这个月开始练习《机器学习实战》,原书比较久远了,且代码和练习都是基于Python2,我个人是升级到了Python3,因此使用最新的版本来写这些习题。具体2和3其实在基础语法上并没有太多差别,一些高级特性比如装饰器工厂,协程,IO等Python3的新用法,一般机器学习也用不上,因为追求性能的话都会用C/C++等语言去实现,Python只是小规模的测试用。
课程数据和代码也放在我的Github:Machine learning in Action,目前刚开始做,有不对的欢迎指正,也欢迎大家star。除了 版本差异,代码里的部分函数以及代码范式也和原书不一样(因为作者的代码实在让人看的别扭,我改过后看起来舒服多了)。在这个系列之后,我还会写一个scikit-learn机器学习系列,因为在实现了源码之后,带大家看看SKT框架如何使用也是非常重要的。
什么是K-近邻算法?
简单地说,k-近邻算法采用测量不同特征值之间距离的方法进行分类。不恰当但是形象地可以表述为近朱者赤,近墨者黑。它有如下特点:
- 优点:精度高、对异常值不敏感、无数据输入假定
- 缺点:计算复杂度高、空间复杂度高
- 适用数据范围:数值型和标称型
K-近邻算法的工作原理:
存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后算法提取样本中特征最相似的数据(最邻近)的分类标签。一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K近邻算法中K的出处,通常是不大于 20 的整数。最后,选择K个最相似数据中出现次数最多的类别,作为新数据的分类。
我们想使用K近邻算法来分来爱情片和动作片。有人曾统计过很多电影的打斗镜头和接吻镜头,下图显示了 6 部电影的打斗镜头和接吻镜头数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?(当然了,我们这里不考虑爱情动作片)我们可以使用 kNN(k-nearest neighbors algorithm) 来解决这个问题。
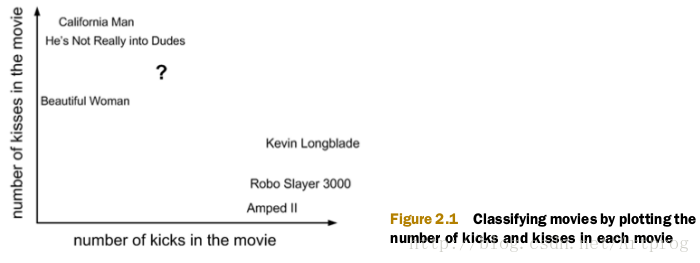
首先我们需要知道这个未知电影中存在多少个打斗镜头和接吻镜头,上图中问号的位置是该位置电影出现的镜头数的图形化展示,具体数字如下表所示:
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| California Man | 3 | 104 | 爱情片 |
| He’s Not Really into Dudes | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先要计算未知电影与样本集中其他电影的距离,计算方法很简单,即欧式空间距离(Euclidean Distance),结果如下表所示。

| 电影名称 | 与未知电影的距离 |
|---|---|
| California Man | 20.5 |
| He’s Not Really into Dudes | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到K=3个,则三个最靠近的电影是 He’s Not Really into Dudes、Beautiful Woman 和 California Man。K-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
2.2 K-近邻算法的一般流程
- 搜集数据:可以使用任何方法。
- 准备数据:距离计算所需要的值,最好是结构化的数据。
- 分析数据:可以使用任何方法。
- 训练算法:此步骤不适用于kk-近邻算法。
- 测试算法:计算错误率。
- 使用算法:首先需要输入样本数据和待分类数据,然后运行kk-近邻算法判定待分类数据分别属于哪个分类,最后应用计算出的分类执行后续的处理。
测试数据
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 2 20:53:12 2018
@author: Administrator
"""
import operator
import matplotlib
from numpy import *
import matplotlib.pyplot as plt
from os import listdir
'''创建一个训练数据集'''
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
'''书上的测试函数没有参数,是自适应函数
此处传入分割参数以及测试集,可以修改测试数值(使用书上的0.1作为分割率)
'''
def Test_accuray(split_ratio, test_set, test_label):
norm_test, ranges, Min = Norm_feature(test_set)
rows = norm_test.shape[0]
rows_test = int(rows * split_ratio)
error = 0
for i in range(rows_test):
Result = classify_KNN(norm_test[i,:], norm_test[rows_test:rows], \
test_label[rows_test:rows], 3)
# 参数1表示从测试集(此处约会数据是随机的因此抽取前10%即可)中抽取一个实例
# 参数2,3,4使用后90%作为训练数据,为输入的实例进行投票并分类,K=3
print("the classifier came with: %d, the real answer is :%d " \
% (Result, test_label[i]))
if(Result != test_label[i]) : error += 1
# print(type(error)) #for test
print("the accuracy is %f | the error_rate is %f " % \
(1- (float(error) /float(rows_test)),(float(error) /float(rows_test))))解析约会网站数据,可视化
#matplotlib.use('TkAgg')
#解析约会数据文件,并将数据导入一个numpy矩阵
def file_parse_matrix(filename):
with open(filename) as fp:
Arr_lines = fp.readlines()
number = len(Arr_lines)
#初始化数据为m行3列(飞行里程,游戏时间,冰淇淋数)
#标签单独创建一个向量保存
return_mat = zeros((number, 3))
label_vec = []
index = 0
for line in Arr_lines:
line = line.strip()
listFromLine = line.split('\t') #按换行符分割数据
#将文本数据前三行存入数据矩阵,第四行存入标签向量
return_mat[index,:] = listFromLine[0:3]
label_vec.append(int(listFromLine[3]))
index += 1
return return_mat, label_vec
KNN分类器
def classify_KNN(test_X, train_set, labels, K):
rows = train_set.shape[0]
diff = tile(test_X, (rows, 1)) - train_set
# 这一行利用tile函数将输入样本实例转化为与训练集同尺寸的矩阵
# 便之后的矩阵减法运算
sqDistance = (diff ** 2).sum(axis=1)
Distance = sqDistance ** 0.5
sorted_Distance = Distance.argsort()
# 对每个训练样本与输入的测试样本求欧几里得距离,即点之间的范数
# 随后按距离由小到大进行排序
classCount = {}
for i in range(K):
vote_label = labels[sorted_Distance[i]]
