特征缩放
特征缩放(Feature scaling)是一种数据预处理技术,它用于将不同尺度的特征值缩放到相同的范围内,以便更好地应用于机器学习算法中。在不进行特征缩放的情况下,一些特征值可能会因其量级较大而对模型的训练产生更大的影响,导致模型无法充分学习其他特征值的影响。
几种常见的特征缩放方法:
-
标准化(Standardization):通过将每个特征值减去其均值,然后除以其标准差,将特征值缩放为以0为中心、标准差为1的正态分布。
-
归一化(Normalization):通过将每个特征值缩放到0和1之间的范围内,使得所有特征值的范围相同。
-
平均值归一化(Mean normalization):通过将每个特征值缩放到[-1,1]或[0,1]范围内,从而使特征值在[-1,1]或[0,1]之间。
e . g . e.g. e.g. 比如 bedrooms 代表卧室的数量,size in feet 2 ^2 2 代表房间的尺寸。
一般卧室的数量都是个位数十位数,而房间的尺寸却一般都是百位数千位数,所以为了防止房间的尺寸数量级较大从而使得模型无法充分学习卧室个数的情况;
我们有如下三种方法进行特征缩放:
标准化
标准化(Standardization)又称为 Z-score normalization,对于一个特征 x x x,其均值为 μ \mu μ,标准差为 σ \sigma σ,则对于每个样本, x x x 的缩放后的值 y y y 可以通过以下公式计算:
y = x − μ σ y = \frac {x-\mu} \sigma y=σx−μ
通过这种方法缩放后的特征值 y y y 的平均值为0,标准差为1;
例如在上述的房间尺寸与卧室数量的案例中:
300 ≤ x 1 ≤ 2000 ; x 1 , s c a l e d = x 1 − μ 1 σ 1 0 ≤ x 2 ≤ 5 ; x 2 , s c a l e d = x 2 − μ 2 σ 2 300≤x_1≤2000; x_{1,scaled}=\frac {x_1-\mu_1} {\sigma_1} \\ 0≤x_2≤5; x_{2,scaled}=\frac {x_2-\mu_2} {\sigma_2} 300≤x1≤2000;x1,scaled=σ1x1−μ10≤x2≤5;x2,scaled=σ2x2−μ2
import numpy as np
def zscore_normalize_features(X):
mu = np.mean(X, axis=0)
sigma = np.std(X, axis=0)
X_norm = (X - mu) / sigma
return (X_norm, mu, sigma)
通过 Sklearn 实现 Z-Score Normalization
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_norm = scaler.fit_transform(X_train)

归一化
归一化(Normalization)又称为最大值缩放 Max Scaling。具体来说,对于一个特征 x x x,其最大值为 m a x max max,则对于每个样本, x x x 的缩放后的值 y y y 可以通过以下公式计算:
y = x m a x y = \frac x {max} y=maxx
例如在上述的房间尺寸与卧室数量的案例中:
300 ≤ x 1 ≤ 2000 ; x 1 , s c a l e d = x 1 2000 0 ≤ x 2 ≤ 5 ; x 2 , s c a l e d = x 2 5 300≤x_1≤2000; x_{1,scaled}=\frac {x_1} {2000} \\ 0≤x_2≤5; x_{2,scaled}=\frac {x_2} {5} 300≤x1≤2000;x1,scaled=2000x10≤x2≤5;x2,scaled=5x2
def max_normalize_features(X):
x_max = np.max(X)
X_norm = X / x_max
return X_norm

平均值归一化
平均值归一化具体来说,对于一个特征 x x x,其均值为 μ \mu μ,最小值为 m i n min min,最大值为 m a x max max,则对于每个样本, x x x 的缩放后的值 y y y 可以通过以下公式计算:
y = x − μ m a x − m i n y = \frac {x-\mu} {max-min} y=max−minx−μ
例如在上述的房间尺寸与卧室数量的案例中:
300 ≤ x 1 ≤ 2000 ; x 1 , s c a l e d = x 1 − μ 1 2000 − 300 0 ≤ x 2 ≤ 5 ; x 2 , s c a l e d = x 2 − μ 2 5 − 0 300≤x_1≤2000; x_{1,scaled}=\frac {x_1-\mu_1} {2000-300} \\ 0≤x_2≤5; x_{2,scaled}=\frac {x_2-\mu_2} {5-0} 300≤x1≤2000;x1,scaled=2000−300x1−μ10≤x2≤5;x2,scaled=5−0x2−μ2
def mean_normalize_features(X):
mu = np.mean(X, axis=0)
x_max = np.max(X)
x_min = np.min(X)
X_norm = (X - mu) / (m_max - m_min)
return X_norm

