前半部分是简介, 后半部分是案例
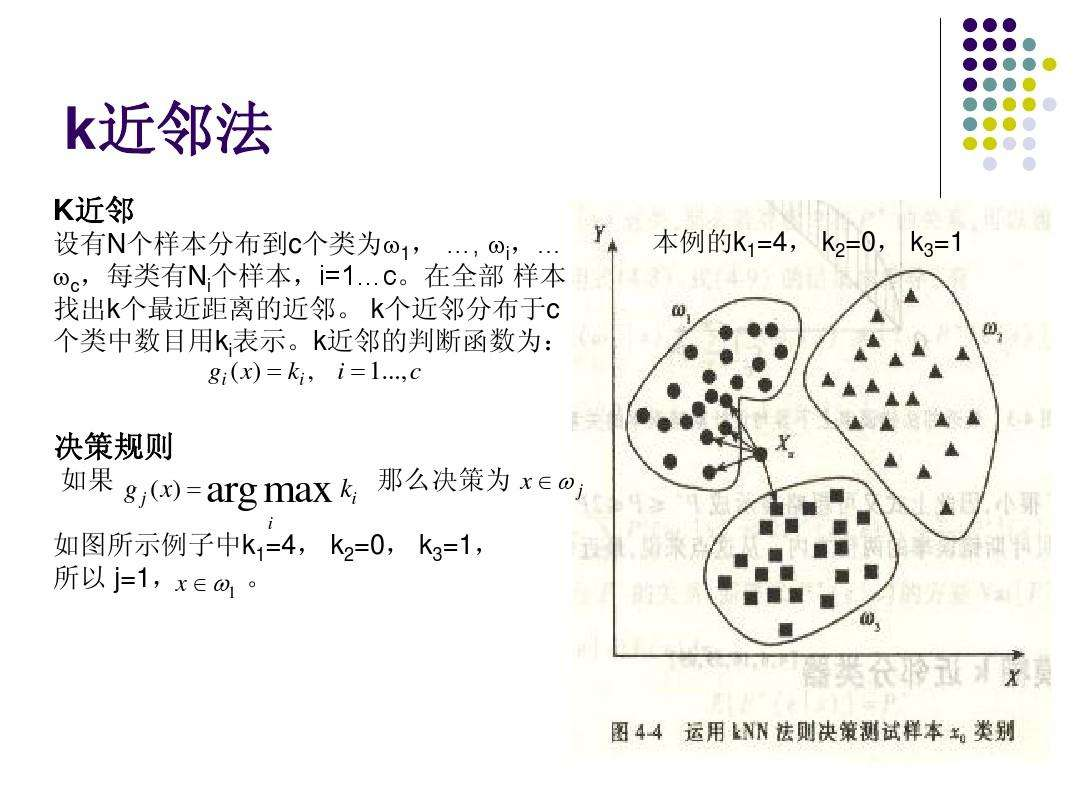
KNN近邻算法:
简单说就是采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)
优点: 精度高、对异常值不敏感、无数据输入假定
缺点:时间复杂度高、空间复杂度高
- 1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。改进方法是对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
- 2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,改进方法是:先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
适用数据范围:
- 标称型(离散型):标称型目标变量的结果只在有限目标集中取值,如真与假(标称型目标变量主要用于分类)
- 数值型:数值型目标变量则可以从无限的数值集合中取值,如0.100,42.001等 (数值型目标变量主要用于回归分析)
工作原理:
- 训练样本集—>存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
- 电影类别KNN分析(图片来源于网络)
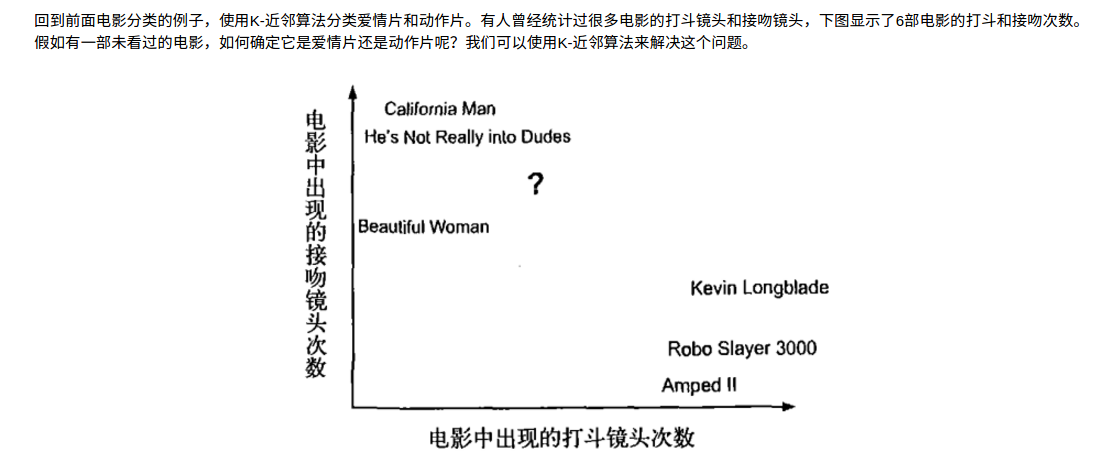

