版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sxlsxl119/article/details/82456075
此篇文章是按我自己学习后的理解,RNN和LSTM概念啥的就不说了,主要将相关图文整理了一下。看起来可能不太连贯,主要作为一个概要笔记。
一,RNN
RNN结构示意图
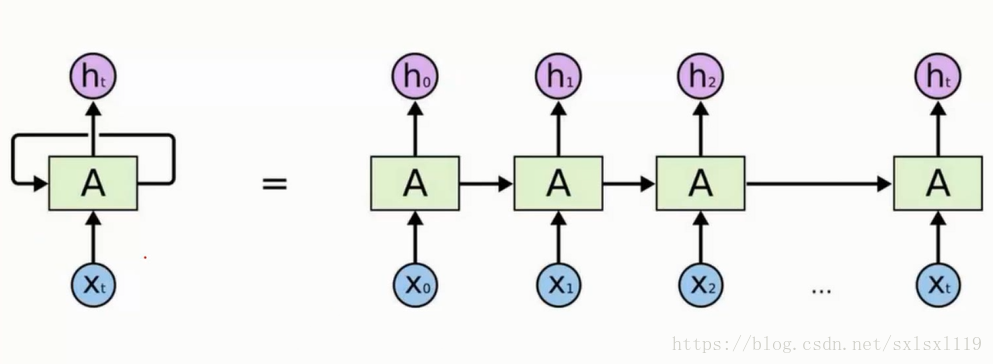
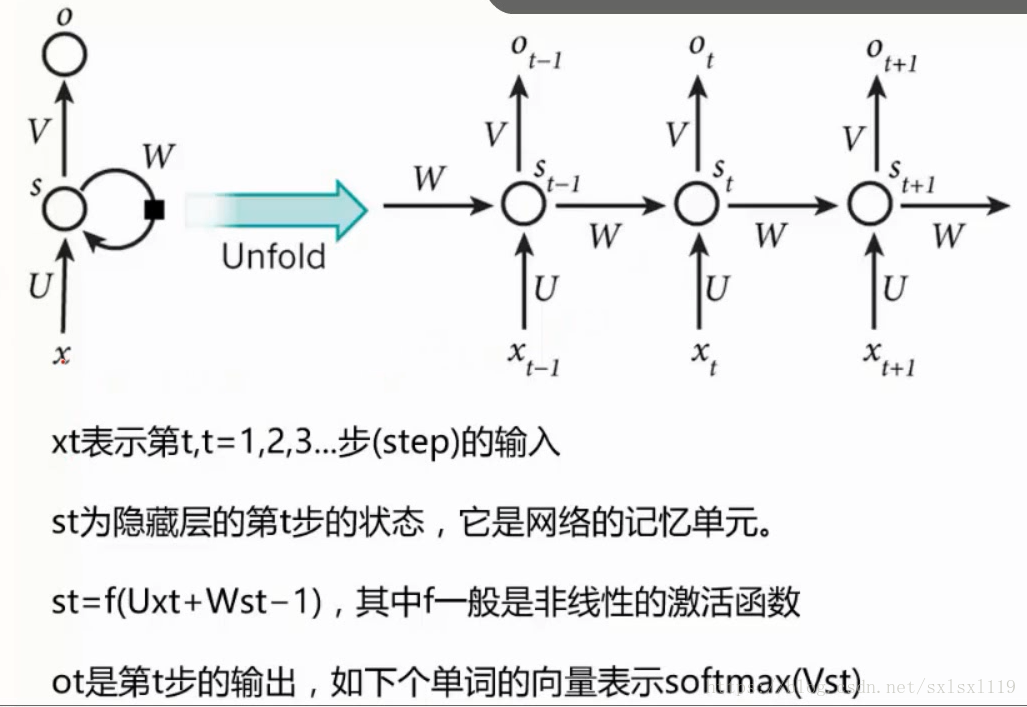
RNN数据传输描述图
RNN与LSTM的cell单元结构比较
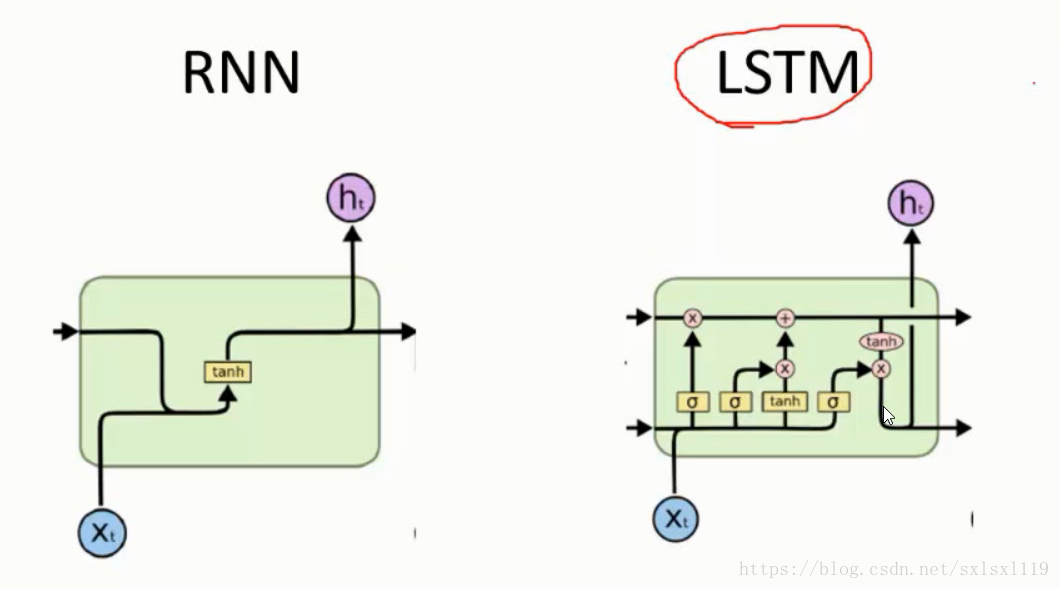