收敛
收敛(Convergence)通常指的是训练过程中模型的参数逐渐趋于稳定,不再发生明显变化的情况。当模型的参数收敛时,其对训练数据的拟合误差(training error)也会逐渐降低,直到达到一个较小的阈值或收敛标准。
如下图所示,一般来说,伴随着迭代(iterations),应该呈现下图所示曲线,即损失函数越来越小,直到趋于稳定,不再发生明显变化;
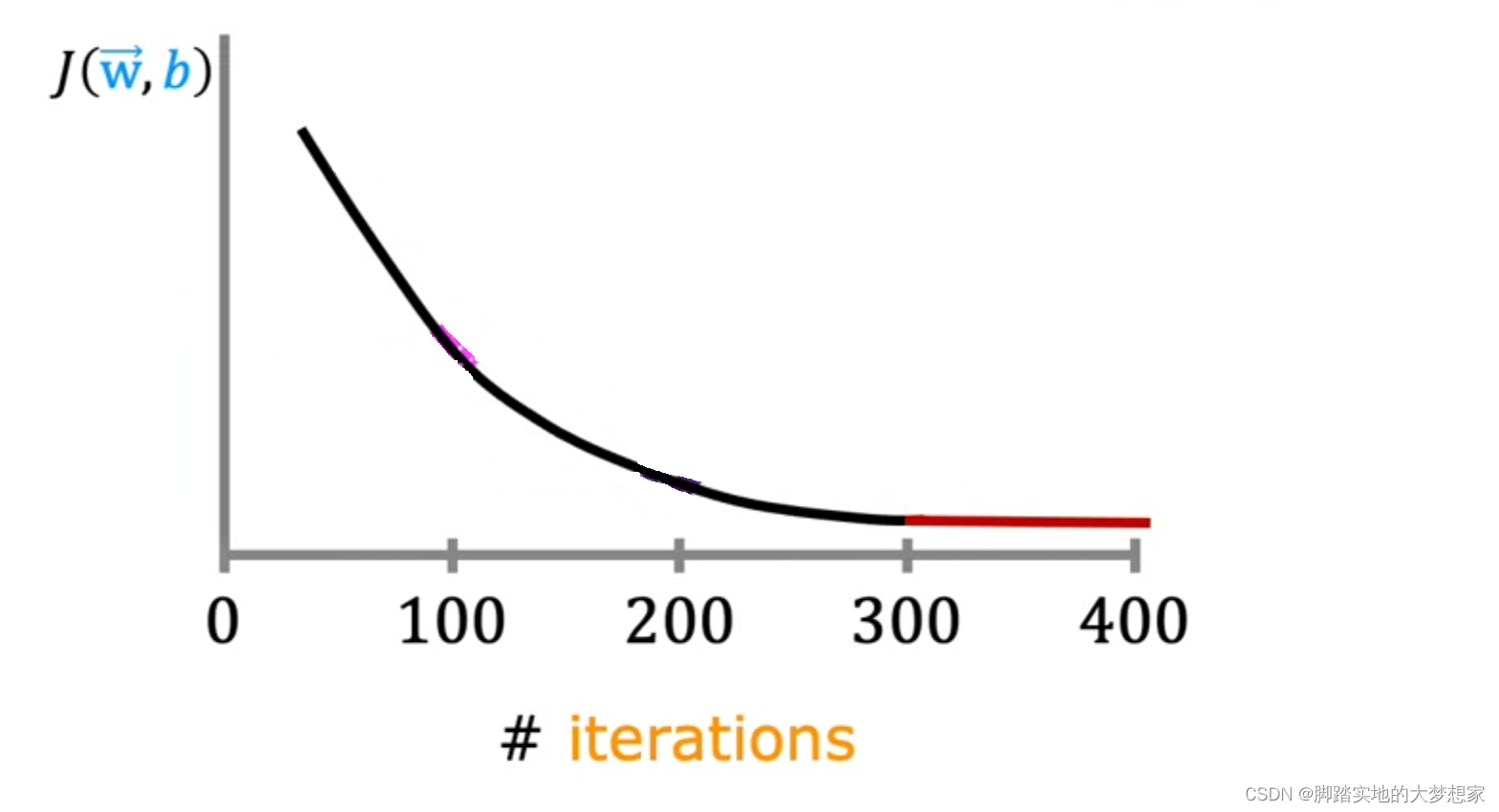
损失函数在迭代100次时,下降的速度还是很快的;
在迭代200次的时候,损失值下降的速度明显变慢;
在迭代300次的时候,每次迭代损失值下降的已经很小很小了;
在迭代400次的时候,几乎看不到变化,趋于稳定,此时我们称之为 converged,即收敛了。
而如果出现损失值变大的情况,则可能是学习率 α \alpha α 设置的有问题,下面我们将学习了解学习率的概念;
学习率
学习率(learning rate)是梯度下降算法中的一个重要超参数,用于控制每一次参数更新的步长大小。在梯度下降算法中,每一次迭代都需要计算损失函数的梯度,然后按照一定的步长沿着梯度方向更新模型参数。
学习率决定了每次更新的步长大小:
如果学习率过大,会导致参数在梯度方向上 “跳跃” 太大而无法收敛;
如果学习率过小,会导致参数更新缓慢,耗费较长的时间才能达到最优解。
学习率的选择是一个经验性的问题,需要根据具体问题和数据集的特征来进行调整。一般来说,可以从较小的学习率(比如 α \alpha α = 0.001)开始,观察损失函数的收敛情况和模型的性能,然后逐步调整学习率的大小,直到达到最佳的性能和收敛速度。
在梯度下降算法中,有三种不同的学习率策略可供选择:
- 固定学习率:使用固定的学习率,不随着迭代次数的增加而改变。
- 动态学习率:根据迭代次数或其他规则来动态调整学习率。
- 自适应学习率:根据梯度的大小来自适应地调整学习率,常见的方法包括Adagrad、Adam等。
对于初学者而言,无需参与到动态学习率 与 自适应学习率的讨论中,尝试固定学习率,以 0.001 与 0.01 多做尝试即可。