大家好,今天和各位分享一下长短时记忆网络 LSTM 的原理,并使用 Pytorch 从公式上实现 LSTM 层
上一节介绍了循环神经网络 RNN,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/article/details/125424902
我的这个专栏中有许多 LSTM 的实战案例,便于大家巩固知识:https://blog.csdn.net/dgvv4/category_11712004.html
1. 引言
循环神经网络的记忆功能在处理时间序列问题上存在很大优势,但随着训练的不断进行,RNN 网络一直在不断的扩充记忆,致使 RNN 产生梯度消失以及梯度爆炸。
为了解决RNN难以有效训练的问题,拥有选择记忆功能的 LSTM模型被提出。LSTM 是在 RNN 的基础上进行的改进,其既能学习数据中的长期依赖,又能解决梯度消失。LSTM 包含一个记忆单元和三个门结构,其中门结构分别是输入门、输出门和遗忘门。
LSTM 的工作过程如下:
首先由输入数据 X_t 与前一时刻隐藏层的输出数据 h_t-1 共同作用于遗忘门,遗忘门对上述信息进行筛选,记忆时间序列中的重要特征信息,丢弃无关紧要的信息;然后将输入数据 x_t 以及前一时刻隐藏层的输出数据 h_t-1 作为输入门的输入信息,进行更新;其次记忆单元通过输入数据 X_t、前一时刻隐藏层的输出数据 h_t-1 以及前一时刻的记忆单元状态 C_t-1 对自身状态进行更新;最后将输入数据 X_t、前一时刻隐藏层的输出数据 h_t-1 以及当前时刻的记忆单元状态 C_t 共同作用于输出门,输出当前时刻的隐藏层信息 h_t。
LSTM 的结构图如下:

2. 原理解析
2.1 遗忘门
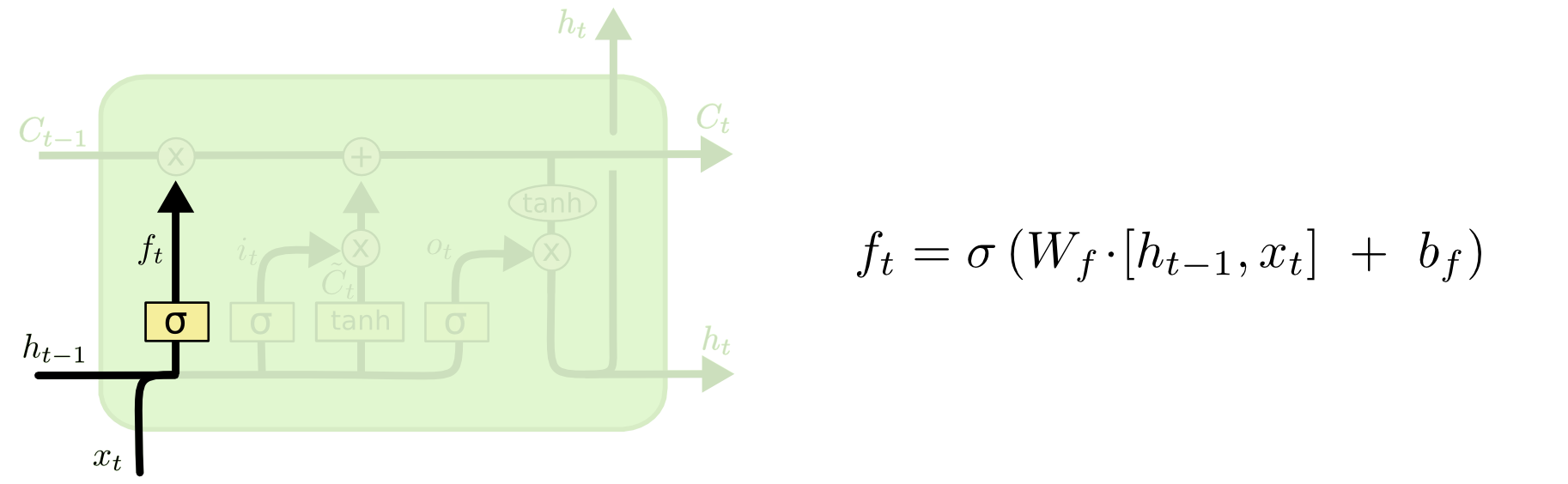
将上一时刻的输出 h_t-1 与当前时刻的输入 X_t 结合,并通过 Sigmoid 函数计算得到一个阈值为 [0,1] 的张量 f_t,该 f_t 可以看作是对上一时刻的状态 C_t-1 的权重项,f_t 负责控制上一时刻状态需要被遗忘的程度。
计算公式:
将公式展开,其中 W_if 是对当前时刻输入的特征提取,W_hf 是对前一时刻状态的特征提取,@ 代表矩阵相乘。
2.2 输入门
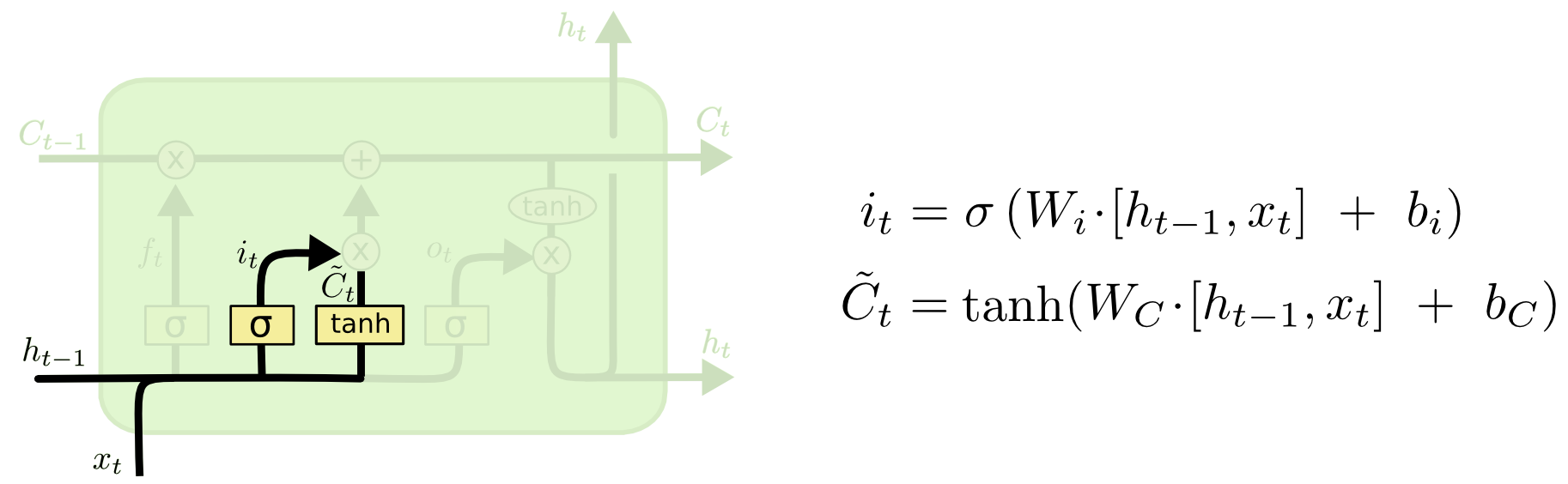
输入门是与 tanh 函数配合控制新信息加入的程度。在这个过程中,tanh 函数会给出一个新的候选向量 ,输入门为
中的每一项产生一个在 [0,1] 之间的值 i_t,控制新信息被加入的多少。
计算公式:
公式展开,其中 W_i 是对当前时刻输入的特征提取,W_h 是对前一时刻状态的特征提取,@ 代表矩阵相乘。
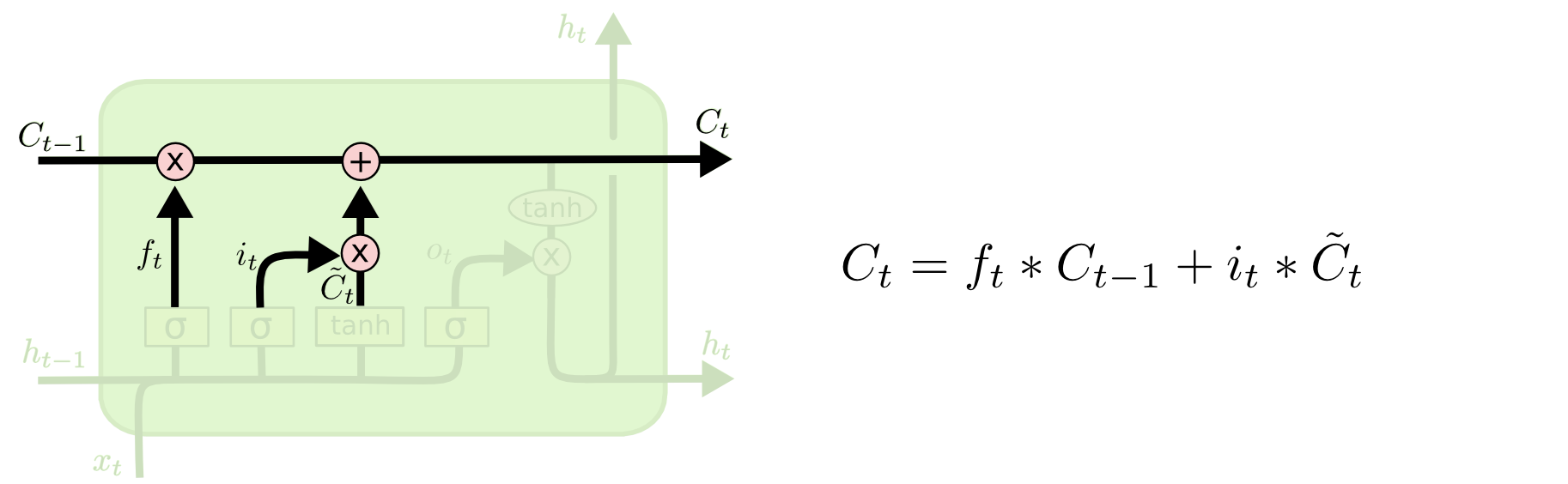
