前面几节已经介绍了memcached的内存结构以及删除策略,这一节主要来讲讲memcached分布式的实现,由于memcached在服务端并不支持分布式的实现。因此,memcached的分布式的实现完全是由客户端是实现的。
一、分布式是什么
简单的来说分布式就是为了提高系统的性能,将系统的各个组件分布在不同的服务器上,各组件通过网络通信来进行数据的交换,进而协调工作。
通过下面这个例子来解释分布式的概念。
这里假设我们目前有三台memcached服务器,我们的客户端程序需要保存键为 “apple” 、“orange”、“banana”的数据。
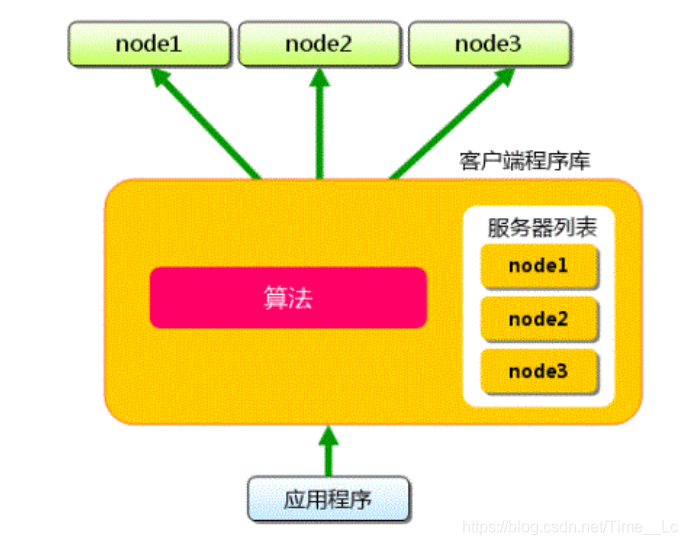
这里我们假设我们要保存键为 apple的这个数据,首先客户端会根据其算法(一般有hash算法等)来决定将这个数据存到那个memcached缓存服务器。其他的键也是遵循相同的方法,同样在取值的时候,也会先选定相应的服务器,在进行取值。
通过以上这种方式就实现了memcached的分布式,当memcached缓存服务其增多之后,缓存的数据就会比较分散,当一台缓存服务器不可用时,也不会影响其他的缓存服务器。
二、分布式算法
1. 取余分布式算法
这里来介绍一种分布式的算法,算法的思想比较简单,就是根据服务器的台数进行取余来选择服务器。但是,应该对什么取余呢? 因为我们通常是根据键来查询的,因此,我们应该利用键来进行取余。一般来说我们的键都不会是一个数值,这里我们很容易就能想到通过给键使用hash算法,来获得一个数值,然后通过对这个数值进行取余就可以选择相应的服务器。
这种思想简单而且也容易实现,但是有一个非常重要的缺点,就是当随着业务的增加,我们需要增加一台缓存服务器时,可能会耗费很大的代价。因为之前取余操作都不在准确,出现大量缓存不命中的情况。
这里可以通过在一台服务器上添加多个memcached实例来解决,即采用逻辑库的方式实现,当需要扩展时,只需要将相应的物理库拆分成和逻辑库相同的数量。
当然,还有其他的分布式算法,感兴趣的话,可以自己再去研究研究。
总结:至此,关于Memcached内容就学习结束了,目前由于memcached不支持序列化,数据结构比较单一,组件被其他缓存软件替代,如:redis等等。
