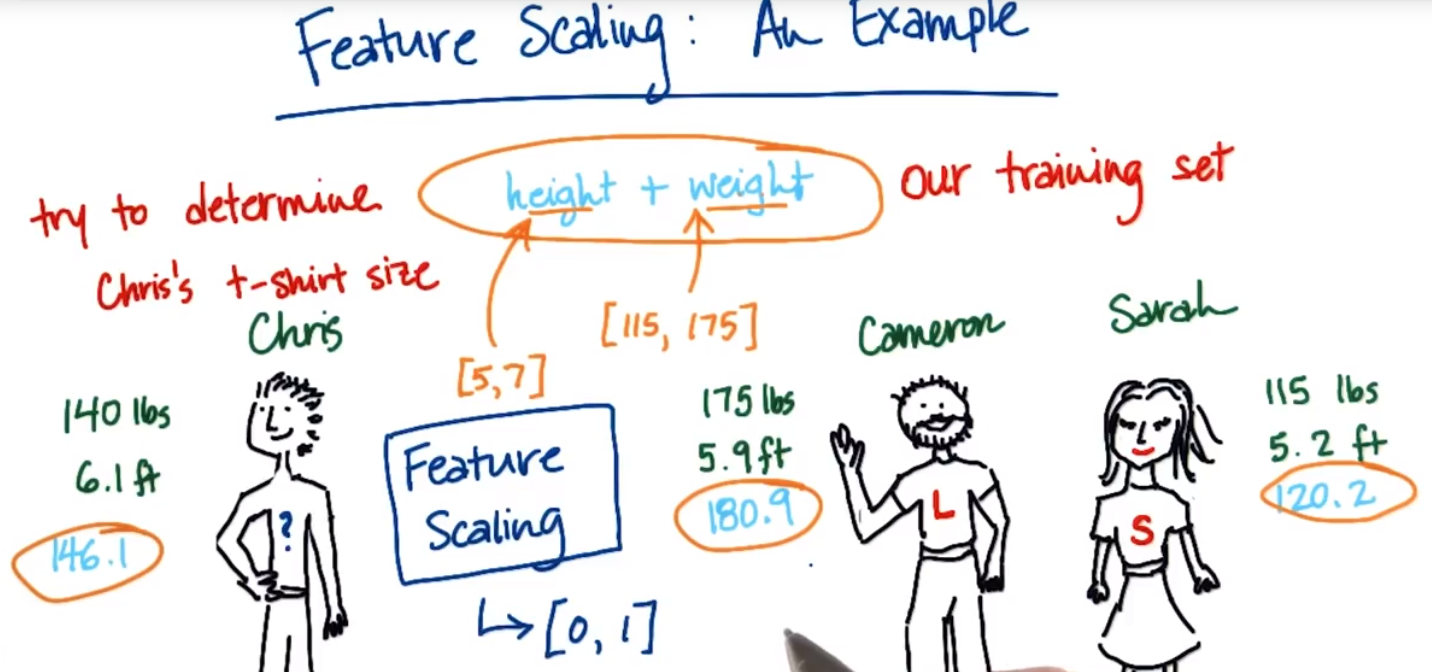
Chirs体重+身高=146.1
Caneron体重+身高=180.9
Serah 体重+身高=120.2
从数据上看Chirs与S数值更接近,应该穿S大小衣服,但是由于体重和身高的度量标准差异(一个是个位数,一个是百位数)导致体重占据了主导位置,此时就用到特征缩放,使这些特征跨越的范围有可比性,通常是在0和1之间(包含0、1)
特征缩放的一个优点是预估输出相对稳定,缺点是当有异常值时,max或min可能会是极端值

通过特征缩放Chirs的体重特征 值缩放为0.417
编写代码计算特征缩放值
def featureScaling(arr):
scaler_list=[]
if max(arr)==min(arr):
for i in range(0,len(arr)):
scaler_list.append(0.5)
return scaler_list
else:
for i in range(0,len(arr)):
scaler =(float)(arr[i]-min(arr)) / ( max(arr)-min(arr))
scaler_list.append(scaler)
return scaler_list
# tests of your feature scaler--line below is input data
data = [115, 140, 175]
print featureScaling(data)
实际上在sklearn中有代码能够实现:
>>>from sklearn.preprocessing import MinMaxScaler
>>>import numpy
>>>weights = numpy.array([[115.],[140.],[175.]])#需要浮点数
>>>scaler = MinMaxScaler()
>>>rescaled_weight = scaler.fit_transform(weights)
array([[0. ],
[0.41666667],
[1. ]])