至此,模型已经计算了遗忘门的输出 f_t,和输入门的输出 i_t,分别用来控制上一时刻的状态需要被遗忘的程度,和新增信息的规模,接下来可以根据这两个输出更新当前时刻的状态 C_t。
计算公式,其中 * 代表张量之间逐元素相乘。
2.3 输出门
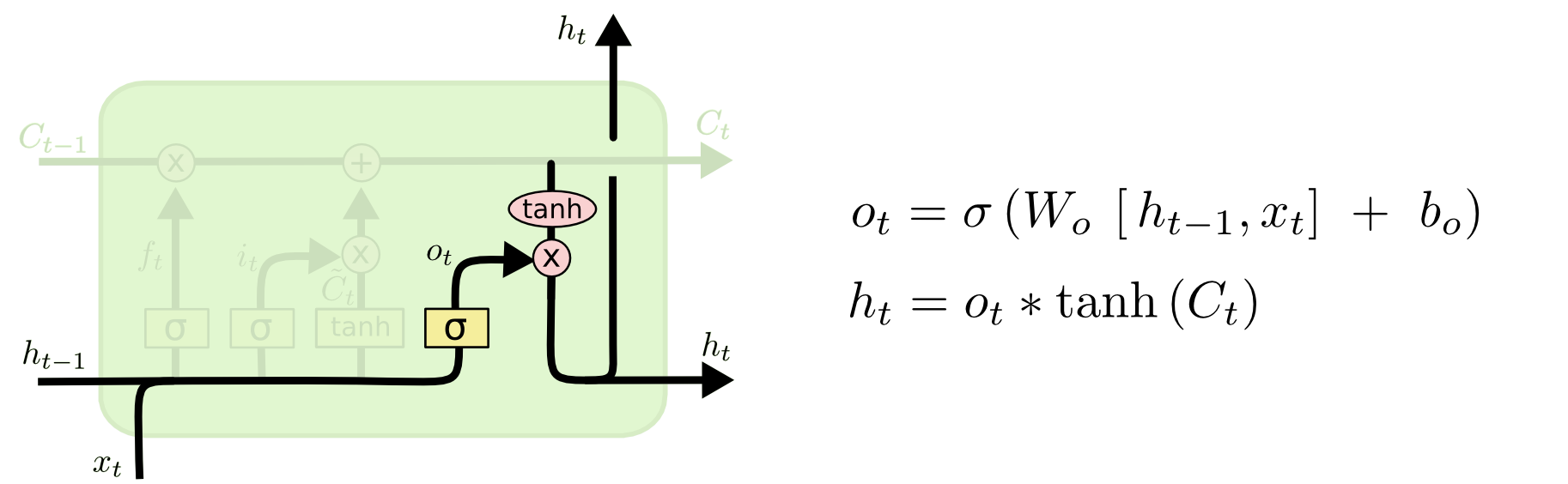
输出门用来过滤当前状态的某些信息,将其舍去。输出门的计算过程,将输入数据 X_t、前一时刻隐藏层的输出数据 h_t-1 经过 sigmoid 函数,把每一项的值压缩到 [0-1] 之间,作为过滤信息的权重项。然后与更新后的当前状态 C_t 逐元素相乘,
计算公式:
公式展开:
3. 代码实现
3.1 官方 API
torch.nn.LSTM() 参数如下:
lstm = nn.LSTM(input_size, hidden_size, num_layers, bias=True, batch_first=False)
'''
input_size: 每个单词使用多少长的向量来表示
hidden_size: 隐含层,经过LSTM层后每个单词用多长的向量来表示
num_layers: LSTM的层数
bias: 是否使用偏置项,默认为True,即 w@x+b
batch_first: 对于输入是否将batch放在axis=0的位置,默认False,即[seq_len, batch, feature_len]
'''实例化单层 LSTM,做一次前向传播,查看输出信息
import torch
from torch import nn
# 定义参数
batch = 3 # 现在有3个句子
seq_len = 10 # 每个句子有10个单词
feature_len = 100 # 每个单词用长度为100的向量来表示
hidden_len = 20 # 经过LSTM层后每个单词用长度为20的向量来表示
# 当前时刻的输入 [batch, seq_len, feature_len]
inputs = torch.randn(batch, seq_len, feature_len)
# 上一时刻的状态 [batch, hidden_len]
h0 = torch.randn(batch, hidden_len)
c0 = torch.randn(batch, hidden_len)
# 实例化LSTM层
lstm = nn.LSTM(input_size=feature_len, hidden_size=hidden_len,
num_layers=1, batch_first=True)
# c:最后一个单词更新的状态,[num_layer, batch, hidden_size]
# h:最后一个单词的输出,[num_layer, batch, hidden_size]
# out: 整体输出结果,[batch, seq_len, hidden_size]
out, (h,c) = lstm(inputs)
