分布式系统
a) 基本术语
- i. 进程与线程:不再赘述
- ii. 并发:系统只有1个CPU,单位时间内对于资源的访问;
- iii. 锁:用于保护临界区,应用于多线程中。
- 避免锁争用的几种策略:分拆锁、分离锁、避免共享变量缓存、使用并发容器如Amino、使用Immutable数据和ThreadLocal数据;
- ConcurrentHashMap的实现使用了包含16个锁的数组,每一个锁都守护HashMap的1/16。这是分拆锁和分离锁的应用,感兴趣可以详细看下。
- iv. 并行:1个以上的CPU,多个线程不抢CPU资源,可以同时执行,叫并行。
- v. 集群:一组相互独立、通过告诉网络互联的计算机,再以单一模式来管理。
- vi. 状态特性:提倡服务无状态,分布式环境中的人和街店(Node)也是无状态的。无状态指不保存存储状态,可以随意重启和替代,便于扩展。
- vii. 系统重发和幂等性:
- viii. 硬件异常:
b) 理论
- i. CAP原则:一致性(C)、可用性(A),、分区容忍性(P);
- ii. 最终一致性:由于CAP存在“二选一”(伪命题),所以提出了最终一致性。就是给定足够长的时间,不断发送更新,就认为所有更新会最终传播到整个系统,所有副本都会达到一致。
- iii. Paxos算法:一致性算法。较复杂,暂时跳过;
- iv. 2PC:2阶段提交协议,典型的原子提交协议,暂时跳过;
- v. 3PC:3阶段提交协议,2PC的升级,跳过;
- vi. Raft:一致性算法,有个动画讲解的很生动,抽空补上链接;
- vii. Lease机制:租期,理解为服务器将数据分发给节点时,同事会给数据附加上有效期,在有效期内节点不能修改数据,过期之后节点会删除数据,但是server会等到所有的lease已经超时才会更新数据并发出新的lease。
- viii. 解决“脑裂”问题:引起问题的原因是心跳检测做主备切换的时候,存在不确定性,导致了一个完整的系统分裂成两个独立的节点,两个节点争抢资源,发生异常。可以通过设置仲裁机制(设置第三方检测服务器)。
c) 设计策略
主要有几个问题是分布式系统普遍关心的,称之为设计策略:
- 1.如何检测你还活着?
- 心跳检测
server收到心跳可以确认节点正常,收不到心跳却不能确认该节点“死亡”。一般有两类具体做法:周期检测心跳机制、累计失效检测机制。判断为死亡的节点就可以踢出集群。
- 心跳检测
- 2.如何保证高可用?
- 主备模式
主机宕机时,备机接管主机的一切工作。主机恢复后,可以自动(热备)或手动(冷备)切换回主机。 - 互备模式
两台主机同时运行各自的服务,相互检测情况。两个主机需要通过同步来保障一致性。 - 集群模式
指多个节点在运行,通过主控节点分担服务请求,比如zookeeper。
- 主备模式
- 3.容错处理
- 容错性
确切的说是容故障,并非容错误。
- 容错性
- 重试机制
不能频繁的查询DB,流量大时,DB可能会挂掉。可以给缓存设置默认值,根据实际情况来轮询请求缓存,把请求挡在缓存中。 - 4.负载均衡
使用多台集群服务器共同分担计算任务,把请求和计算分配到集群中可用服务器上。
以Nginx为例,负载均衡有以下几种策略:
- 轮询
根据Nginx配置文件中的顺序,依次把请求分发到不同的服务器上。 - 最少连接
当前谁连接最少,将请求分发给谁。 - IP地址哈希
同一IP转发给同一服务器,方便session保持。(可延伸出如何解决session一致性的问题) - 基于权重的负载均衡
将请求较多的分发到高配置的服务器上,请求较少的分发到低配服务器上。
- 轮询
Redis探秘
key-value存储系统,使用C语言编写,遵守BSD协议(五大开源协议之一)。
a) 数据结构
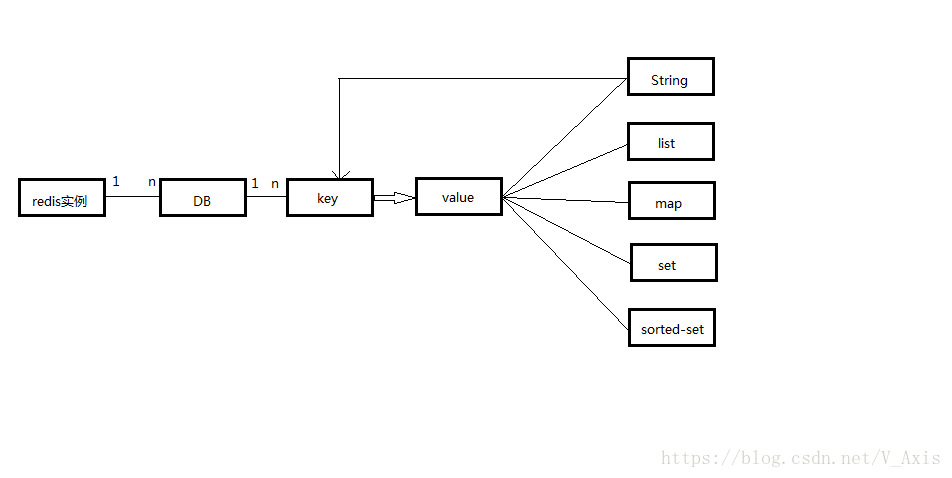
Redis没有传统意义上的table模型,schema对应的db以编号区分。
在同一个db内部,key是顶层模型(即db本身就是key值的命名空间),值是扁平化的。实际使用时,将命名空间和业务key连接(用“:”作为分隔符),例如”artice:12345”,意思是在artice这个命名空间下id为12345元素的key。
这种设计,针对key的操作就很简单了。下面分别介绍下他们的模型和实现。
- String
能表达3种值的类型:
- 字符串;
- 整数;
- 浮点数。
三种类型是根据具体场景有redis完成相互间的自动转型。String类型value还具备简单的Compare-And-Set原子类操作,根据判断给定的key是否存在设置value值。
- list
列表对象,用于存储String序列。value对象内部以lingedlist或ziplist承载,当list的元素较少和单个元素长度较小时会采用ziplist实现,目的是减少内存使用,否则采用linkedlist。 - map
和Java一样来理解语义:包含若干key-value,其中key不重复。map用hashtable和ziplist两种承载方式实现。数据量较小时,采用ziplist实现。 - set
set类似list,但是他是一个无序集合,元素不重复。 - sorted-set
类似于map,但他是一个有序的key-value值。