- 欧氏距离(Euclidean Distance,欧几里得度量)

- 计算过程图
- 案例
代码都是在 jupyter notebook 中写的
1 import numpy as np 2 import pandas as pd 3 from pandas import Series,DataFrame 4 import matplotlib.pyplot as plt 5 %matplotlib inline 6 # 以上导入的包都是自己习惯性导入, 因为随时都可能会用到, 就每次先把这些都导入了 7 8 #这儿是我自己写了一个excel表格,方便快速的读取数据, 演示使用, 就不用series或者dataframe写了 9 film = pd.read_excel('films.xlsx',sheet_name=1) 10 #输入film后出现表格 11 fil

1 # 电影的样本特征 2 train=film[['动作镜头','接吻镜头']] 3 # 样本标签,即要预测的标签,这儿要预测新数据是属于什么类别的电影 4 target=film['电影类别'] 5 # 创建机器学习模型,需要导入 6 from sklearn.neighbors import KNeighborsClassifier 7 # 创建对象, 这儿的数据因为是离散型, 所以使用KNeighborsClassifier, 8 knn=KNeighborsClassifier() 9 # 对knn模型进行训练, 传入样本特征 和 样本标签 10 # 构建函数原型、构建损失函数、求损失函数最优解 11 knn.fit(train,target) 12 knn
当输入knn后出现如下代码, 表示训练完成
1 KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', 2 metric_params=None, n_jobs=1, n_neighbors=5, p=2, 3 weights='uniform')
1 # 这儿随意写3个样本数据,需要按照样本数据的维度来写 2 cat=np.array([[5,19],[21,6],[23,24]]) 3 # cat=np.array([[21,4]]) 也可以写1个 4 # 使用predict函数对数据进行预测 5 knn.predict(cat)
运行会出现下图:

预测完成 ! 成功判断出3个新样本的归属类别
接下来也可以绘制图, 直观的查看近邻情况
1 # scatter画出来的是散点图, 取数据使用 .values,二维数组中, 一维全部取出, 二维取0,表示出来就是[:,0] 2 plt.scatter(train.values[:,0],train.values[:,1]) 3 # scatter可以有一些属性, 下边的color可以自定义显示的颜色 4 plt.scatter(cat[:,0],cat[:,1],color='red')
效果图为:
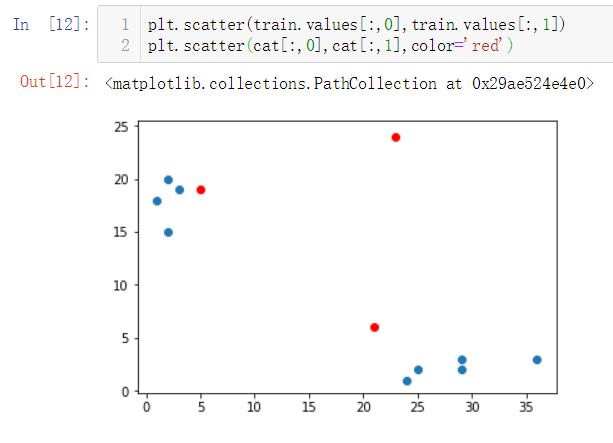
在使用KNN近邻算法时, 注意要分清楚样本集, 样本特征,样本标签
技术交流可以留言评论哦 ! 虚心学习, 不忘初心, 共同奋进 !