print('out:', out.shape, # [3, 10, 20]
'h:', h.shape, # [1, 3, 20]
'c:', c.shape) # [1, 3, 20]
# 查看权重信息
for k,v in lstm.named_parameters():
print(k, v.shape)
'''
weight_ih_l0 torch.Size([80, 100])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
'''3.2 自定义函数
接下来根据第二小节解释过的公式,从原理上实现一个 LSTM 层,主要就是6个公式的计算,还要注意张量的shape变化。
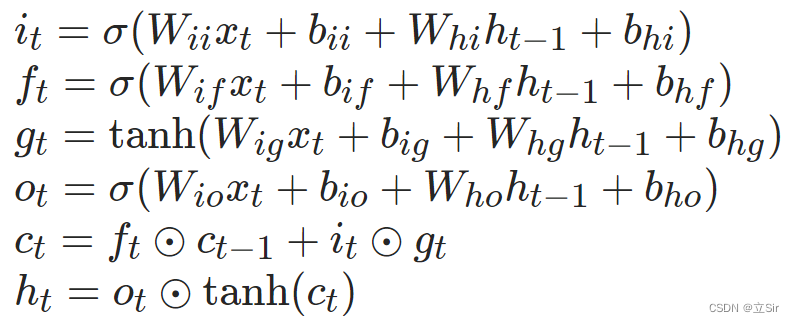
代码实现如下:
import torch
from torch import nn
'''
inputs: 当前时刻的输入 [batch, seq_len, feature_len]
c0: 上一时刻的状态,[batch, hidden_len]
h0: 上一时刻的输出,[batch, hidden_len]
w_ih, b_ih: 对当前时刻输入的特征矩阵和偏置
w_hh, b_hh: 对上一时刻状态的特征矩阵和偏置
w_ih.shape=[4*hdiien_size, feature_len]
w_hh.shape=[4*hdiien_size, hidden_len]
b.shape=[4*hidden_size]
'''
# ------------------------------------------------------------- #
#(1)自定义LSTM模型
# ------------------------------------------------------------- #
def lstm_forward(inputs, initial_states, w_ih, w_hh, b_ih, b_hh):
h0, c0 = initial_states # 获取初始状态
# batch代表序列个数,seq_len代表每个序列有多少个样本,feature_len代表每个样本有多少个特征
batch, seq_len, feature_len = inputs.shape # 获取输入的形状
# 获取隐含层个数,根据公式由4个W拼接而成
hidden_len = w_ih.shape[0] // 4 # weight_ih_l0 torch.Size([80, 100])
# 初始化输出层 [batch, seq_len, hidden_len]
outputs = torch.zeros(batch, seq_len, hidden_len)
# 在LSTM中不断更新上一时刻的状态
pre_h, pre_c = h0, c0