二,LSTM
LSTM整体结构图
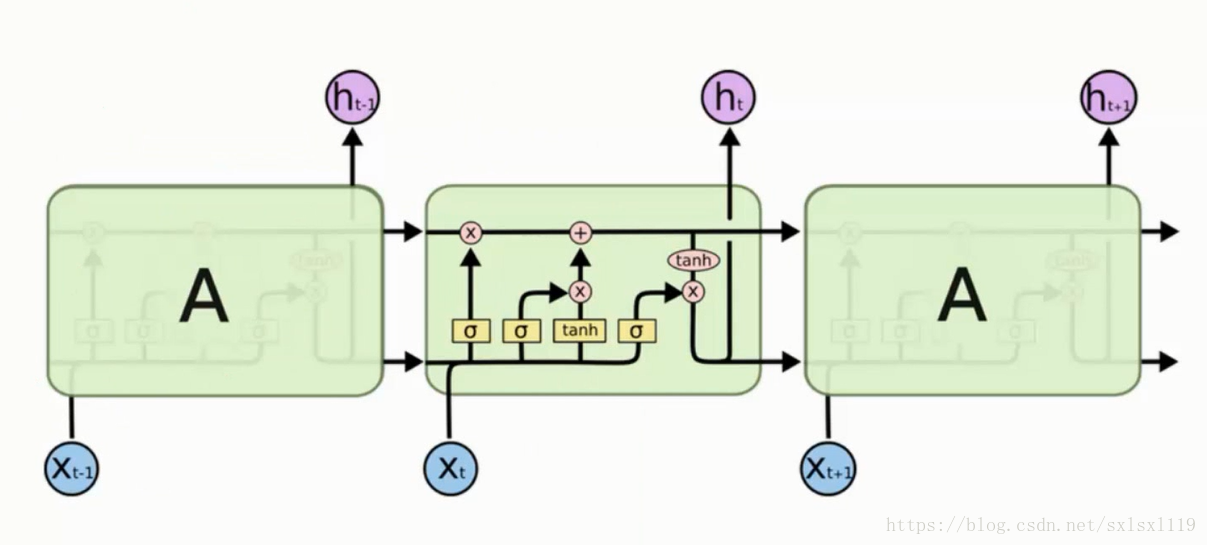
控制参数,控制什么样的信息被保留,什么样的信息会被遗忘。
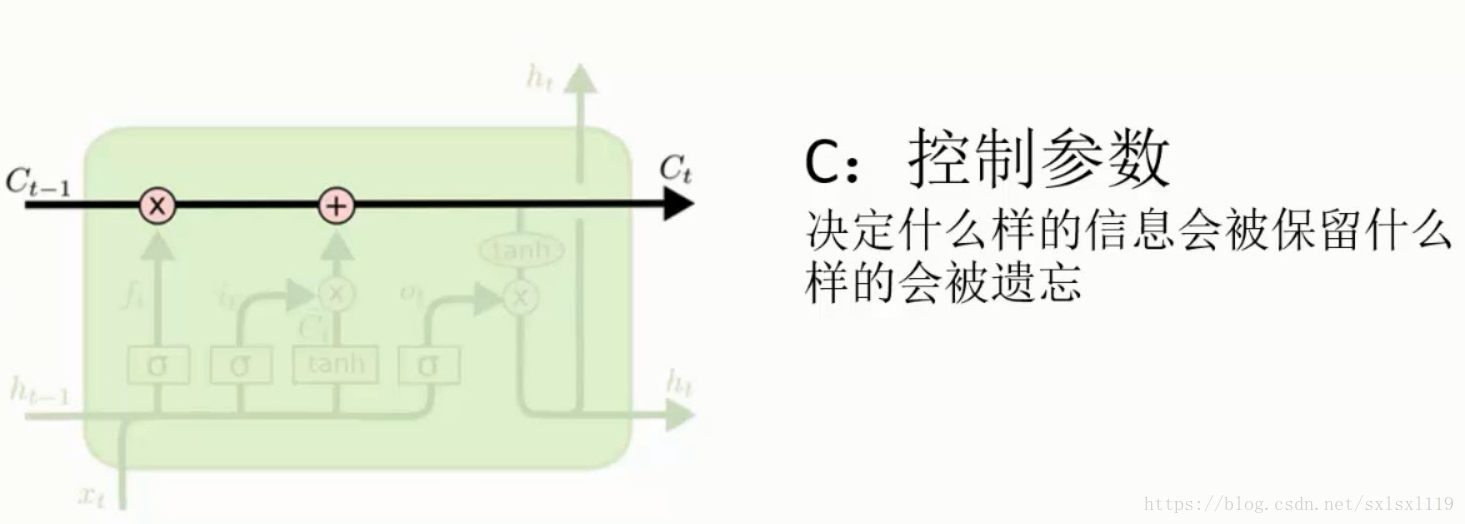
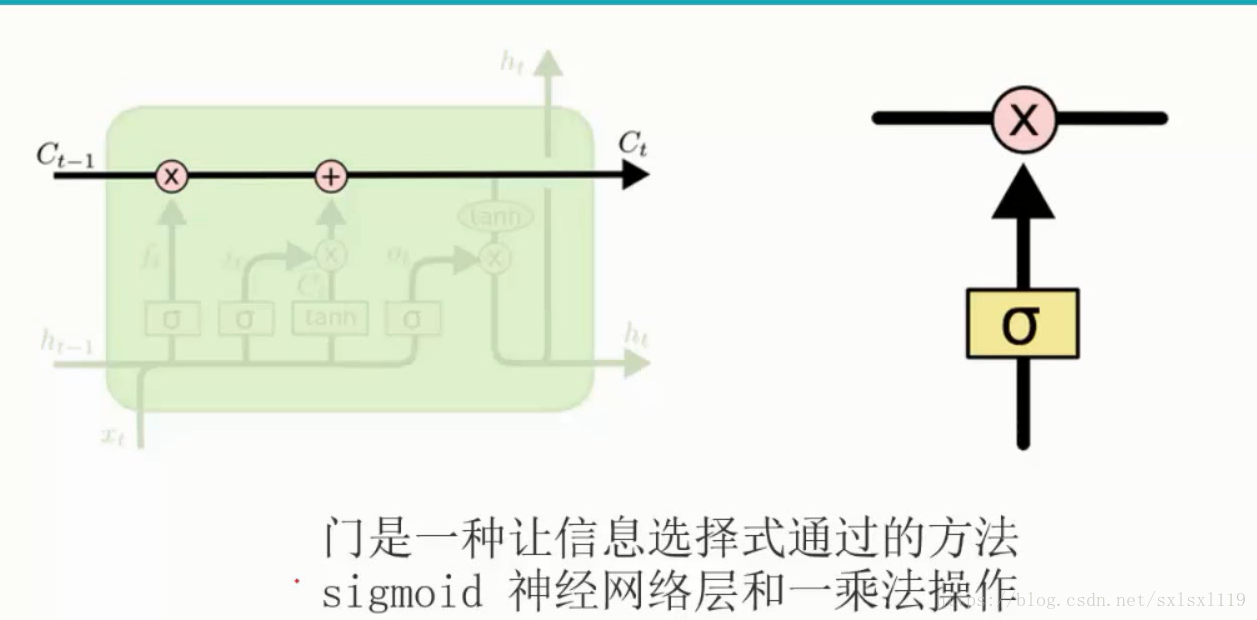
门单元,主要作用是让网络对信息进行选择
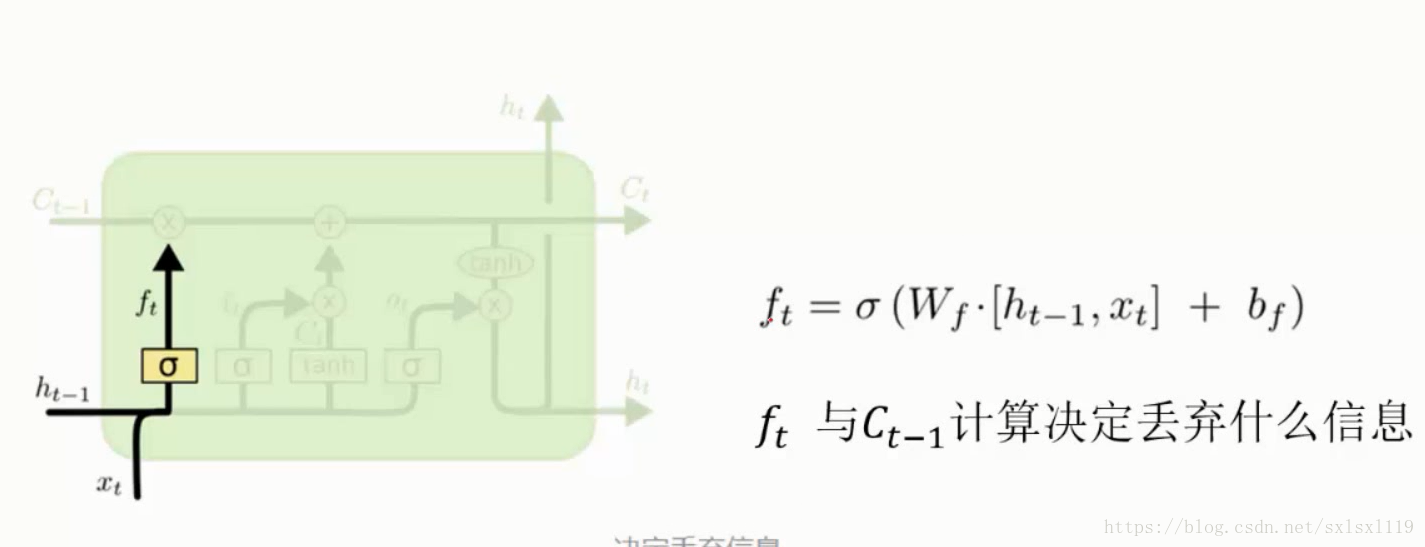
遗忘门
记忆门
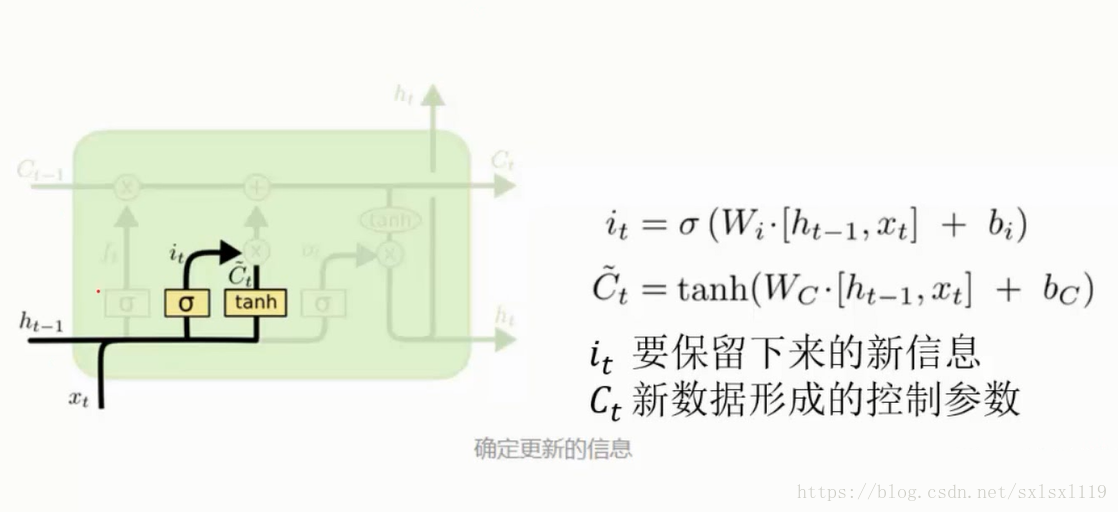
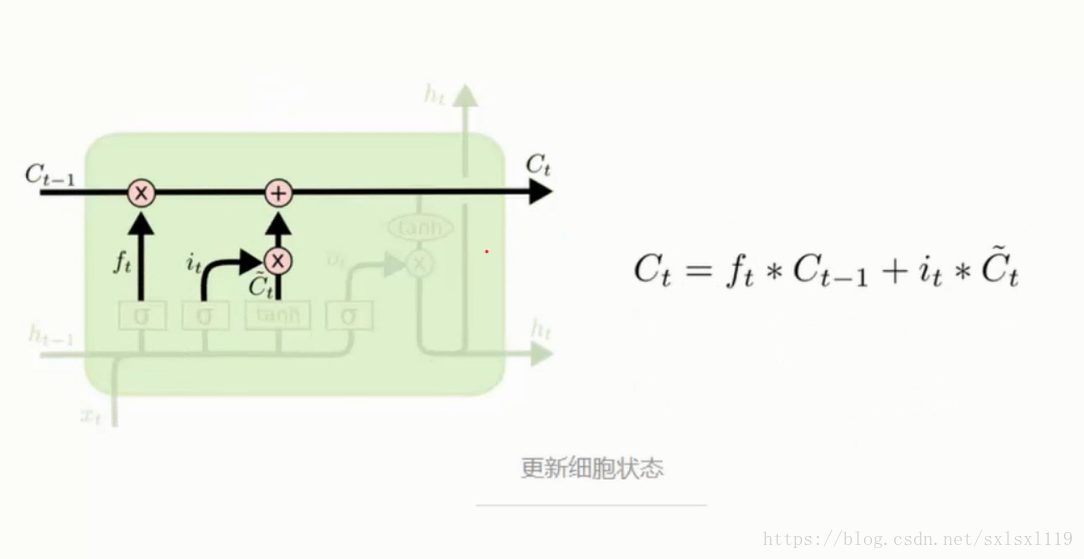
