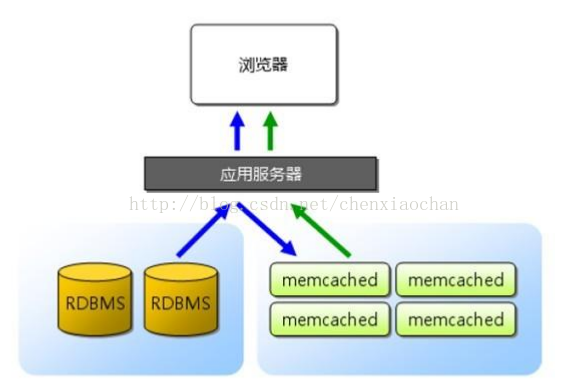
高并发环境下,大量的读写请求涌向数据库,磁盘的处理速度与内存显然不在一个量级,从减轻数据库的压力和提高系统响应速度两个角度来考虑,一般都会在数据库之前加一层缓存。由于单台机器的内存资源以及承载能力有限,并且,如果大量使用本地缓存,也会使相同的数据被不同的节点存储多份,对内存资源造成较大的浪费,因此,才催生出了分布式缓存。
Memcache
memcache是一款开源的高性能的分布式内存对象缓存系统,用于在应用中减少对数据库的访问,提高应用的访问速度,并降低数据库的负载。为了在内存中提供数据的高速查找能力,memcache使用key-value的形式存储和访问数据,在内存中维护一张巨大的HashTable,使得对数据查询的时间复杂度降低到O(1),保证了对数据的高性能访问。内存的空间总是有限的,当内存没有更多的空间来存储新的数据时,memcache就会使用LRU(LeastRecently Used)算法,将最近不常访问的数据淘汰掉,以腾出空间来存放新的数据。
memcache存储支持的数据格式也是灵活多样的,通过对象的序列化机制,可以将更高层抽象的对象转
换成为二进制数据,存储在缓存服务器中,当前端应用需要时,又可以通过二进制内容反序列化,将
数据还原成原有对象。
缓存的分布式架构
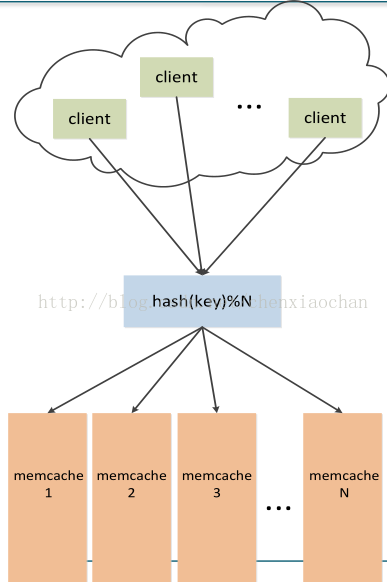
memcache本身并不是一种分布式的缓存系统,它的分布式,是由访问它的客户端来实现的。一种比较简单的实现方式是根据缓存的key来进行hash,当后端有N台缓存服务器时,访问的服务器为hash(key)%N,这样可以将前端的请求均衡的映射到后端的缓存服务器,如图所示,但是,这样也会导致一个问题,一旦后端某台缓存服务器宕机,或者是由于集群压力过大,需要新增新的缓存服务器,大部分的key将会重新分布,对于高并发系统来说,这可能会演变成一场灾难,所有的请求将如洪水般疯狂的涌向后端的数据库服务器,而数据库服务器的不可用,将会导致整个应用的不可用,形成所谓的“雪崩效应”