# 扩充w的维度==>[b, 4*hdiien_size, feature_len]
batch_w_ih = w_ih.unsqueeze(0).tile(batch, 1, 1)
# ==>[b, 4*hdiien_size, hidden_len]
batch_w_hh = w_hh.unsqueeze(0).tile(batch, 1, 1)
# 遍历每个序列中的每个单词
for t in range(seq_len):
# 获取当前时刻的输入张量
x = inputs[:, t, :] # [b, feature_len]
# 三维矩阵相乘 [b, 4*hdiien_size, feature_len] @ [b, feature_len, 1]
w_time_x = torch.bmm(batch_w_ih, x.unsqueeze(-1)) # [b, 4*hidden_len, 1]
w_time_x = w_time_x.squeeze(-1) # [b, 4*hidden_len]
# 状态的矩阵相乘 [b, 4*hdiien_size, hidden_len] @ [b, hidden_len, 1]
w_time_h_pre = torch.bmm(batch_w_hh, pre_h.unsqueeze(-1)) # [b, 4*hidden_size, 1]
w_time_h_pre = w_time_h_pre.squeeze(-1) # [b, 4*hidden_size]
# 取前1/4用作输入门(i)
i_t = w_time_x[:, :hidden_len] + b_ih[:hidden_len] + w_time_h_pre[:, :hidden_len] + b_hh[:hidden_len]
i_t = torch.sigmoid(i_t)
# 遗忘门(f)
f_t = w_time_x[:, hidden_len:hidden_len*2] + b_ih[hidden_len:hidden_len*2] + w_time_h_pre[:, hidden_len:hidden_len*2] + b_hh[hidden_len:hidden_len*2]
f_t = torch.sigmoid(f_t)
# 细胞门(g)
g_t = w_time_x[:, hidden_len*2:hidden_len*3] + b_ih[hidden_len*2:hidden_len*3] + w_time_h_pre[:, hidden_len*2:hidden_len*3] + b_hh[hidden_len*2:hidden_len*3]
g_t = torch.tanh(g_t)
# 输出门(o)
o_t = w_time_x[:, hidden_len*3:] + b_ih[hidden_len*3:] + w_time_h_pre[:, hidden_len*3:] + b_hh[hidden_len*3:]