更新细胞状态
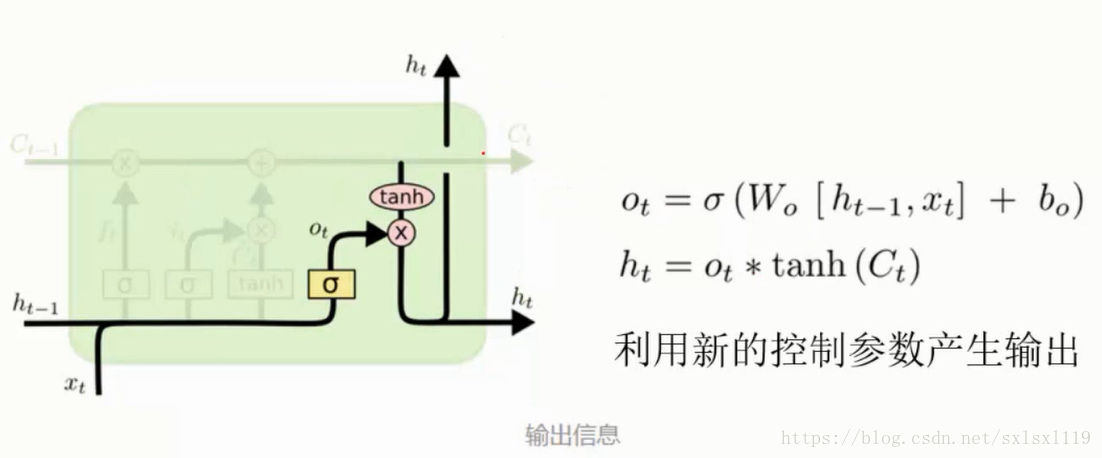
输出门
三,LSTM实现手写字体识别
这里没有文字描述,主要是为了看图,理理LSTM数据传入的过程,加深理解。
图片来源“xxxx-RNN与LSTM网络原理进行唐诗生成视频课程 5”(出现第三方名称就发布不了了)
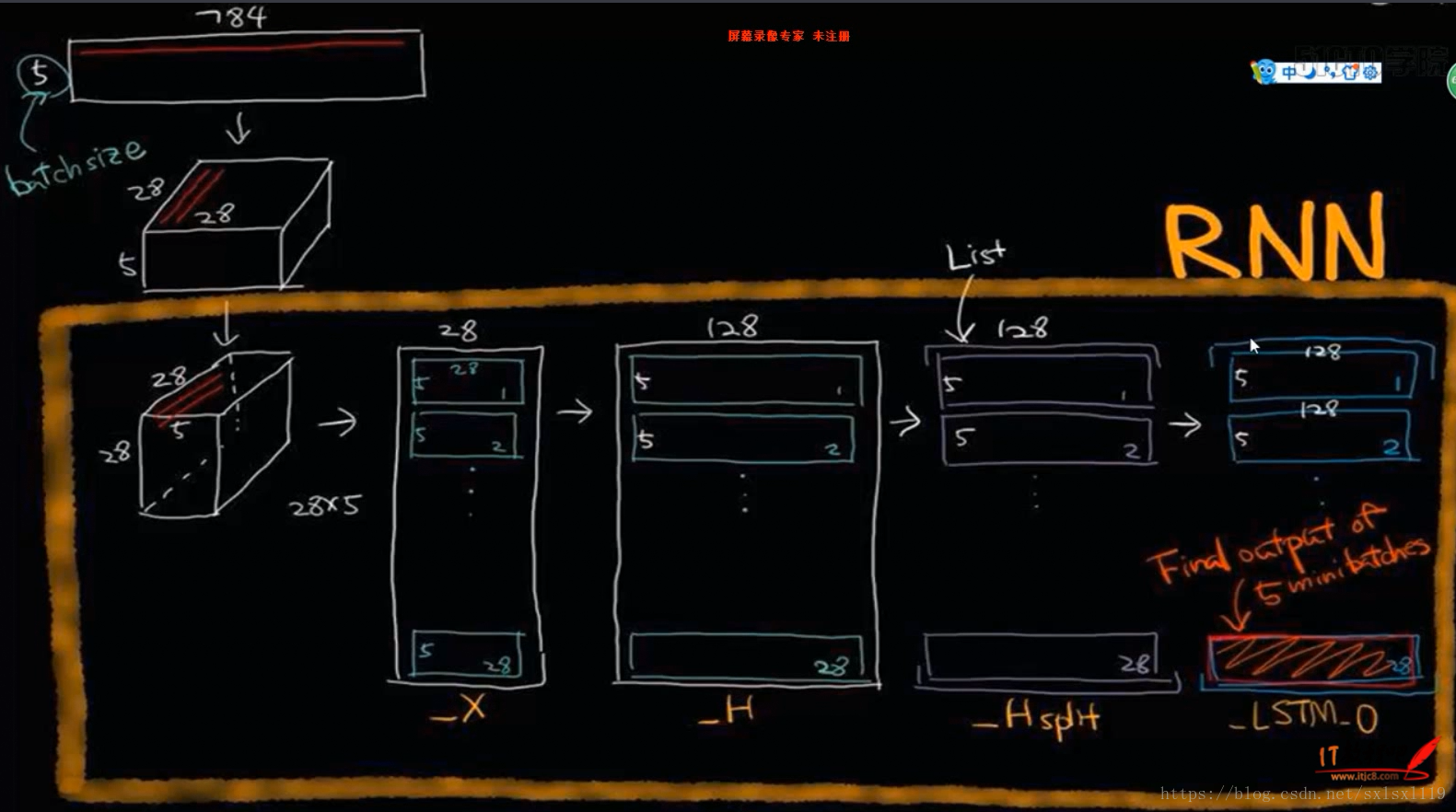
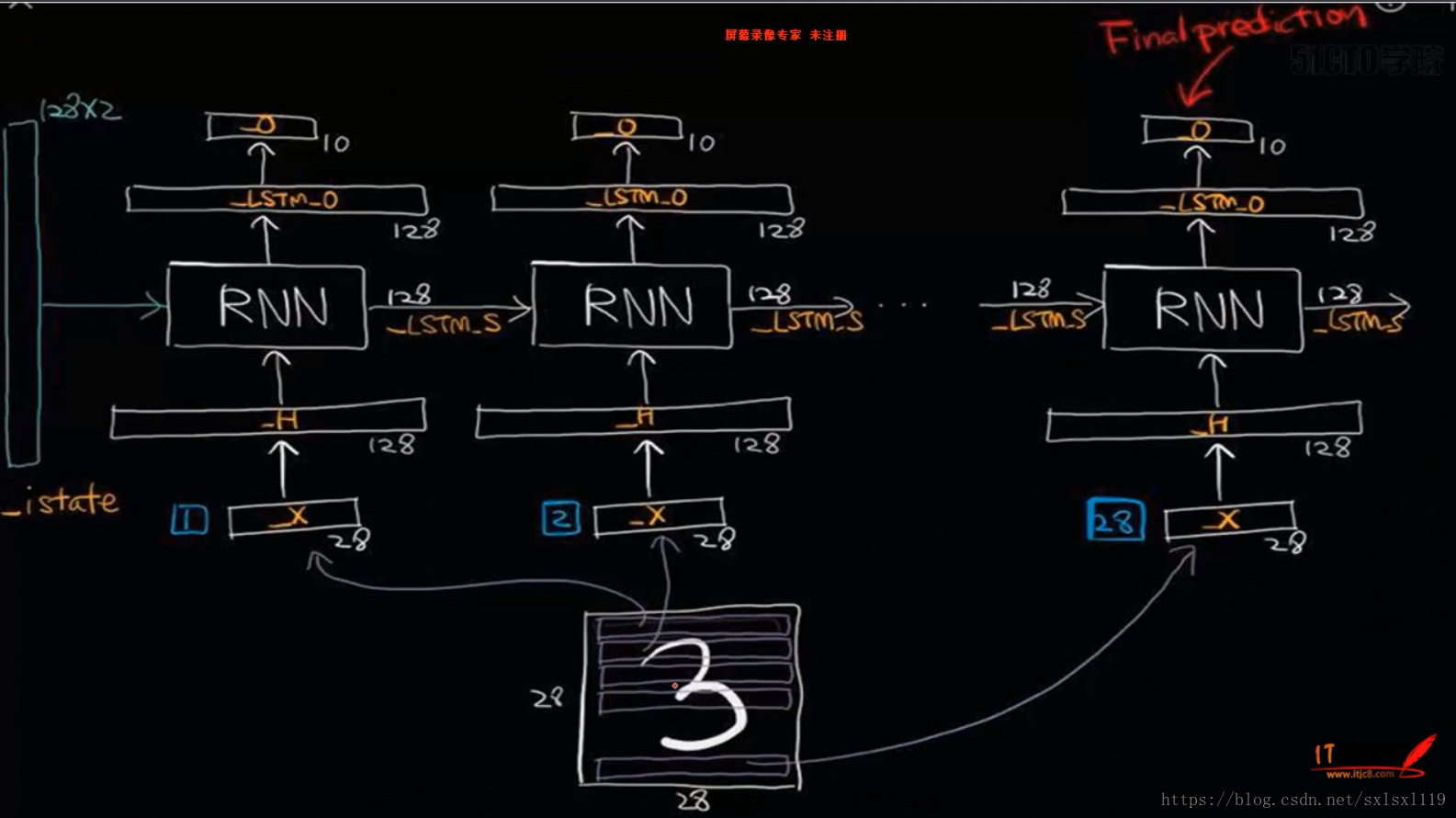
四,源代码
下面是用LSTM实现手写字体识别的源代码(参考网络的代码,进行了些许修改)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# set