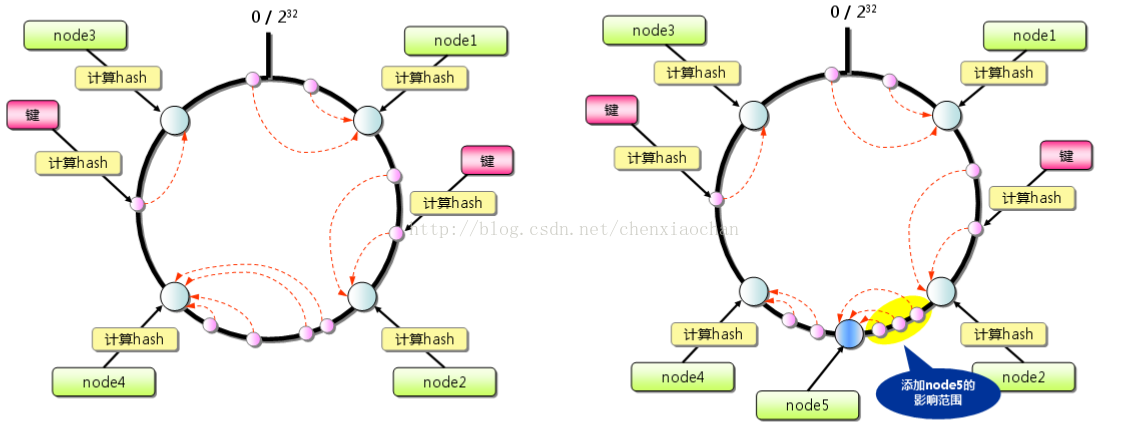
一致性hash算法
consistenthash算法能够在一定程度上改善缓存的雪崩问题,它能够在移除/添加一台缓
存服务器时,尽可能小的改变已存在的key映射关系,避免大量key的重新映射。
分布式session
传统的应用服务器,如tomcat、jboss等等,其自身所实现的session管理大部分都是基于单机的,对于大型分布式网站来说,支撑其业务的远远不止是一台服务器,而是一个分布式集群,请求在不同服务器之间跳转,需要保持服务器之间的session同步。传统网站一般通过将一部分数据存储在cookie中,来规避分布式环境下session的操作,这样做弊端很多,一方面cookie的安全性一直广为诟病,并且,cookie存储数据的大小是有限制的,随着移动互联网的发展,很多情况下还得兼顾移动端的session需求,使得采用cookie来进行session同步的方式弊端更为凸显。分布式session正是在这种情况下应运而生的。
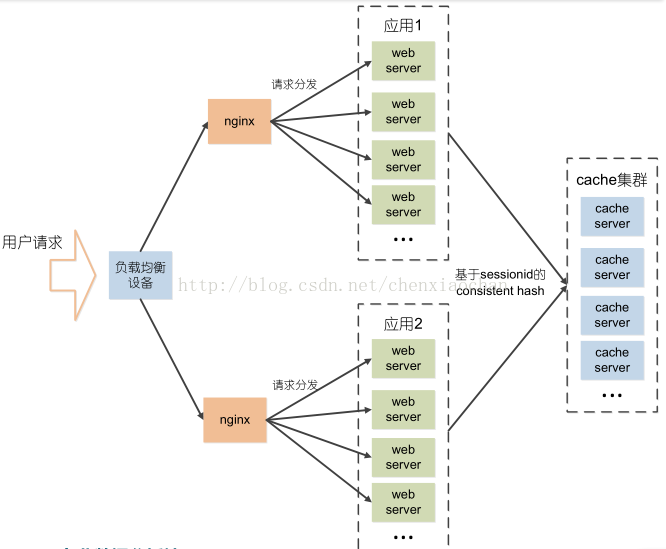
一种分布式session解决方案
前端用户请求经过随机分发之后,可能会命中后端任意的webserver,并且,webserver也可能会因为各种不确定的原因宕机,这种情况下,session是很难在集群间同步的,而通过将session以sessionid作为key,保存到后端的缓存集群中,使得不管请求如何分配,即便是webserver宕机,也不会影响其他的web server通过sessionid从cacheserver中获得session,这样,即实现了集群间的session同步,又提高了webserver的容错性。
缓存的容灾
业务强依赖缓存,缓存需做到容灾:
1.双机房相互备份
2.数据复制多份,单台缓存失效,集群间能够自动复制和备份
3.数据库留有余量
4.万兆网卡