K近邻(K Nearest Neighbor,KNN),可以做分类,也可以做回归。
一、基本思想
给定一组训练集,有一个需要判断类别的输入实例,离输入实例最近的K个训练数据属于哪个类别,就判断输入实例属于哪个类别。
二、分类算法描述:
1、计算输入实例和所有训练集数据的距离;
2、按距离升序排序;
3、选择排序后的前K个训练子集数据;
4、根据选择出来的K个训练子集数据的类别,使用判别规则(一般是多数投票),预测输入实例的类别。
这样实现也叫蛮力算法,适合样本量少的时候使用。
三、影响因素:
根据以上描述,我们可以归纳影响KNN的主要因素:1、距离的度量 2、K值 3、判别规则。下面具体说下这3个因素是怎么影响KNN的。
- 距离的度量
计算2个n维数据点的距离公式,闵可夫斯基距离是最一般的形式:
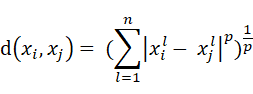
其中,l 是数据点的特征,因为数据点是n维的,所以l 能从1取到n,数据点xi和 xj 之间的距离就等于,xi 和 xj 每个特征相减的绝对值的p次方,求和后开 p次根号。
一般,p 取1、2、∞。
P = 1,叫曼哈顿距离。
P = 2,叫欧式距离。
P = ∞,切比雪夫距离,注意一点的是这个距离的含义,他表示特征差的最大值,不再是所有特征差,只取最大的那个。至于为什么是这样,我还没搞懂。
当然还有更多的求距离的公式,以后学了再添加。
值域变化大的特征会对距离产生较大的影响,因此为了避免这种情况,需要对训练数据做归一化,缩小特征的值域范围。
- K值
K值过小过大都不好。
K值过小,邻域小,预测结果对邻域里的训练数据非常敏感,容易造成过拟合。
K值过大,邻域大,距离远的训练数据也会对预测结果产生影响,极端值会影响预测结果。
如何选择合适的K值呢?通常使用交叉验证。这个我还没有深入了解。
- 决策规则
目前只见过一种投票,也叫多数表决。表达式:
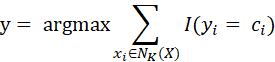
这个表达式含义:邻域中类别最多的类。或者是:
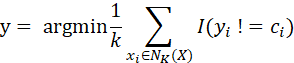
含义:邻域中不等于类别的最小占比,也叫损失,找最小损失。
上面2个表达式归根到底是一个意思,就是找邻域中类别最多的类别,该类别就是预测的结果。前面考虑的是距离近和距离远的点对预测结果产生一样的影响,我们想想,距离近和远应该是一样的影响程度吗?肯定不一样。那怎么合理解决呢?用加权投票,给距离近的点更大的权重,距离远的点更小的权重,这样预测的结果会更合理一些。
用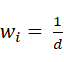 做加权,距离加权表决表达为:
做加权,距离加权表决表达为:

四、优缺点
到这里,归纳下KNN的优缺点:
优点:思想简单,理论成熟,既可以用来做分类又可以用来做回归,
准确度高,对数据没有假设,对离群值不敏感,
缺点:计算量大,需要大量内存,
样本不平衡问题(有些类别样本特别多,有些类别样本很少)
五、KD树
KNN没有显式模型,每一次预测都要用训练数据计算一遍,如果训练数据体量大的话,会比较慢。一种优化效率的方法,是把训练数据保存成KD树。
1、KD树的构建
根节点用方差最大的特征。找到特征的中位数,小于中位数的划入左子树,大于中位数的划入右子树,对于左右子树,再选取方差最大的特征当作节点,递归产生KD子树。划分出来的形状是超矩形。
2、KD树的搜索
首先找到包含目标点的叶子结点,以目标点到叶子结点的距离为半径,作超球体,最邻点一定在这个超球体内。然后返回父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交,就到这个子节点寻找是否有最邻点,有的话更新最邻点。如果不相交,就返回父节点的父节点,在另一个子树里搜索最邻点。当回到根节点时,算法结束,此时最邻点就是最终的最邻点。
- KD树预测
搜索到第一个最近邻,然后依次剩余K-1个最近邻(已选的数据点要删除不能再选)。如果是分类,就用投票法选择类别,如果是回归,就用平均值作为预测结果。
六、优化
分组快速搜索近邻法
把训练集按近邻关系分成组,给出每组质心的位置,以质心作为代表点,计算和输入实例的距离,选出距离最近的一个或若干个组,再在组内应用KNN。由于并不是计算输入实例与所有训练集数据的距离,故该改进算法可以减少计算量,但并不能减少存储量。
