因为循环神经网络很难训练的原因,这导致了它在实际应用中,很难处理长距离的依赖。我们将介绍一种改进之后的循环神经网络:长短时记忆网络(Long Short Term Memory Network, LSTM),它成功的解决了原始循环神经网络的缺陷,成为当前最流行的RNN,在语音识别、图片描述、自然语言处理等许多领域中成功应用。但不幸的一面是,LSTM的结构很复杂,因此,我们再介绍一种LSTM的变体:GRU (Gated Recurrent Unit)。 它的结构比LSTM简单,而效果却和LSTM一样好,因此,它正在逐渐流行起来。
原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?如下图所示:
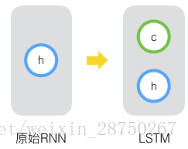
新增加的状态c,称为单元状态(cell state)。我们把上图按照时间维度展开:
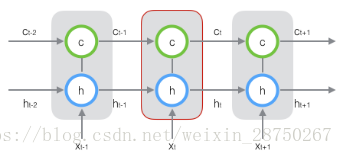
上图仅仅是一个示意图,我们可以看出,在t时刻,LSTM的输入有三个:当前时刻网络的输入值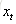

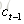

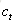
LSTM的关键,就是怎样控制长期状态
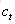
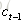
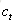
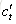
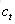
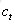
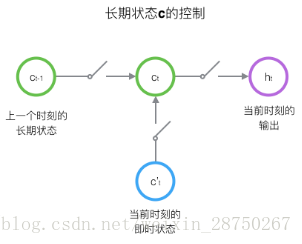
接下来,我们要描述一下,输出
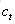
LSTM前向计算:
门的概念:假设W是该门的权重向量,b是偏置项,则: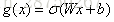
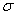

遗忘门:它决定了上一时刻的单元状态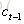
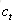
输入门:它决定了针对当前输入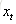
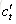

输出门:控制单元状态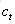

这几个门与上述的开关相配合来计算当前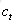

如上图所示:这三个门: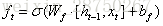

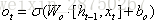
输入都为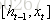
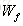
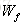
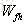
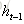
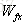
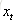
针对于当前输入的单元状态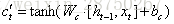
则所求的: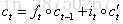

LSTM训练算法:
LSTM的训练算法仍然是反向传播算法,对于这个算法,我们已经非常熟悉了。主要有下面三个步骤:
1.前向计算每个神经元的输出值,对于LSTM来说,即
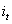
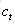


2.反向计算每个神经元的误差项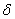
3.根据相应的误差项,计算每个权重的梯度。
误差项沿时间的反向传递:
在t时刻,LSTM的输出值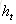

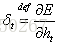

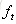
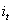

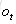

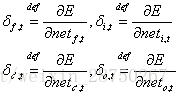
推导过程参见博客,最后得到公式:

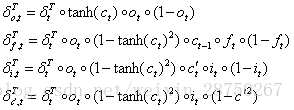
那么我们就得到误差项向前传递到任意时刻k的公式:
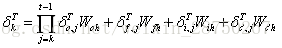
将误差传递到上一层:
我们假设当前为第l层,定义l-1层的误差项是误差函数对l-1层加权输入的导数,即:
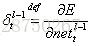

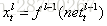
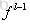
推导过程不再多说,得到: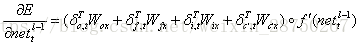
权重梯度计算:
对于
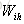
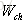
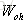

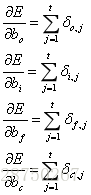
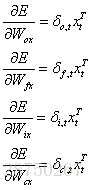
以上就是LSTM训练算法全部公式。