random seed for comparing the two result calculations
tf.set_random_seed(1)
# this is data
mnist = input_data.read_data_sets("E:\sxl_Programs\Python\MNIST_data\MNIST_data", one_hot=True)
# hyperparameters 超参数
lr = 0.001 #学习率
training_iters = 10000 #训练轮数
batch_size = 200
n_inputs = 28 # MNIST data input (img shape: 28*28)
n_steps = 28 # time steps
n_hidden_units = 128 # neurons in hidden layer
n_classes = 10 # MNIST classes (0-9 digits)
# tf Graph input
x = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_classes])
# Define weights
weights = {
# (28, 128)
'in': tf.Variable(tf.random_normal([n_inputs, n_hidden_units])),
# (128, 10)
'out': tf.Variable(tf.random_normal([n_hidden_units, n_classes]))
}
biases = {
# (128, )
'in': tf.Variable(tf.constant(0.1, shape=[n_hidden_units, ])),
# (10, )
'out': tf.Variable(tf.constant(0.1, shape=[n_classes, ]))
}
def RNN(X, weights, biases):
# hidden layer for input to cell
########################################
# transpose the inputs shape from
# X ==> (128 batch * 28 steps, 28 inputs)
X = tf.reshape(X, [-1, n_inputs])
# into hidden
# X_in = (128 batch * 28 steps, 128 hidden)
X_in = tf.matmul(X, weights['in']) + biases['in']
# X_in ==> (128 batch, 28 steps, 128 hidden)
X_in = tf.reshape(X_in, [-1, n_steps, n_hidden_units])