不会受特征缩放影响的算法:线性回归、决策树
会受到影响的算法:使用RBF核函数的SVM、K-均值聚类
SVM和K-均值聚类在计算距离时,是在利用一个维度与另一个维度进行交换,例如把某一点增加一倍,那么它的值也会扩大一倍
K-means同理

决策树:会呈现出一系列的水平线和垂线,不存在两者的交换,只是在不同的方向上进行切割,在处理某一维度时不需要考虑另一个维度的情况。例如方框缩小一半即特征缩放,图中线条的位置会有所变化,但是分割顺序是一样的.它是按比例分割的,所以两个变量之间不存在交换.

线性回归:每个特征都有一个系数,这个系数总是与相应的特征同时出现,特征A的变化不会影响到特征B的系数(另外如果变量扩大一倍,那它的特征会缩小1/2,其结果不变)
特征缩放迷你项目
1.回顾 K-均值聚类迷你项目最后一部分。分析出我们使用的是哪类缩放。 MinMaxScaler
2.原值为 200,000 的“salary”特征在尺度变换后的值会是什么,以及原值为 100 万美元的“exercised_stock_options”特征在尺度变换后的值会是什么?两个计算方式有误差
普通计算:
100万的“exercised_stock_options”特征缩放值: 0.0290205889347
20万的“salary”特征缩放值: 0.17962406631
MaxMinScaler计算
100万的“exercised_stock_options”特征缩放值:[ 0.02911624]20万的“salary”特征缩放值: [ 0.18005349]
stocklist = []
salarylist = []
for item in data_dict:
stock = data_dict[item]['exercised_stock_options']
salary = data_dict[item]['salary']
if stock != 'NaN':
stocklist.append(stock)
if salary != 'NaN':
salarylist.append(salary)
from sklearn.preprocessing import MinMaxScaler
import numpy as np
salarylist = np.array(salarylist).reshape(-1,1)
stocklist = np.array(stocklist).reshape(-1,1)
#普通方法计算特征缩放
print '100万的“exercised_stock_options”特征缩放值:' ,(1000000.0 - np.min(stocklist))/(np.max(stocklist)-np.min(stocklist))
print '20万的“salary”特征缩放值:',(200000.0 - np.min(salarylist))/(np.max(salarylist)-np.min(salarylist))
min_max_scaler = MinMaxScaler()
min_max_scaler.fit_transform(stocklist)
print 1000000.0 * min_max_scaler.scale_ #原始值*缩放因子
min_max_scaler.fit_transform(salarylist)
print 200000.0 * min_max_scaler.scale_
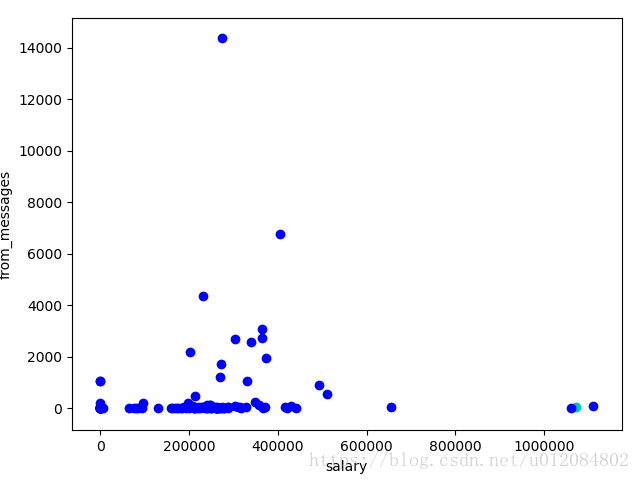
3.如果我们想基于“from_messages”(从一个特定的邮箱帐号发出的电子邮件数)和“salary”来进行集群化会怎样? 在这种情形下,特征缩放是不必要的,还是重要的?
重要。电子邮件的数量通常在几百或几千的人,工资通常至少高出1000倍。