引言
在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放(feature scaling),比如:在随机梯度下降(stochastic gradient descent)算法中,特征缩放有时能提高算法的收敛速度。下面我会主要介绍一些特征缩放的方法。
什么是特征缩放
特征缩放是用来标准化数据特征的范围。
机器算法为什么要特征缩放
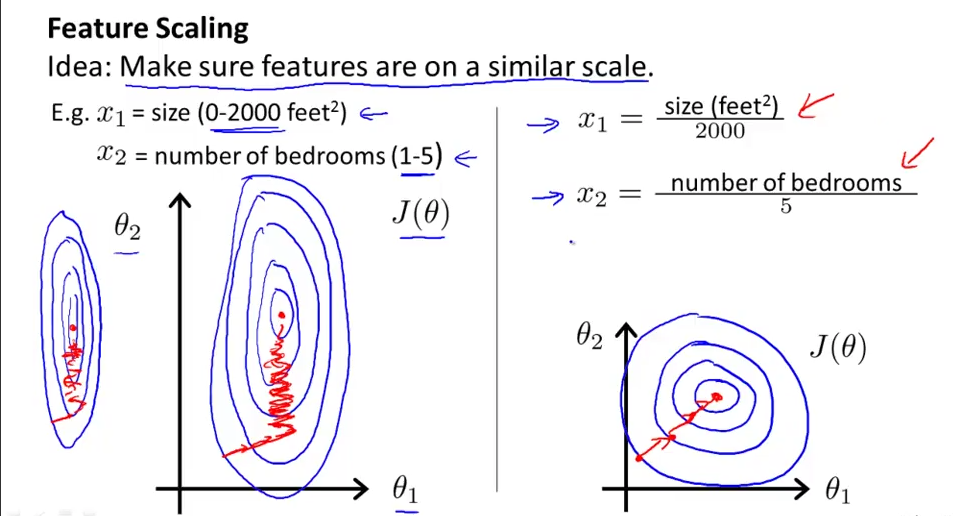
当多个特征的范围差距过大时,代价函数的轮廓图会非常的偏斜,如下图左所示,这会导致梯度下降函数收敛的非常慢。因此需要特征缩放(feature scaling)来解决这个问题,特征缩放的目的是把特征的范围缩放到接近的范围。当把特征的范围缩放到接近的范围,就会使偏斜的不那么严重。通过代价函数执行梯度下降算法时速度回加快,更快的收敛。如下图右所示。
优点:
1. 使机器学习算法工作的更好。比如在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。因此每个特征应该被归一化,比如将取值范围处理为0到1之间。
2. 加快梯度收敛的速度。
特征缩放的一些方法
特征缩放的范围:一般把特征的范围缩放到-1到1,和这接近就行,没必要同一范围。梯度下降就能很好的工作。如下图所示,x1 的范围为0到3,x2的范围为-2到0.5都是可以的。但不能相差的很大,-100到100则是不可以的。
一般的均值归一化公式为: 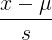 ,其中
,其中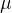 为均值,s为特征的范围,即max-min。也可以用标准差。
为均值,s为特征的范围,即max-min。也可以用标准差。
,其中为均值,s为特征的范围,即max-min。也可以用标准差。
其实归一化主要有两种方法:
- 第一种是min-max标准化(Min-Max Normalization)
它把原始数据映射到[0-1]之间,公式为:
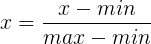
- 第二种是0均值标准化(z-score标准化)
公式为:
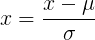
其中,为均值,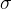 标准差。标准差是方差的开方:
标准差。标准差是方差的开方:
为均值,标准差。标准差是方差的开方:
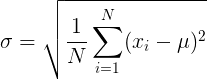
这两种归一化方法的适用场景为:
- 在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围
- 在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
代码(max-min):
def __feature_scaling(self):
max_value = []
min_value = []
for fidx in range(0, self.__FEATURE_CNT):
max_value.append(0)
min_value.append(100)
for idx in range(0, self.__SAMPLE_CNT):
for fidx in range(1, self.__FEATURE_CNT):
if max_value[fidx] < self.__X[idx][fidx]:
max_value[fidx] = self.__X[idx][fidx]
if min_value[fidx] > self.__X[idx][fidx]:
min_value[fidx] = self.__X[idx][fidx]
for idx in range(0, self.__SAMPLE_CNT):
x = self.__X[idx]
for fidx in range(1, self.__FEATURE_CNT):
self.__X[idx][fidx] = (x[fidx] - min_value[fidx]) / (max_value[fidx] - min_value[fidx])