# cell
##########################################
# basic LSTM Cell.
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True)
else:
cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units)
# lstm cell is divided into two parts (c_state, h_state)
init_state = cell.zero_state(batch_size, dtype=tf.float32)
# You have 2 options for following step.
# 1: tf.nn.rnn(cell, inputs);
# 2: tf.nn.dynamic_rnn(cell, inputs).
# If use option 1, you have to modified the shape of X_in, go and check out this:
# https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/recurrent_network.py
# In here, we go for option 2.
# dynamic_rnn receive Tensor (batch, steps, inputs) or (steps, batch, inputs) as X_in.
# Make sure the time_major is changed accordingly.
outputs, final_state = tf.nn.dynamic_rnn(cell, X_in, initial_state=init_state, time_major=False)
# hidden layer for output as the final results
#############################################
# results = tf.matmul(final_state[1], weights['out']) + biases['out']
# # or
# unpack to list [(batch, outputs)..] * steps
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
outputs = tf.unpack(tf.transpose(outputs, [1, 0, 2])) # states is the last outputs
else:
outputs = tf.unstack(tf.transpose(outputs, [1,0,2]))
results = tf.matmul(outputs[-1], weights['out']) + biases['out'] # shape = (128, 10)\
return results
pred = RNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
step = 0
while step < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={x: batch_xs,y: batch_ys})
step += 1
if step % 20 == 0:
train_acc=sess.run(accuracy, feed_dict={x: batch_xs,y: batch_ys})
# print(" Iter%d,Train accuracy: %.3f" % (step,train_acc))
test_totalAccuracy=0.0
irange=int(mnist.test.labels.shape[0]/batch_size)
for i in range (irange):
test_batch_xs, test_batch_ys = mnist.test.next_batch(batch_size)
test_batch_xs = test_batch_xs.reshape([batch_size, n_steps, n_inputs])
feeds = {x: test_batch_xs, y: test_batch_ys}
test_acc = sess.run(accuracy, feed_dict=feeds)
test_totalAccuracy+=test_acc
test_totalAccuracy=test_totalAccuracy/(irange)
print(" Iter%d,Train accuracy: %.3f,Test accuracy: %.3f" % (step,train_acc,test_totalAccuracy))
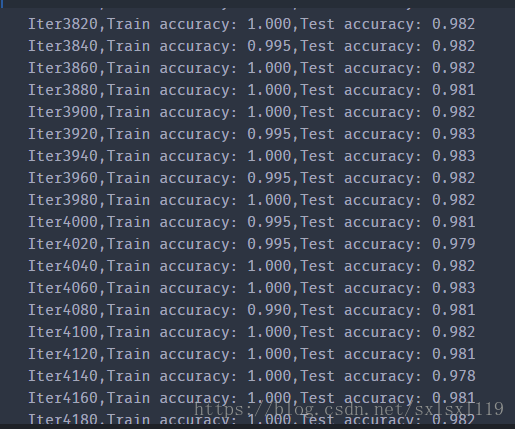
五,运行结果:
六,相关文章
下面这个是个高手啊,写的文章质量都是上层的,有兴趣的可以去看看
https://blog.csdn.net/wangyangzhizhou/article/details/78878909
链接里有的文章:
LSTM神经网络
GRU神经网络
循环神经网络
卷积神经网络
深度学习的seq2seq模型
TensorFlow构建循环神经网络
TensorFlow实现seq2seq
谈谈谷歌word2vec的原理
如何用TensorFlow训练词向量
如何用TensorFlow训练聊天机器人(附github)
TensorFlow训练Logistic回归
TensorFlow训练单特征和多特征的线性回归
深度学习的Attention模型