特征缩放
机器学习算法会受到特征缩放的影响?使用 RBF 核函数的 SVM和K-均值聚类
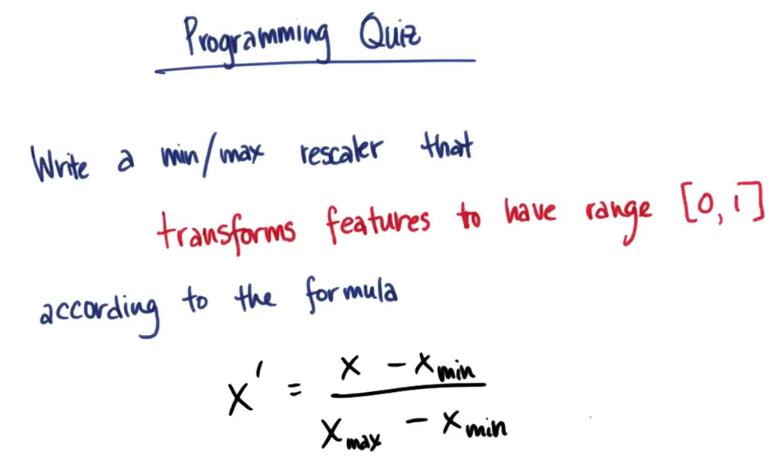
sklearnfrom sklearn.preprocessing import MinMaxScaler import numpy weights = numpy.array([[115.],[140.],[175.]]) scaler = MinMaxScaler() rescaled_weight = scaler.fit_transform(weights) print rescaled_weight
def featureScaling(arr):
import numpy as np
arr = np.array(arr)
max = np.max(arr)
min = np.min(arr)
new=[]
for item in arr:
if max != min :
float (item)
item =float(item-min)/(max-min)
new.append(item)
else:
item=0.5
new.append(item)
return new
data = [115, 140, 175]
print featureScaling(data)
文本学习
##从NLTK中获取停止词
from nltk.corpus import stopwords
sw = stopwords.words('english')
len(sw)
##清除“签名文字”
words = ' '.join(words.split())
##进行 TfIdf
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(stop_words="english") vectorizer.fit_transform(word_data) feature_names = vectorizer.get_feature_names() print len(feature_names) print feature_names[34597]