o_t = torch.tanh(o_t)
# 状态(c)
pre_c = f_t * pre_c + i_t * g_t
# 当前时刻lstm的输出(h)
pre_h = o_t * torch.tanh(pre_c)
# 更新输出层
outputs[:, t, :] = pre_h
# 返回输出、最后一个时刻的输出h,状态c
return outputs, (pre_h, pre_c)
# ------------------------------------------------------------- #
#(2)前向传播
# ------------------------------------------------------------- #
batch = 3 # 3个句子
seq_len = 10 # 序列长度,每个句子有10个单词
feature_len = 100 # 特征个数,一个单词用长度为100的向量来表示
hidden_len = 20 # 隐含层,经过LSTM层后用长度为20的向量来表示
# 构造输入层 [batch, seq_len, feature_len]
inputs = torch.randn(batch, seq_len, feature_len)
# 初始状态,不需要训练 [batch, hidden_len]
h0 = torch.randn(batch, hidden_len)
c0 = torch.randn(batch, hidden_len)
# 构造权重
w_ih = torch.randn(hidden_len*4, feature_len) # [80, 100]
w_hh = torch.randn(hidden_len*4, hidden_len) # [80, 100]
# 构造偏执
b_ih = torch.randn(hidden_len*4) # [80]
b_hh = torch.randn(hidden_len*4) # [80]
# lstm层计算结果
outputs, (final_h, final_c) = lstm_forward(inputs, (h0, c0), w_ih, w_hh, b_ih, b_hh)
'''
outputs: 所有句子的输出,[batch,seq_len, hidden_len]
pre_h: 最后一次个单词的输出,[batch, hidden_len]
pre_c: 最后一个单词的状态,[batch, hidden_len]
'''
print('outputs.shape:', outputs.shape, # [3, 10, 20]
'pre_h.shape:', final_h.shape, # [3, 20]
'pre_c.shape:', final_c.shape) # [3, 20]