k近邻算法(kNN)的基本思想
一、算法流程
对未知类别属性的数据集中的每个点依次执行以下操作:
(1) 计算已知类别数据集中的点与当前点之间的距离;(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的 k 个点;
(4) 确定前 k 个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类。
二、举例说明
以下图为例:已知有两类(蓝色正方形、红色三角形),现有待分类样本(绿色圆形),通过kNN算法,预测其属于哪一类。假定k=4。具体如图1所示。
1、计算绿色圆形到图中所有样本(蓝色正方形、红色三角形)的距离。
2、将计算出来的距离按从小到大的顺序进行排序。
3、从第2步得出的递增序列中选出4个距离最短的样本。
4、这个样本集中有3个红色三角形和1个蓝色正方形。
5、因为红色三角形的出现频率高,因此,运行完该算法后,待分类样本被预测为红色三角形。(若各个种类的个数都相同,则将其归为任意一类皆可。)
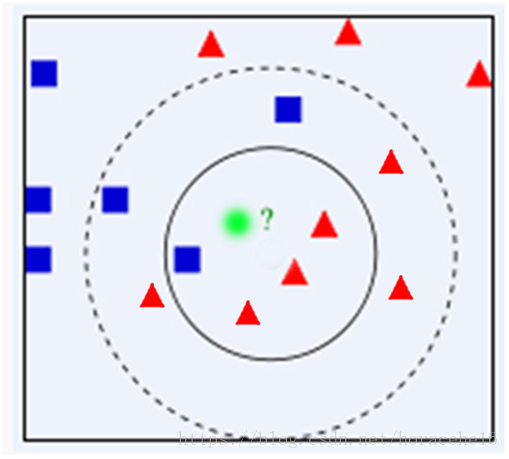
图1 kNN算法原理示意图
扫描二维码关注公众号,回复:
123032 查看本文章

三、算法优点
1、简单。
2、易于理解。
3、容易实现。
4、通过对K的选择可具备丢噪音数据的健壮性。
四、算法缺点
1、 需要大量空间储存所有已知实例。
2、算法复杂度高(需要比较所有已知实例与要分类的实例)。
3、 当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本
五、改进方法
1、考虑距离,根据距离加上权重。 比如: 1/d (d: 距离)。
六、核心代码
# kNN核心算法
'''''
classify0函数:
参数解释:
inX:待分类样本
dataSet:已分类的数据集(训练集)
labels:已分类的数据集的类别
k:选取最近距离的样本个数
功能解释:
通过计算样本inX与dataSet中各个样本的距离,
选出k个距离最近的样本,
挑选在这些样本中出现次数最多的种类,
将该种类预测作inX的种类
'''
def classify0(inX, dataSet, labels, k):
# 读取训练集矩阵中向量(样本)的个数
dataSetSize = dataSet.shape[0]
# 训练集向量(样本)与待分类向量(样本)的差值,类似于(x1-y1)
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
# 类似于(x1-y1)^2
sqDiffMat = diffMat**2
# 类似于 (x1-y1)^2 + (x2-y2)^2 + ... + (xn-yn)^2
sqDistances = sqDiffMat.sum(axis=1)
# 对sqDistances进行开方,得到两个样本的欧式距离
distances = sqDistances**0.5
# 计算出待分类样本与各个已分类样本的距离后,
# 将这些距离从小到大排序,提取其对应的index(索引),输出到sortedDistIndicies
# 例如:第一个样本与待分类样本的距离在所有距离中排第706名,那么将706记录到sortedDistIndicies列表中
sortedDistIndicies = distances.argsort()
classCount = {}
# 取出k个距离最近的样本。选出在这些样本中出现次数最多的种类,那么该种类就为预测结果
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
附:
具体实战代码请跳转至:
https://blog.csdn.net/horacehe16/article/details/80184583
谢谢大家!你们的支持将会是我最大的动力!