classCount[vote_label] = classCount.get(vote_label, 0) + 1
#记录距离最小的前K个类,并存放入列表。KEY对应标签,VALUE对应计数
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]特征归一化、标准化
def Norm_feature(data_set):
minVal = data_set.min(0)
maxVal = data_set.max(0)
ranges = maxVal - minVal # 计算极差
# 下一步将初始化一个与原始数据矩阵同尺寸的矩阵
# 利用tile函数实现扩充向量,并进行元素间的对位运算
norm_set = zeros(shape(data_set))
rows = data_set.shape[0]
norm_set = (data_set - tile(minVal, (rows, 1))) / tile(ranges, (rows,1))
return norm_set, ranges, minVal
# 返回极差与最小值留待后续备用手写数字识别
def img2vec(filename):
'''this is to...将32X32的图像转化为1X1024的行向量'''
returnvec = zeros((1,1024))
with open(filename) as fp:
for i in range(32):
line = fp.readline()
for j in range(32):
returnvec[0, 32*i + j] = int(line[j])
# returnVEC按32进位,j代表每位的32个元素
return returnvec
def HandWritingTest(train_dir,test_dir):
labels = []
File_list = listdir(train_dir)
# 将目录内的文件按名字放入列表,使用函数解析为数字
m = len(File_list)
train_mat = zeros((m,1024))
for i in range(m):
fname = File_list[i]
fstr = fname.split('.')[0]
fnumber = int(fstr.split('_')[0])
# 比如'digits/testDigits/0_13.txt',被拆分为0,13,txt
# 此处0即为标签数字
labels.append(fnumber)
train_mat[i,:] = img2vec('%s/%s' % (train_dir,fname))
# labels is label_vec,同之前的KNN代码相同,存储标签
test_File_list = listdir(test_dir)
error = 0.0
test_m = len(test_File_list)
for i in range(test_m):
fname = test_File_list[i]
fstr = fname.split('.')[0]
fnumber = int(fstr.split('_')[0])
vec_test = img2vec('digits/testDigits/%s' % fname)
Result = classify_KNN(vec_test, train_mat, labels, 3)
print("the classifier came with: %d, the real answer is :%d " \
% (Result, fnumber))
if(Result != fnumber) : error += 1
# 这部分和Test模块相同,直接copy过来就好
print("the accuracy is %f | the error_rate is %f " % \
(1- (float(error) /float(test_m)),(float(error) /float(test_m))))Main函数
if __name__ == '__main__':
# 测试数据
group, labels = createDataSet()
classify_KNN([0,0], group, labels, 3)
DataMat, LabelMat = file_parse_matrix('datingTestSet2.txt')
print(DataMat,shape(DataMat),LabelMat)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(DataMat[:,1],DataMat[:,2])
plt.show()
dating_mat, label_mat = file_parse_matrix('datingTestSet2.txt')
data_normed, ranges, minV = Norm_feature(dating_mat)
Test_accuray(0.1, dating_mat, label_mat)
testVec = img2vec('digits/testDigits/0_13.txt')
print(testVec)
# HandWritingTest('digits/trainingDigits', 'digits/testDigits/')
# 这行代码耗时比较久,可以单独测试测试输出
[[4.0920000e+04 8.3269760e+00 9.5395200e-01]
[1.4488000e+04 7.1534690e+00 1.6739040e+00]
[2.6052000e+04 1.4418710e+00 8.0512400e-01]
...
[2.6575000e+04 1.0650102e+01 8.6662700e-01]
[4.8111000e+04 9.1345280e+00 7.2804500e-01]
[4.3757000e+04 7.8826010e+00 1.3324460e+00]]
(1000, 3) 
[3, 2, 3, 2, 3,... 1, 2, 3, 2, 2, 1]
the classifier came with: 3, the real answer is :3
the classifier came with: 2, the real answer is :2
the classifier came with: 1, the real answer is :1
the classifier came with: 1, the real answer is :1
the classifier came with: 1, the real answer is :1
...
the classifier came with: 3, the real answer is :3
the classifier came with: 3, the real answer is :3
the classifier came with: 2, the real answer is :2
the classifier came with: 1, the real answer is :1
the classifier came with: 3, the real answer is :1
the accuracy is 0.950000 | the error_rate is 0.050000
[[0. 0. 0. ... 0. 0. 0.]]总结
kNN算法简单而且准确率高,但是最大的缺点就是既占空间速度又慢。例如上面的手写数字识别系统只是 0-9 十个数字,测试向量就占用了大约 2MB 的空间。而且计算复杂度高,算法要为每个测试向量执行 2000 次距离计算,每次距离计算又包括了 900 次 1024 个维度的浮点运算。除此之外,每次距离计算还需要进行排序等耗时的工作。所以 kNN 的缺点很大。应该算是一种比较不实用的算法,但优点是结果准确。kNN 算法的另一个缺陷是无法给出任何数据的基础结构信息。而决策树能够解决这个问题,并且速度很快。
PS. 根据我的测试,K选3,分割率选0.0725的时候错误率最低,只有0.01